Clear Sky Science · pl
Głęboka sieć inception z połączeniami resztkowymi do rozpoznawania odręcznych liter języka tamilskiego
Ocalanie pisma ręcznego w erze cyfrowej
Od starych manuskryptów na liściach palmowych po codzienne notatki — duża część pisanej spuścizny w języku tamilskim nadal istnieje na papierze. Przekształcenie tej bogatej mieszanki odręcznych stron w przeszukiwalny, cyfrowy tekst jest niezbędne dla zachowania kultury, wspierania edukacji i tworzenia lepszych technologii językowych. W artykule opisano nowy system widzenia komputerowego, zwany TamHNet, który odczytuje pismo ręczne w języku tamilskim z niemal doskonałą dokładnością, nawet gdy litery wydają się wzajemnie myląco podobne.
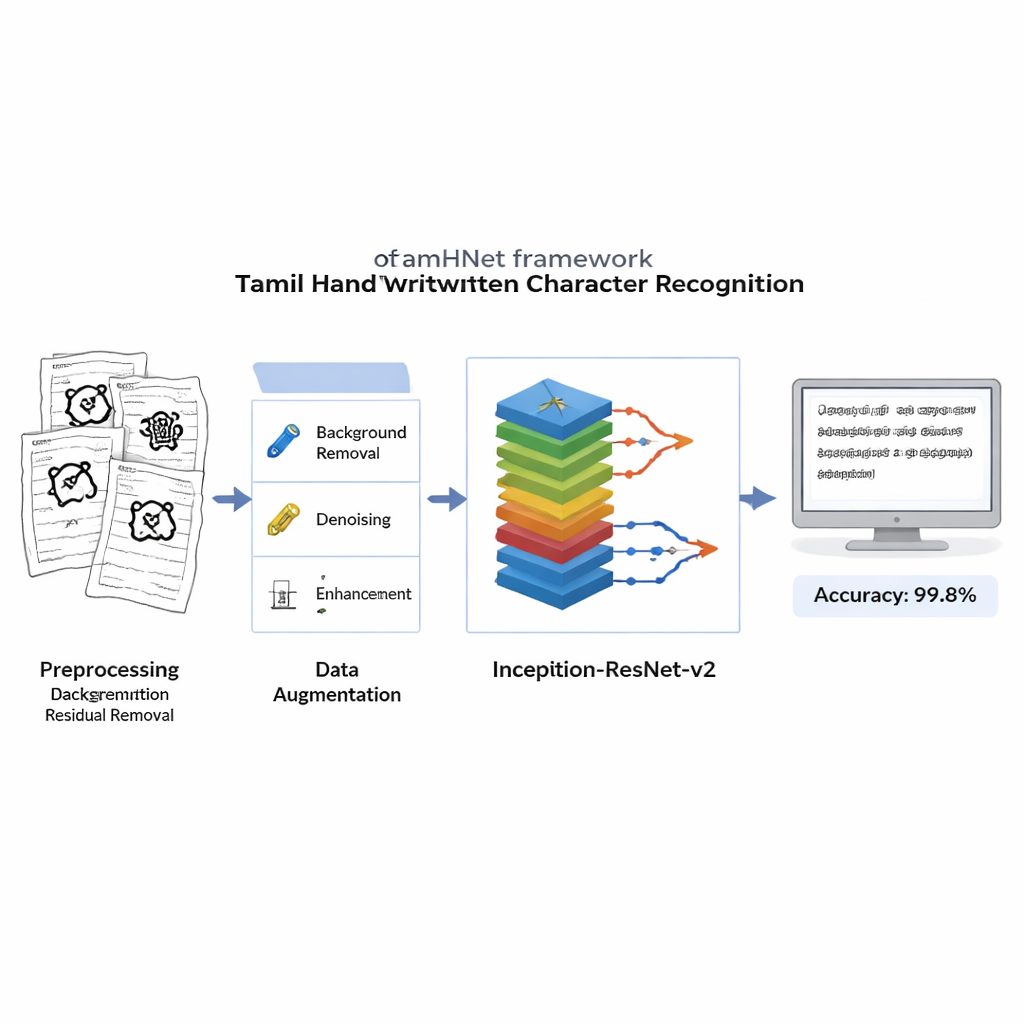
Dlaczego litery tamilskie są trudne dla komputerów
Językiem tamilskim posługuje się ponad 80 milionów ludzi, a jego pismo zawiera 247 znaków — samogłosek, spółgłosek i wielu ich kombinacji. Wiele liter różni się jedynie drobnymi zwojami lub dodatkowymi kreskami, a autorzy notatek bardzo różnią się sposobem kreślenia każdego znaku. Pary takie jak எ/ஏ czy ஒ/ஓ mogą z pierwszego spojrzenia wyglądać niemal identycznie, a znaki takie jak ல i வ łatwo można pomylić. Wcześniejsze programy komputerowe, a nawet nowoczesne systemy uczenia maszynowego, często miały problem z tymi subtelnościami, co prowadziło do błędnych odczytów i zawodnej digitalizacji dokumentów.
Tworzenie zbioru danych z prawdziwego świata
Aby trenować i testować system w realistycznych warunkach, badacze stworzyli nowy Zbiór Znaków Izolowanych Tamil (Tamil Isolated Character Dataset) wykorzystując odręczne próbki od 1000 studentów uniwersytetu. Zamiast polegać na syntetycznych lub komputerowo generowanych obrazach, zebrali autentyczne znaki pisane piórem na papierze obejmujące 12 samogłosek, 18 spółgłosek i 214 powszechnych kombinacji. Zespół starannie oznakował te próbki i udostępnił zbiór publicznie, aby inne grupy mogły porównywać metody i rozwijać badania. Poprzez zorganizowanie pisma w 104 symbole bazowe obejmujące wszystkie 247 znaków, zredukowano nadmiarowość, jednocześnie odwzorowując pełen zakres kształtów występujących w rzeczywistym piśmie ręcznym.
Czyszczenie, rozciąganie i nauka obrazów
Zanim rozpocznie się nauka, każdy zeskanowany obraz jest oczyszczany, by usunąć zakłócenia tła, rozmazy i nierównomierne oświetlenie, przy jednoczesnym zachowaniu delikatnych śladów definiujących literę. Obrazy konwertuje się na ostre czarno-białe wersje i przeskalowuje do standardowego formatu, aby komputer widział każdy przykład w ten sam sposób. Aby system był odporny na różne nawyki pisma, autorzy stosują kontrolowane zniekształcenia: nieznacznie przesuwają kluczowe punkty obrazu i stosują płynne odkształcenia, generując nowe wersje każdej litery, które nadal przypominają ten sam znak dla człowieka. Poszerzony zestaw treningowy pomaga modelowi rozpoznawać znaki nawet wtedy, gdy są pochylone, spłaszczone lub napisane o nietypowych proporcjach.
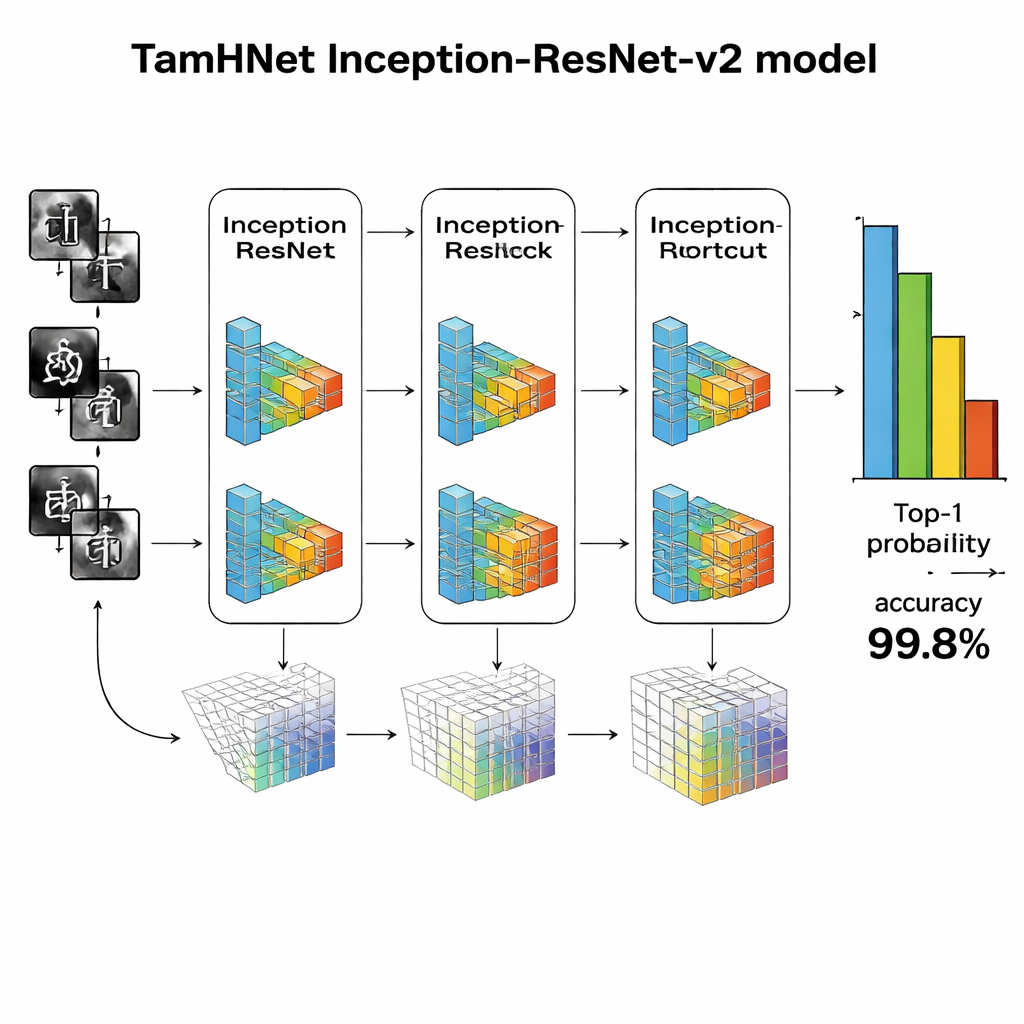
Głęboka sieć ucząca się subtelnych różnic
Rdzeniem TamHNet jest potężna architektura uczenia głębokiego nazwana Inception-ResNet-v2, pierwotnie zaprojektowana do ogólnego rozpoznawania obiektów. Autorzy adaptują i dostrajają tę sieć specjalnie do odręcznego pisma tamilskiego. Model przetwarza każdy obraz przez wiele warstw, które stopniowo przekształcają surowe piksele w wyższej rangi wzorce, takie jak krawędzie, krzywizny i fragmenty znaków. Specjalne połączenia skrótowe, znane jako łącza resztkowe, stabilizują proces uczenia i pomagają sieci koncentrować się na drobnych, lecz kluczowych różnicach między podobnymi literami. Zamiast od razu dopasowywać wszystkie wewnętrzne ustawienia, zespół selektywnie „odmraża” najbardziej przydatne warstwy i stroi je pod to zadanie. Stosują technikę optymalizacji zwaną Adam, która automatycznie dostosowuje tempo zmian każdego parametru, pozwalając sieci uczyć się efektywnie z złożonego i czasem nieporządnego pisma ręcznego.
Jak dobrze system czyta pismo ręczne
Badacze ocenili TamHNet na nowym zbiorze danych, korzystając ze standardowych miar jakości rozpoznawania. System osiąga około 99,8% dokładności w 104 klasach znaków, przewyższając szerokie spektrum wcześniejszych metod opartych na maszynach wektorów nośnych, tradycyjnych sieciach konwolucyjnych i innych zaawansowanych konstrukcjach uczenia głębokiego. Szczegółowe testy pokazują, że nawet litery o bardzo podobnych kształtach są w większości przypadków poprawnie rozróżniane, a krzywe statystyczne potwierdzają, że model bardzo rzadko myli jeden znak z drugim. W porównaniu z wcześniejszymi pracami jest to wyraźny krok naprzód pod względem niezawodności rozpoznawania odręcznego pisma tamilskiego.
Co to oznacza dla czytelników i archiwów
Dla osób niebędących specjalistami najważniejszym wnioskiem jest to, że komputery znacznie lepiej radzą sobie z odczytem indyjskiego pisma tamilskiego. System taki jak TamHNet może zasilać narzędzia, które zamieniają stosy zeszytów, historyczne manuskrypty i formularze odręczne w przeszukiwalny tekst cyfrowy z minimalną korektą ludzką. Chociaż obecny model nie obsługuje jeszcze niektórych symboli opartych na kropkach i starszych wariantów pisma, autorzy przedstawiają plany rozszerzenia go także na dawne style pisania. W praktycznym wymiarze badania te przybliżają nas do szeroko zakrojonej, dokładnej digitalizacji dokumentów w języku tamilskim, pomagając chronić dziedzictwo kulturowe i ułatwiając dostęp do wiedzy pisanej dla przyszłych pokoleń.
Cytowanie: Periyasamy, H., Natarajan, S. & Amirtharajan, R. Deep inception neural network with residual connections for Tamil handwritten character recognition. Sci Rep 16, 6053 (2026). https://doi.org/10.1038/s41598-026-36330-7
Słowa kluczowe: rozpoznawanie odręcznego pisma tamilskiego, optyczne rozpoznawanie znaków, uczenie głębokie, Inception-ResNet, cyfrowa konserwacja