Clear Sky Science · pl
Głębokie transformery oparte na percepcji wzrokowej do klasyfikowania obrazów malarskich i fotografii poprzez ekstrakcję cech
Dlaczego ma to znaczenie dla codziennych obrazów
W erze, gdy każdy może wygenerować realistyczny obraz kilkoma kliknięciami, coraz trudniej rozpoznać, czy zdjęcie jest prawdziwą fotografią, tradycyjnym obrazem malarskim, czy czymś stworzonym całkowicie przez algorytmy. To badanie analizuje, jak współczesna sztuczna inteligencja może automatycznie odróżniać obrazy malarskie stworzone przez człowieka od zdjęć wykonanych aparatem, a nawet od obrazów generowanych przez AI, pomagając chronić rynki sztuki, archiwa i użytkowników internetowych przed nieporozumieniami i fałszerstwami.
Sztuka, fotografie i wzrost ilości obrazów tworzonych przez maszyny
Obrazy malarskie i fotografie mogą na pierwszy rzut oka wyglądać podobnie na ekranie, ale niosą ze sobą różne wizualne odciski palców. Obrazy malarskie często ujawniają widoczne pociągnięcia pędzla, stylizowane kolory i bardziej abstrakcyjne kompozycje, podczas gdy fotografie zwykle zawierają ostrzejsze detale i naturalne oświetlenie. Jednocześnie nowe generatory obrazów coraz lepiej naśladują obie formy. Muzea, galerie, kolekcjonerzy i platformy cyfrowe coraz częściej potrzebują narzędzi, które szybko i niezawodnie określą, z jakim rodzajem obrazu mają do czynienia — zarówno w celach uwierzytelniania dzieł, jak i zarządzania napływem syntetycznej treści.
Nowy pipeline do nauczania maszyn widzenia
Naukowcy zbudowali kompletny pipeline analizy obrazów oparty na Vision Transformerze, nowym modelu głębokiego uczenia pierwotnie rozwiniętym do przetwarzania języka, a teraz zaadaptowanym do obrazów. System trenowano na publicznym zbiorze z Kaggle zawierającym 1 361 obrazów malarskich i 3 747 fotografii, reprezentujących szeroką gamę scen i stylów. Każdy obraz jest najpierw standaryzowany: zmianiany rozmiar, delikatnie przycinany, a następnie wzbogacany przez odbicia lustrzane, niewielkie obroty, zmiany jasności i usuwanie szumów, aby model doświadczył wielu realistycznych wariantów. Po takim przygotowaniu Vision Transformer dzieli obraz na małe łatki i uczy się, jak różne części obrazu odnoszą się do siebie w całej ramie. 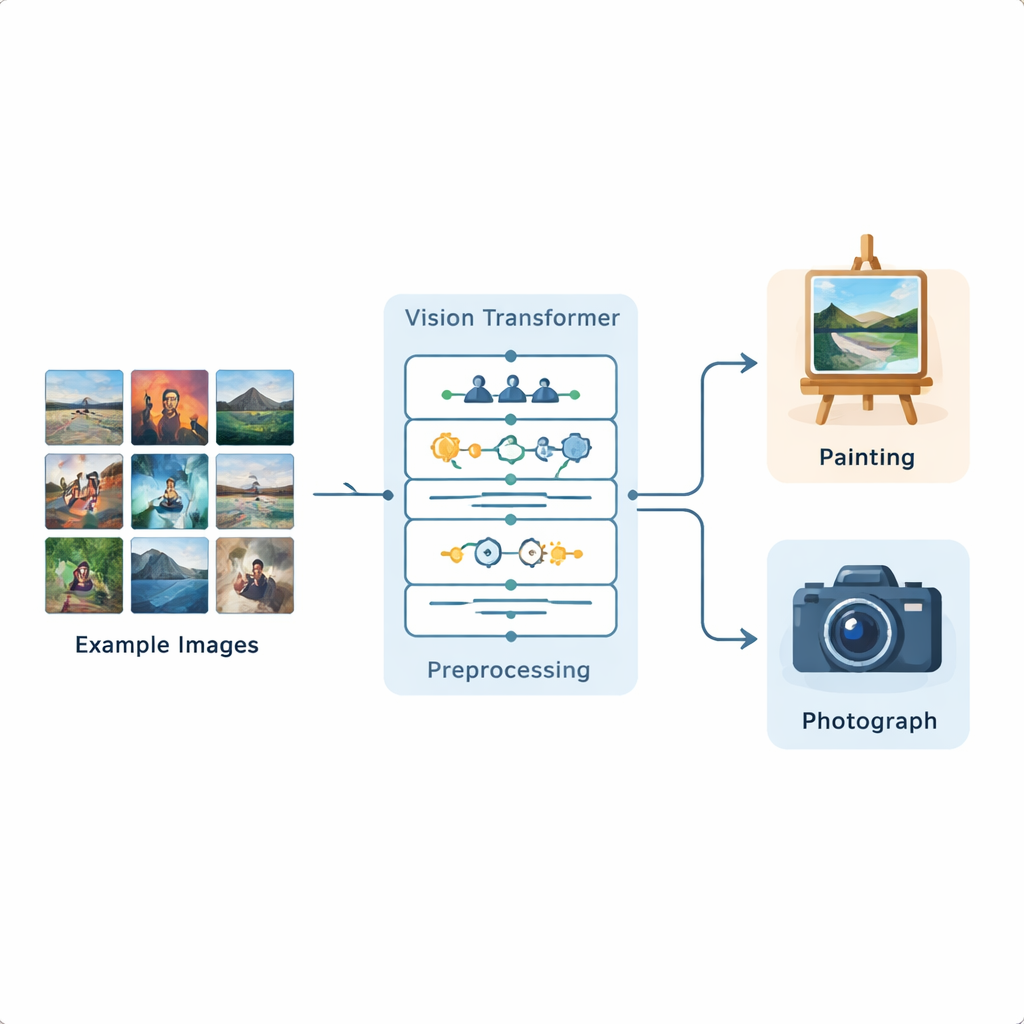
Jak model koncentruje się na właściwych szczegółach
W przeciwieństwie do wcześniejszych sieci neuronowych, które głównie analizowały lokalne wzorce, Vision Transformer używa mechanizmu „uwagi” (attention) do decydowania, które części obrazu są najważniejsze dla danego zadania. Dla każdej łatki efektywnie ocenia, jak mocno powinien zwracać uwagę na każdą inną łatkę. Dzięki temu lepiej dostrzega strukturę globalną: sposób, w jaki kolory rozlewają się po płótnie, jak światło pada w scenie, czy jak powtarzają się tekstury. Aby sprawdzić, że model nie zgaduje przypadkowo, autorzy stosują też metodę wizualizacji zwaną Grad-CAM, która podświetla konkretne regiony wpływające na każdą decyzję. W przypadku obrazów malarskich te wyróżnione obszary zwykle dotyczą faktury pociągnięć pędzla i stylizowanych partii; dla fotografii skupiają się wokół drobnych krawędzi, realistycznych powierzchni i przejść oświetlenia. 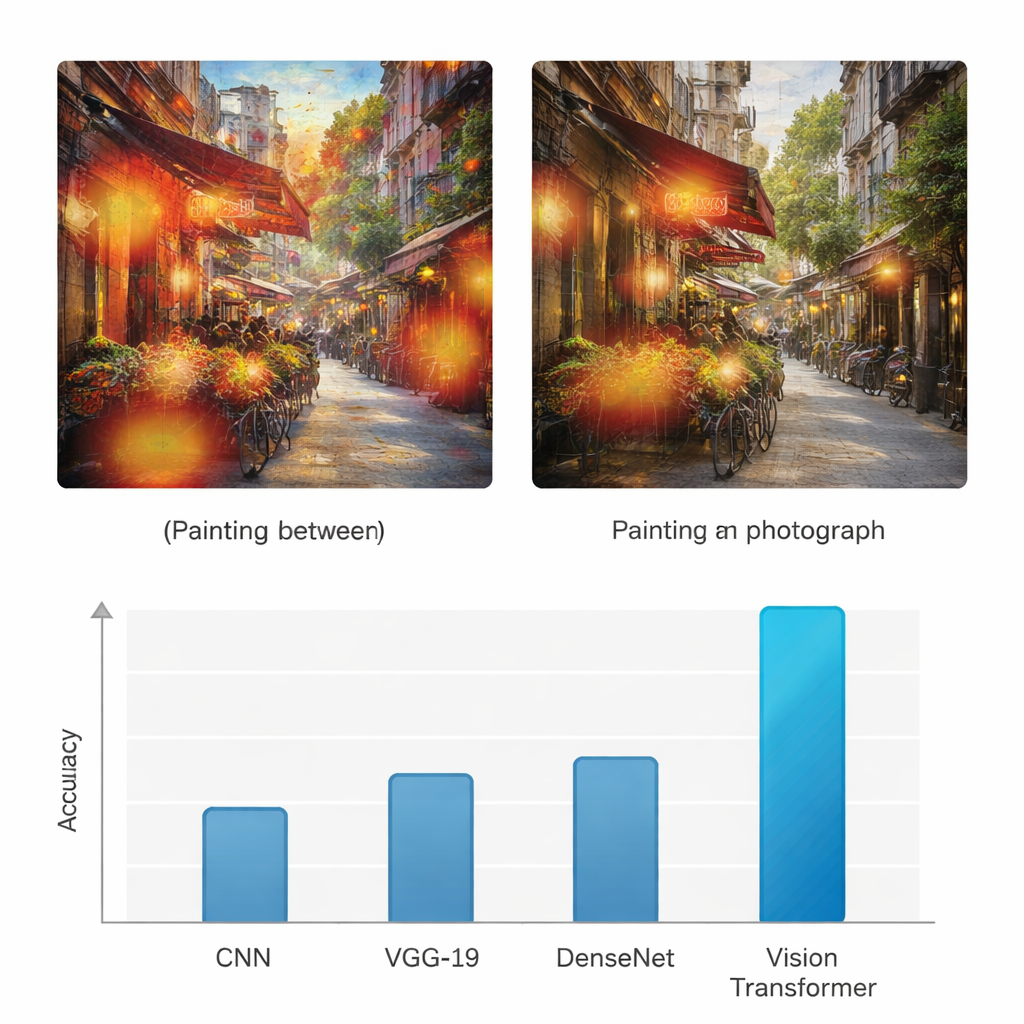
Przewyższając wcześniejsze metody rozpoznawania obrazów
Aby sprawdzić, czy podejście rzeczywiście wnosi wartość, badanie porównuje Vision Transformera z trzema powszechnie używanymi architekturami głębokiego uczenia: standardową konwolucyjną siecią neuronową (CNN), siecią VGG-19 oraz DenseNet. Wszystkie modele były trenowane i testowane na tym samym zbiorze danych i oceniane za pomocą powszechnych miar, takich jak dokładność (accuracy), precyzja, recall i F1-score, które równoważą prawidłowe wykrycia i błędy dla obu klas. Podczas gdy sieci bazowe osiągały dokładności w przedziale od średnich 70% do średnich 80%, Vision Transformer osiągnął 95% dokładności zarówno dla obrazów malarskich, jak i fotografii, z równie wysoką precyzją i czułością. Autorzy przeprowadzili także wiele testów statystycznych, by potwierdzić, że ta poprawa nie jest wynikiem przypadku, pokazując, że model oparty na transformerze jest niezawodnie lepszy w powtarzalnych próbach i przy różnych kryteriach oceny.
Co to oznacza dla sztuki, zaufania i technologii
Wyniki sugerują, że współczesne modele transformerowe mogą służyć jako potężne i wytłumaczalne narzędzia do oddzielania obrazów malarskich od fotografii oraz do wykrywania obrazów generowanych przez AI, które naśladują dowolne z tych mediów. Dla osób nietechnicznych kluczowy wniosek jest taki, że komputery potrafią wykrywać subtelne wskazówki — takie jak ślady pędzla, gładkość czy gradienty oświetlenia — które nawet uważny obserwator ludzki mógłby przeoczyć, i robić to na dużą skalę. Takie systemy mogą pomóc galeriom i kolekcjonerom w weryfikacji dzieł, wspierać kustoszy i archiwistów w porządkowaniu rozległych zbiorów cyfrowych oraz pomagać platformom internetowym w oznaczaniu lub filtrowaniu treści syntetycznych. W miarę jak generatory obrazów będą dalej zacierać granicę między rzeczywistością a kreacją, metody takie jak przedstawiona tutaj oferują praktyczny sposób na utrzymanie zaufania do tego, co widzimy.
Cytowanie: Yu, L. Visual perception based deep learning transformers for classifying paintings and photographs through feature extraction. Sci Rep 16, 5326 (2026). https://doi.org/10.1038/s41598-026-36298-4
Słowa kluczowe: obrazy wygenerowane przez AI, uwierzytelnianie dzieł sztuki, klasyfikacja obrazów, vision transformer, analiza sztuki cyfrowej