Clear Sky Science · pl
Metoda wielopoziomowej selekcji alarmów bezpieczeństwa sieciowego oparta na algorytmie DBSCAN i wnioskowaniu regułami Rete
Dlaczego inteligentniejsze alarmy mają znaczenie
Współczesne organizacje — od szpitali i banków po dostawców chmury i infrastrukturę miejską — polegają na sieciach, które nigdy nie śpią. Te sieci są monitorowane przez narzędzia bezpieczeństwa, które generują tysiące alarmów dziennie — znacznie więcej, niż analitycy mogą realnie przejrzeć. W tym zalewie kryje się kilka alarmów sygnalizujących rzeczywiste włamania lub poważne luki. W artykule przedstawiono nowe podejście umożliwiające oddzielenie tych kluczowych sygnałów od szumu, redukując fałszywe alarmy przy jednoczesnym wychwyceniu większej liczby prawdziwych ataków, i to przy bardzo niskim zużyciu zasobów obliczeniowych.
Od nieuporządkowanych logów do czystych, użytecznych danych
Alarmy sieciowe pochodzą z wielu urządzeń i dostawców, każdy w swoim formacie i o różnym stopniu szczegółowości. Autorzy najpierw radzą sobie z tym chaosem poprzez staranną fazę oczyszczania i ujednolicania. Wszystkie przychodzące alerty są tłumaczone na wspólną strukturę i pozbawiane duplikatów, brakujących pól oraz oczywistych błędów. Na przykład powtarzające się ostrzeżenia z kilku urządzeń dotyczące tego samego ataku w ciągu kilku sekund są łączone w jeden, bogatszy rekord. Wynikiem jest usprawniona baza alertów, która zachowuje to, co najważniejsze — co się stało, kiedy się stało i które systemy były zaangażowane — jednocześnie usuwając bałagan, który tylko spowolniłby dalszą analizę.
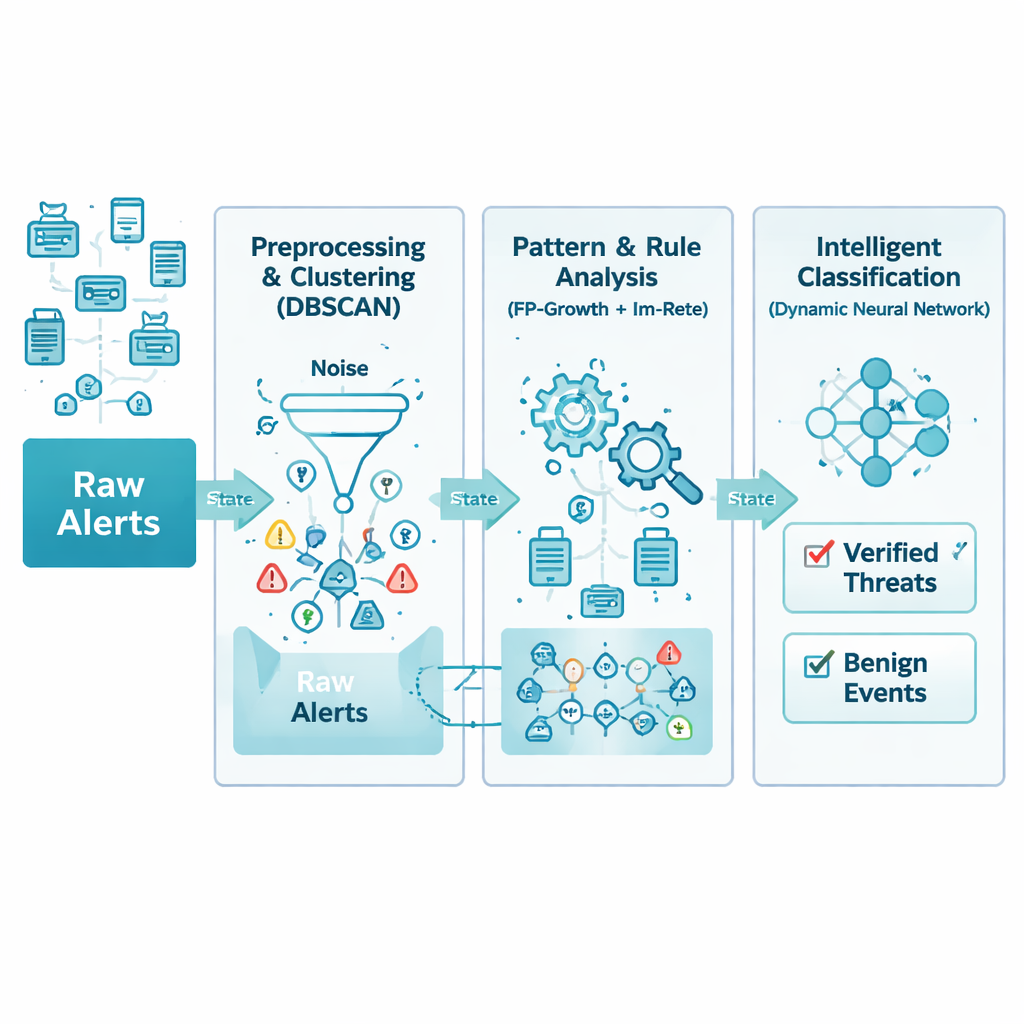
Pozwalanie wzorcom w czasie ujawnić prawdziwe problemy
Nawet oczyszczone dane mogą przytłaczać, dlatego kolejna warstwa wyszukuje naturalnych grup w czasie. Metoda opiera się na technice zwanej grupowaniem gęstościowym, która w praktyce szuka okresów, w których powiązane alarmy pojawiają się blisko siebie, traktując jednocześnie odosobnione lub przypadkowe alerty jako szum. Dzięki temu nie trzeba wcześniej zgadywać, ile typów incydentów występuje. System stosuje też nakładające się okna czasowe, aby szybkie ataki nie zostały przypadkowo podzielone na różne partie. Przy odpowiednim dostrojeniu ten etap zachowuje najbardziej informatywne wybuchy aktywności, odrzucając jednocześnie nawet do jednej trzeciej wprowadzającego w błąd tła w surowych strumieniach.
Nauczanie reguł radzenia sobie z brakującymi fragmentami
Sieci w rzeczywistości są niedoskonałe: pakiety giną, urządzenia zachowują się nieprawidłowo, a niektóre alarmy nigdy nie docierają. Tradycyjne silniki reguł oczekują pełnych informacji i zawodzą, jeśli czegoś brakuje. W tym rozwiązaniu autorzy przeprojektowali klasyczny system reguł Rete tak, aby każdy warunek w regule miał wagę odzwierciedlającą jego ważność. Zamiast wymagać idealnego dopasowania wszystkich szczegółów, silnik sprawdza, czy wystarczająca liczba istotnych elementów pokrywa się w czasie. Takie „rozmyte” podejście pozwala systemowi rozpoznać wzorzec ataku nawet jeśli np. wczesne sondowanie lub drobny alert sensora nie został zarejestrowany. Równocześnie rzadko używane lub długo nieaktywne gałęzie reguł są przycinane, aby utrzymać niskie zużycie pamięci.
Sieć neuronowa, która przekształca się sama
Po tym, jak wzorce i reguły przekształciły alerty w bardziej sensowne cechy, końcowy etap wykorzystuje sieć neuronową do decydowania, które zdarzenia są rzeczywistymi zagrożeniami, a które są nieszkodliwe. W odróżnieniu od wielu modeli uczenia maszynowego, które są stałe po zaprojektowaniu, ta sieć może powiększać lub zmniejszać swoje warstwy ukryte w trakcie treningu. Zaczyna skromnie, dodaje jednostki, gdy wyraźnie poprawiają one wydajność, i przycina części, które nie przynoszą korzyści. Taka adaptacyjna konstrukcja pomaga modelowi dopasować się zarówno do prostych, jak i złożonych zbiorów danych bez zgadywania, zmniejszając ryzyko przeuczenia i skracając czas treningu przy zachowaniu wysokiej dokładności.
Co pokazują testy w praktyce
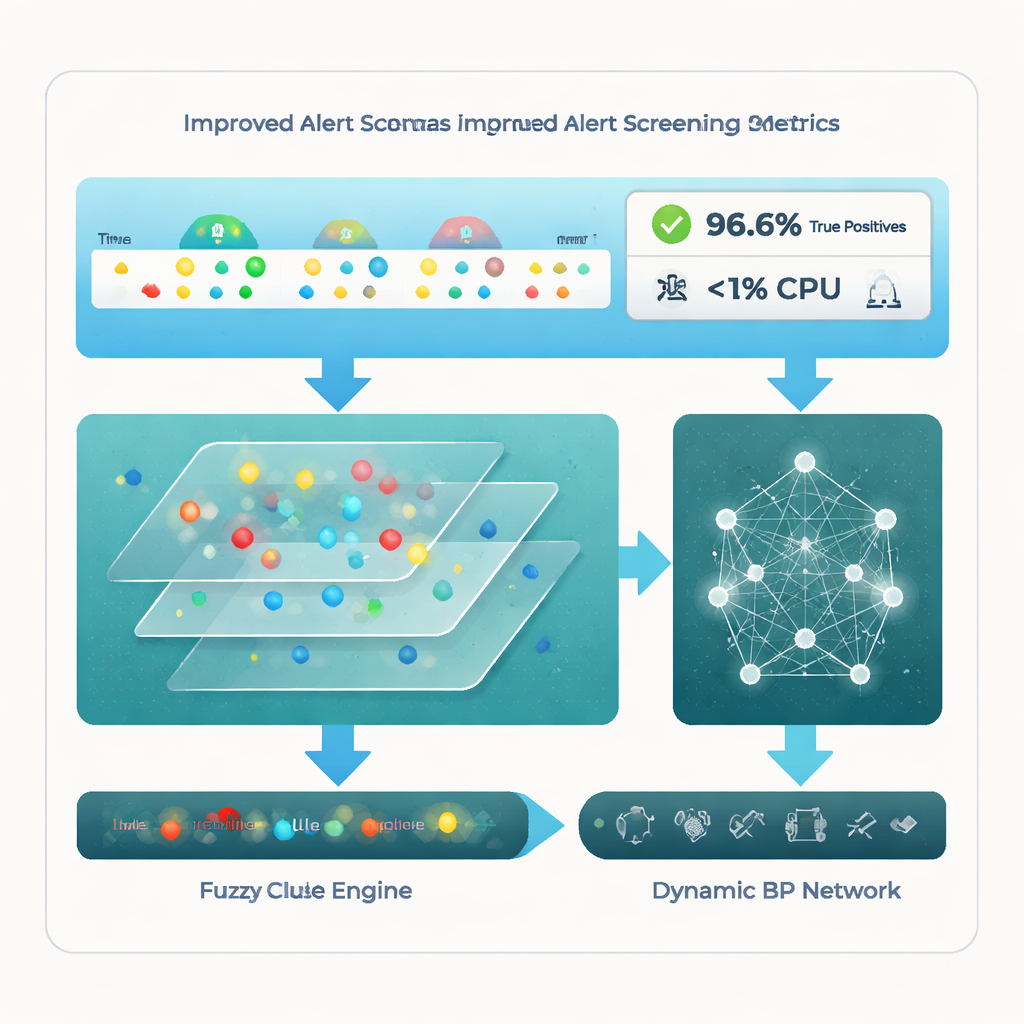
Zespół ocenił swój system na znanych publicznych zbiorach danych dotyczących włamań oraz na dużej, rzeczywistej kolekcji alertów firmowych. W porównaniu z czterema nowoczesnymi metodami — w tym czystym grupowaniem, wyspecjalizowanymi systemami alertów dla IoT i dostrojonymi sieciami neuronowymi — nowy wielopoziomowy pipeline wyróżnia się. Osiąga wskaźnik trafnych wykryć na poziomie około 96,6%, co oznacza, że prawidłowo identyfikuje niemal wszystkie rzeczywiste źródła ataków, przy jednoczesnym utrzymaniu odsetka hałaśliwych lub nieistotnych alertów na poziomie około 18,7%. Równie uderzające jest to, że robi to przy zużyciu CPU poniżej 1%, znacznie mniej niż konkurencyjne podejścia. Testy statystyczne potwierdzają, że te korzyści nie wynikają z przypadku, lecz z tego, jak metoda łączy grupowanie, wnioskowanie regułowe i adaptacyjne uczenie.
Co to oznacza dla codziennych zespołów bezpieczeństwa
Dla analityków bezpieczeństwa, którzy codziennie toną w alarmach, praca ta wskazuje kierunek dla narzędzi będących jednocześnie dokładniejszymi i łagodniejszymi dla ograniczonego sprzętu. Poprzez oczyszczanie danych, inteligentne grupowanie w czasie, tolerowanie brakujących elementów i wykorzystanie samo-dopasowującej się sieci neuronowej, ramy pomagają wyeksponować relatywnie niewielki zestaw alertów, którym naprawdę należy się przyjrzeć. To oznacza szybszą reakcję na realne ataki, mniej zmarnowanych godzin na fałszywe tropy i lepsze wykorzystanie istniejącego sprzętu. W miarę jak sieci rosną pod względem rozmiaru i złożoności, taka wielopoziomowa selekcja może być kluczowym składnikiem utrzymania bezpieczeństwa infrastruktury cyfrowej bez przeciążania ludzi, którzy ją bronią.
Cytowanie: Ni, L., Zhang, S., Huang, K. et al. Multi-level screening method for network security alarms based on DBSCAN algorithm and rete rule inference. Sci Rep 16, 5632 (2026). https://doi.org/10.1038/s41598-026-36369-6
Słowa kluczowe: bezpieczeństwo sieci, detekcja włamań, filtrowanie alarmów, uczenie maszynowe, wykrywanie ataków cybernetycznych