Clear Sky Science · pl
Wstępne uczenie kontrastowe obraz‑język sterowane obiektami do rozpoznawania celów w trybie zero‑shot
Bardziej przenikliwe oko nad zatłoczonym niebem i morzem
Nowoczesne systemy bezpieczeństwa i reagowania kryzysowego polegają na kamerach w przestrzeni powietrznej i morskiej, by wykrywać samoloty, statki i inne obiekty krytyczne. Jednak nauczenie komputerów rozróżniania myśliwca od samolotu cywilnego czy okrętu wojennego od towarowego okazuje się zaskakująco trudne, gdy sceny są zatłoczone, danych jest niewiele, a wciąż pojawiają się nowe modele sprzętu. W artykule przedstawiono OG‑CLIP — nowy system AI zaprojektowany do rozpoznawania celów wojskowych i cywilnych, których nigdy nie trenowano wprost, poprzez łączenie szerokiej bazy wiedzy z ostrzejszym skupieniem wzroku na istotnych obiektach.
Dlaczego tradycyjne AI chybia celu
Większość systemów rozpoznawania obrazów uczy się na ogromnych zbiorach oznakowanych zdjęć: każdy obraz powiązany jest z ustaloną listą kategorii, takich jak „kot” czy „samochód”. To podejście zawodzi w wyspecjalizowanych dziedzinach, jak obrona czy teledetekcja, gdzie dane są wrażliwe, etykietowanie wymaga ekspertów, a różnorodność sprzętu jest ogromna. Nowsze modele wizja‑język, takie jak CLIP, parują obrazy z krótkimi napisami z internetu, co pozwala im rozpoznawać nowe koncepcje opisane słowami. Mimo to w obrazach wojskowych te modele nadal mają trudności: napisy bywają nieprecyzyjne, tło — np. chmury i fale — dominuje w pikselach, a wewnętrzne cechy modeli nie są na tyle elastyczne, by efektywnie działać na wszystkim, od małych dronów po potężne serwery. OG‑CLIP rozwiązuje te trzy problemy bezpośrednio.
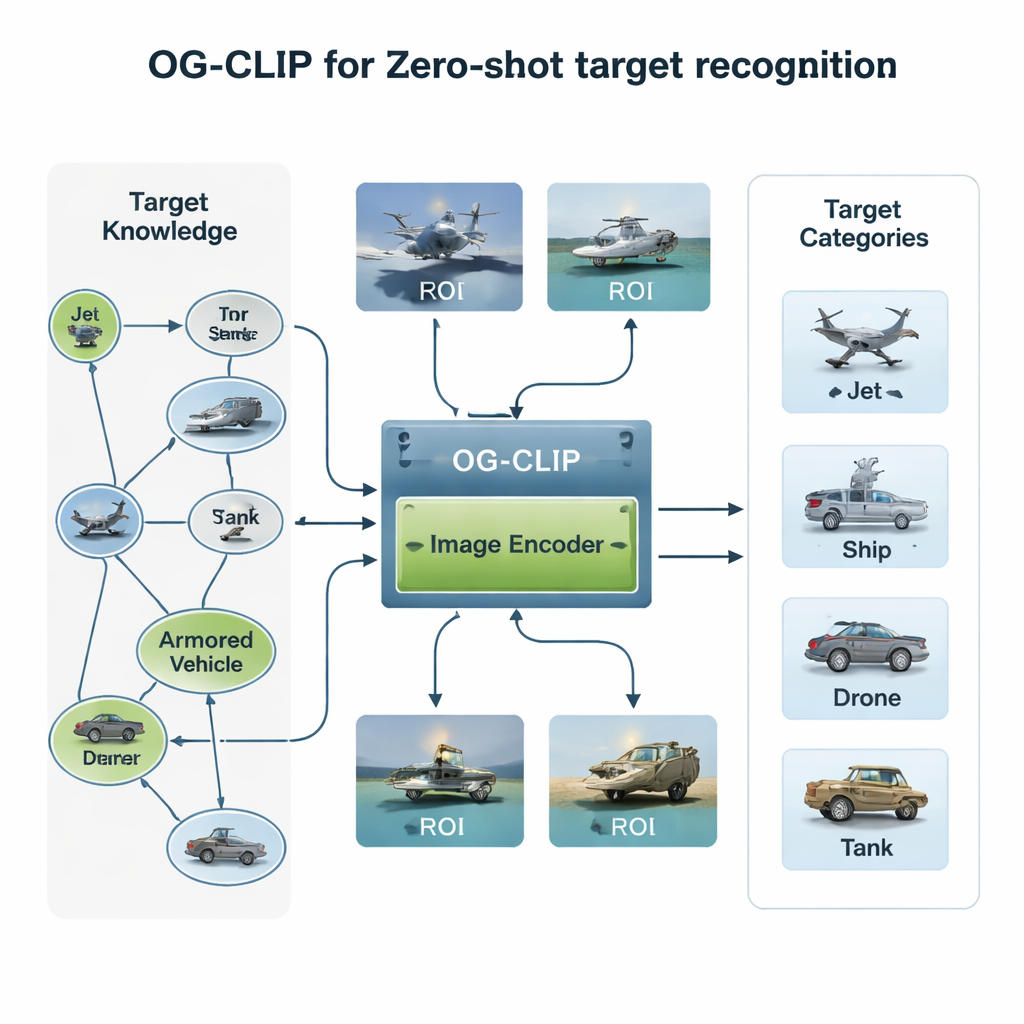
Budowanie świata treningowego bogatego w wiedzę
Pierwszym składnikiem OG‑CLIP jest starannie zaprojektowany uniwersum treningowe. Autorzy zebrali bazę danych 5 000 typów celów — od myśliwców i bombowców po okręty wojenne i samoloty cywilne — i uporządkowali je w szczegółowy graf wiedzy. Każdy wpis zawiera uporządkowane fakty, takie jak zasięg, masa czy konfiguracja uzbrojenia, pochodzące z publicznych źródeł obronnych, encyklopedii i dokumentów technicznych. Następnie zgromadzili około miliona obrazów korzystając z publicznych zestawów danych, wyszukiwarek internetowych, starszych archiwów wewnętrznych oraz symulacji z silników gier. Aby zachować wiarygodność danych, sklastrowali obrazy przy użyciu istniejącego modelu w celu wykrycia odchyleń, poddali je przeglądowi ekspertów i odfiltrowali błędne etykiety. Wreszcie wykorzystali zaawansowane narzędzia wizja‑język, aby przekształcić graf wiedzy w bogate, naturalne opisy językowe każdego obrazu, dzięki czemu system uczy się nie tylko „to jest odrzutowiec”, lecz także „samolot jednoprzęsłowy z wznoszącymi się zakończeniami skrzydeł” albo „bombowiec stealth o kształcie skrzydła latającego”.
Nauka ignorowania szumu
Drugą innowacją jest to, gdzie model kieruje wzrok. Na wielu zdjęciach satelitarnych lub lotniczych rzeczywisty statek czy samolot zajmuje tylko niewielki fragment kadru, otoczony rozpraszającym niebem, morzem lub terenem. OG‑CLIP dodaje moduł regionu zainteresowania (ROI), który naśladuje sposób, w jaki człowiek zerknąłby na kluczowy obiekt zamiast na cały obraz. Nowoczesne narzędzie segmentacyjne automatycznie obrysowuje prawdopodobne obiekty na obrazie, generując miękkie maski, które podświetlają cel i przyciemniają tło. Maski są podawane razem z oryginalnym obrazem do wizualnego rdzenia modelu, tak aby jego uwaga naturalnie koncentrowała się na wyróżniających cechach, takich jak kształt skrzydeł, układ pokładu czy sylwetka kadłuba. Ten wtyczkowy projekt można dodać do istniejących systemów bez przepisywania ich architektury, nadając im bardziej „sterowane obiektowo” spojrzenie.

Dopasowanie szczegółu do sprzętu
Trzeci element dotyczy praktycznego, lecz kluczowego aspektu: nie wszystkie urządzenia mogą pozwolić sobie na ten sam poziom szczegółowości. Stacja naziemna satelity może przetwarzać bogate, wysokowymiarowe cechy, podczas gdy mały dron potrzebuje szybszych, lżejszych obliczeń. Tradycyjne metody ustalają pojedynczy rozmiar cech lub trenują kilka osobnych modeli dla różnych rozmiarów. OG‑CLIP stosuje zamiast tego reprezentację w stylu „Matrioszki”, pakując informacje na wielu poziomach szczegółu w jednym wektorze, jak zagnieżdżone lalki. System może odciąć krótsze lub dłuższe fragmenty tego wektora — grubsze lub bardziej drobiazgowe opisy zawartości obrazu — bez ponownego trenowania. Mechanizm ważenia zachęca każdy poziom do zachowania najbardziej użytecznych informacji do klasyfikacji, a dodatkowy termin straty skłania poziomy do pozostawania semantycznie spójnymi między sobą.
Jak sprawdza się w praktyce?
Aby przetestować OG‑CLIP, badacze zbudowali wymagający zestaw ewaluacyjny obejmujący 99 kategorii celów, w tym 51 typów samolotów wojskowych, 29 typów okrętów wojennych oraz 19 celów cywilnych lub mieszanych. Co istotne, żadna z tych kategorii nie występuje w danych treningowych, więc system musi polegać na zdobytej wiedzy językowej i wzorcach wizualnych — to test w trybie „zero‑shot”. W porównaniu z kilkoma silnymi bazami opartymi na CLIP, OG‑CLIP poprawił średnią dokładność o ponad 11 punktów procentowych, osiągając 84,28 procent ogólnie. Szczególnie dobrze radził sobie w zatłoczonych, złożonych scenach oraz przy drobnych różnicach między podobnymi modelami, takimi jak różne myśliwce, gdzie moduł ROI i opisy bogate w wiedzę dały mu wyraźną przewagę. Badania ablacyjne wykazały, że każdy komponent — graf wiedzy, skupienie ROI i adaptacyjne reprezentacje — wnosił mierzalne korzyści.
Co to oznacza dla monitoringu w praktyce
Dla osób niezajmujących się specjalistycznie kluczowy wniosek jest taki, że OG‑CLIP to krok w kierunku systemów bezpieczeństwa i monitoringu, które mogą bardziej niezawodnie rozpoznawać nieznane samoloty i statki w obrazach z rzeczywistego świata, nawet gdy przykładów z etykietami jest niewiele. Łącząc uporządkowaną wiedzę ekspercką, automatyczne skupienie na obiekcie zainteresowania i regulowane poziomy szczegółu, podejście sprawia, że AI wizja‑język staje się zarówno mądrzejsze, jak i bardziej praktyczne. Poza obronnością podobne pomysły mogą wspierać monitorowanie środowiska, reagowanie na katastrofy i systemy inspekcji przemysłowej, pomagając interpretować złożone sceny przy pracy na szerokim spektrum sprzętu.
Cytowanie: Zheng, C. Object-guided contrastive language-image pre-training for zero-shot target recognition. Sci Rep 16, 6425 (2026). https://doi.org/10.1038/s41598-026-36314-7
Słowa kluczowe: rozpoznawanie zero‑shot, modele wizja‑język, detekcja obiektów, teledetekcja, grafy wiedzy