Clear Sky Science · pl
Porównanie wydajności dużych modeli językowych w ocenie wiedzy o boronowej terapii wychwytu neutronowego
Inteligentni korepetytorzy dla nowego rodzaju radioterapii
Boronowa terapia wychwytu neutronowego, w skrócie BNCT, to nowatorski rodzaj leczenia promieniowaniem, którego celem jest zniszczenie guzów przy jednoczesnym oszczędzaniu pobliskich, zdrowych tkanek. W miarę jak ta złożona terapia przechodzi z laboratoriów badawczych do szpitali, lekarze i osoby w szkoleniu muszą przyswoić wiele nowych, specjalistycznych informacji. Badanie stawia aktualne pytanie: czy dzisiejsze popularne chatboty oparte na sztucznej inteligencji mogą pomagać w nauczaniu i wsparciu BNCT, a jeśli tak, na ile są wiarygodne?
Czym BNCT różni się od standardowej radioterapii?
BNCT działa zupełnie inaczej niż standardowe leczenie promieniami rentgenowskimi czy protonami. Pacjentom podaje się lek zawierający specjalną postać boru, która kumuluje się w komórkach nowotworowych. Gdy te komórki zostaną następnie wystawione na wiązkę neutronów, atomy boru ulegają drobnej reakcji jądrowej, uwalniając cząstki o krótkim zasięgu, które zabijają komórkę rakową „od środka”, pozostawiając w dużej mierze nietknięte sąsiednie tkanki. To wysoce selektywne podejście jest szczególnie obiecujące w przypadku guzów trudnych do leczenia lub pozbawionych tlenu. Do niedawna BNCT zależała od reaktorów jądrowych jako źródeł neutronów, co ograniczało jej zastosowanie kliniczne. Zatwierdzenie maszyn BNCT opartych na akceleratorach w Japonii w 2020 roku oraz uruchomienie nowych ośrodków w krajach takich jak Chiny sprawiły, że BNCT stała się realistyczną opcją dla większej liczby pacjentów — i stworzyły pilną potrzebę ukierunkowanego szkolenia i certyfikacji.
Test czterech wiodących systemów SI
Aby sprawdzić, jak dobrze wszechstronne chatboty radzą sobie z tematyką BNCT, badacze opracowali test składający się z 47 pytań obejmujących podstawowe pojęcia, najnowsze odkrycia, praktykę kliniczną oraz zadania z obliczeń i rozumowania. Pytania napisano w języku chińskim i angielskim; obejmowały one proste fakty (np. definicje) oraz bardziej wymagające zadania wymagające logiki lub pracy z liczbami. Cztery główne rodziny modeli — reprezentowane przez powszechnie używane systemy różnych firm — były testowane w pięciu oddzielnych okresach, w dwóch językach i z dwoma sposobami formułowania pytań (bezpośrednie pytania oraz pytania osadzone w krótkim scenariuszu klinicznym). Specjaliści od opieki onkologicznej punktowali każdą odpowiedź w oparciu o standardowy klucz, a zespół śledził także, jak często systemy przyznawały się do niepewności, mówiąc na przykład „nie wiem”.
Kto odpowiadał najlepiej i na jakiego rodzaju pytania?
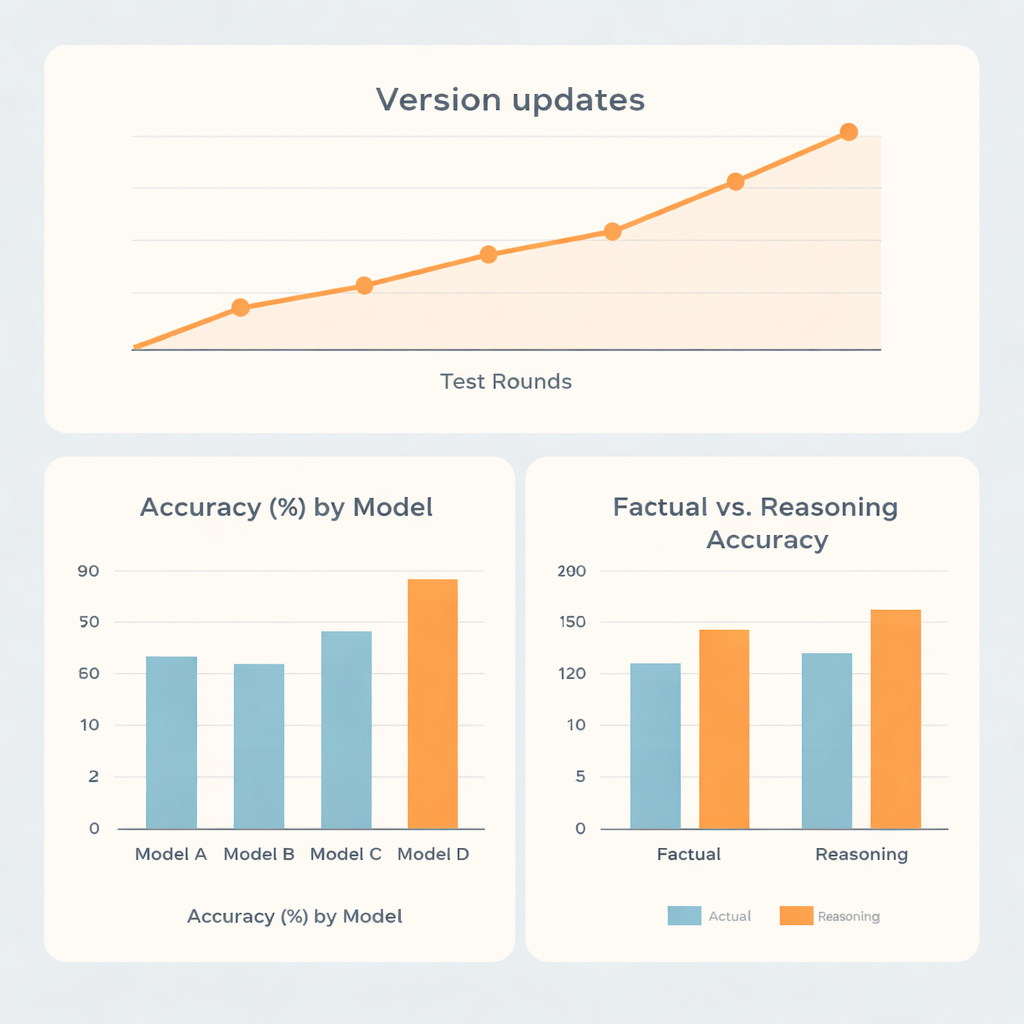
W ujęciu ogólnym dwie rodziny modeli wypadły wyraźnie lepiej niż pozostałe dwie. Najsilniejszy system osiągnął około 73% trafności, drugi w kolejności około 70%, natomiast pozostałe modele uzyskały wyniki w okolicach 62% i 56%. Co ciekawe, najlepsi nie wyróżniali się jedynie w przywoływaniu zapamiętanych faktów. Byli wyraźnie lepsi w zadaniach wymagających rozumowania niż w prostym odtwarzaniu informacji, co sugeruje, że te systemy stosunkowo dobrze radzą sobie z wieloetapowym myśleniem, na przykład przy obliczaniu dawek czy zadaniach planistycznych, w tym wąskim obszarze medycznym. Jeden model uzyskał niemal takie same wyniki w pytaniach faktograficznych i rozumieniowych, podczas gdy inny pozostawał w tyle ogólnie, mimo że w miarę dobrze radził sobie z zadaniami wymagającymi rozumowania.
Aktualizacje, języki i skłonność do mówienia „nie wiem”
Ponieważ systemy SI są często aktualizowane, badacze analizowali również, jak zmieniała się wydajność w pięciu rundach testowych rozłożonych od końca 2023 do połowy 2025 roku. Główne aktualizacje wersji zwykle przynosiły wyraźne skoki w dokładności, podczas gdy drobne poprawki w ramach tej samej wersji miały niewielki wpływ. Jedna z rodzin poprawiła się z poniżej 60% do ponad 80% trafności w czasie, co podkreśla szybkie tempo rozwoju technologii. Zaskakująco, to czy pytania zadawano po chińsku czy po angielsku, oraz czy formułowano je bezpośrednio czy w ramach roli‑odgrywki, miało jedynie niewielki wpływ w porównaniu z wrodzonymi mocnymi stronami każdego modelu. Bardziej znaczące były różnice w tym, jak otwarcie systemy przyznawały się do niepewności, gdy się myliły. Niektóre modele przyznawały się do niepewności niemal w jednej piątej błędnych odpowiedzi, podczas gdy inny robił to rzadko, często podając pewne, lecz błędne informacje.
Co to oznacza dla lekarzy, studentów i pacjentów
Badanie konkluduje, że najlepsze dzisiejsze, uniwersalne chatboty mogą już dostarczać w miarę dokładne wyjaśnienia i pytania ćwiczeniowe dotyczące BNCT, co czyni je obiecującymi narzędziami do edukacji i samokształcenia. Żaden z systemów nie jest jednak jeszcze w pełni godny zaufania, by poprawnie odpowiadać na wszystkie pytania dotyczące BNCT, a style wyrażania — albo ukrywania — niepewności różnią się w sposób istotny z punktu widzenia bezpieczeństwa. Na razie te narzędzia warto traktować jako inteligentnych asystentów, którzy mogą wspierać, lecz nie zastępować, ocenę ekspertów. Autorzy argumentują, że przed tym, jak SI będzie mogła odgrywać wiarygodną rolę na pierwszej linii w tej wysoko wyspecjalizowanej dziedzinie opieki onkologicznej, potrzebne będą dedykowane modele skoncentrowane na BNCT oraz jasne standardy użycia takich narzędzi w placówkach klinicznych i środowiskach edukacyjnych.
Cytowanie: Shen, S., Wang, S., Gao, M. et al. Performance comparison of large language models in boron neutron capture therapy knowledge assessment. Sci Rep 16, 5321 (2026). https://doi.org/10.1038/s41598-026-36322-7
Słowa kluczowe: boronowa terapia wychwytu neutronowego, radioterapia nowotworów, edukacja medyczna, sztuczna inteligencja, duże modele językowe