Clear Sky Science · pl
Meta-uczenie dla rozpoznawania otwartych zadań z niewielu przykładów
Dlaczego uczenie SI na bardzo niewielu przykładach ma znaczenie
Nowoczesne systemy sztucznej inteligencji potrafią rozpoznawać twarze, zwierzęta i przedmioty codziennego użytku z imponującą dokładnością — zwykle jednak dopiero po obejrzeniu milionów oznaczonych obrazów. W wielu rzeczywistych sytuacjach, na przykład przy diagnozowaniu rzadkiej choroby czy wykrywaniu nowego rodzaju uszkodzenia na linii produkcyjnej, po prostu nie dysponujemy tak dużą ilością danych. Artykuł bada, jak trenować modele SI, które potrafią nauczyć się nowych zadań wizualnych z zaledwie kilku przykładów, nawet gdy te zadania wyglądają zupełnie inaczej niż to, na czym model był trenowany. Wprowadza metodę nazwaną Open-MAML, której celem jest uczynienie takiego elastycznego uczenia przy małej ilości danych bardziej niezawodnym i przewidywalnym.
Od stałych ćwiczeń klasowych do otwartych kartkówek
Większość badań nad „uczeniem z nielicznymi przykładami” ocenia systemy SI w ściśle kontrolowanych warunkach. Model jest trenowany i testowany na bardzo podobnych zadaniach — na przykład zawsze musi rozróżnić dokładnie pięć kategorii (tzw. „5-way”) mając po jednym przykładzie na kategorię („1-shot”). To jak ćwiczenie ucznia tylko na pięciopunktowych quizach z jednym przykładem dla każdego typu pytania. W praktyce warunki są znacznie bardziej chaotyczne: liczba kategorii może się zmieniać, a ilość oznaczonych danych dla każdej z nich rosnąć lub maleć w czasie. Autorzy nazywają taką bardziej realistyczną sytuację ustawieniem otwartego zadania (open-task), w którym modele muszą radzić sobie z zadaniami o liczbie klas i przykładów różnej od tych, które widziały podczas treningu. 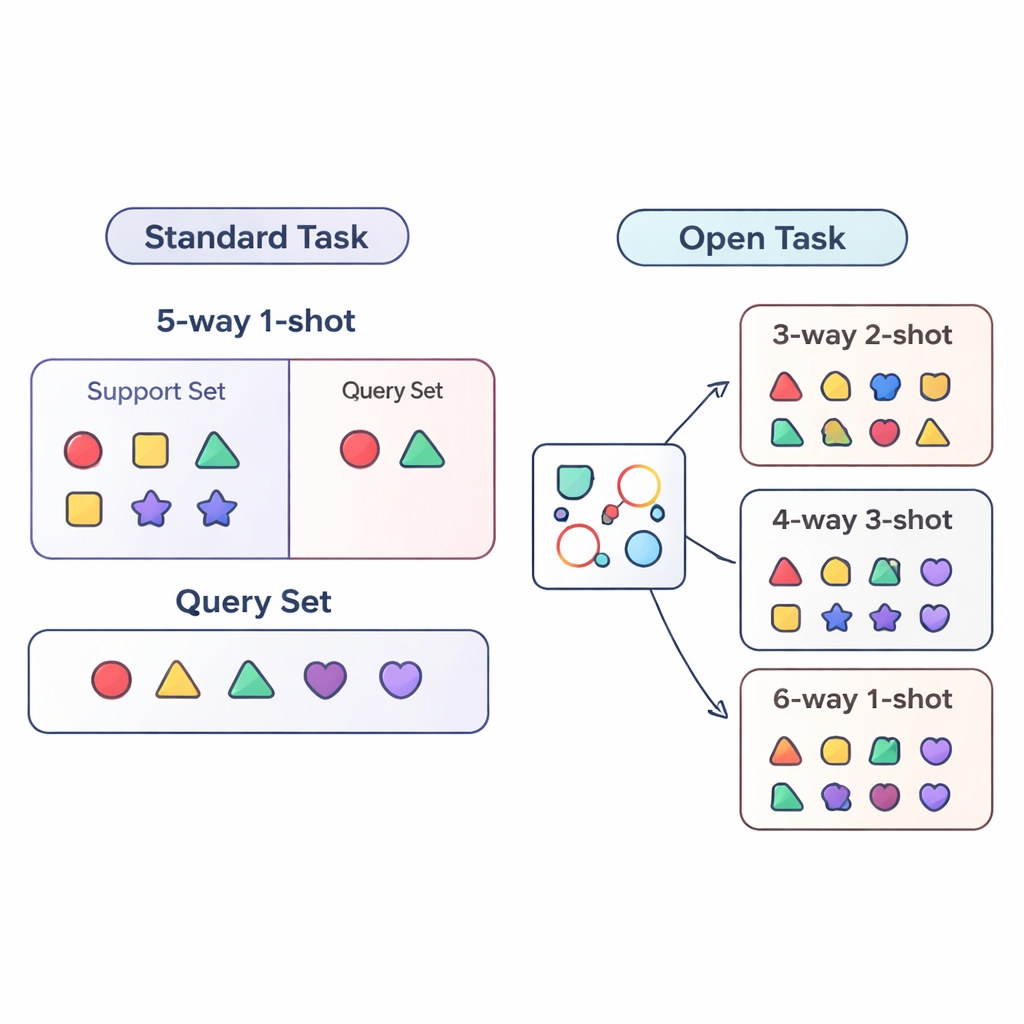
Przeprojektowanie sposobu testowania uczniów few-shot
Aby systematycznie zbadać świat otwartych zadań, artykuł proponuje trzy reżimy ewaluacji. W reżimie cross-way zmienia się tylko liczba klas: model może być trenowany na pięciu klasach, a testowany na trzech lub piętnastu. W reżimie cross-shot zmienia się liczba przykładów na klasę — od pojedynczego oznaczonego obrazu do kilku. Najtrudniejszy jest przypadek cross-way–cross-shot, gdzie jednocześnie zmienia się zarówno liczba klas, jak i ilość danych na klasę. Autorzy badają też, co się dzieje, gdy zmienia się styl wizualny danych — trenowanie na ogólnym zbiorze obiektów, a testowanie na szczegółowym zbiorze ptaków. Te ustawienia mają odsłonić, czy metoda potrafi rzeczywiście generalizować poza jedną, stałą recepturę treningową.
Jak Open-MAML dopasowuje się dynamicznie
Open-MAML bazuje na popularnej strategii meta-uczenia zwanej Model-Agnostic Meta-Learning (MAML), która trenuje model tak, by szybko adaptował się do nowego zadania przy użyciu kilku kroków gradientu. Standardowy MAML zakłada jednak, że liczba kategorii podczas testów jest zgodna z treningiem i używa stałej końcowej warstwy klasyfikującej. Open-MAML wprowadza trzy kluczowe modyfikacje, które przełamują to ograniczenie. Po pierwsze, stosuje dynamiczne tworzenie klasyfikatora: gdy nowe zadanie ma więcej klas niż wcześniej, tworzy dodatkowe jednostki wyjściowe przez skopiowanie średniej istniejących, dając modelowi neutralny, ale sensowny punkt startu. Po drugie, dostosowuje wewnętrzną szybkość uczenia w zależności od liczby klas i przykładów zadania, tak aby adaptacja pozostała stabilna niezależnie od tego, czy danych jest mało, czy dużo. Po trzecie, dodaje regularizator nazwany AdaDropBlock, który tymczasowo ukrywa przyległe obszary w mapach cech podczas treningu, skłaniając model do wykorzystywania bardziej zróżnicowanych wskazówek wizualnych zamiast dopasowywania się do drobnych, kruchych detali. 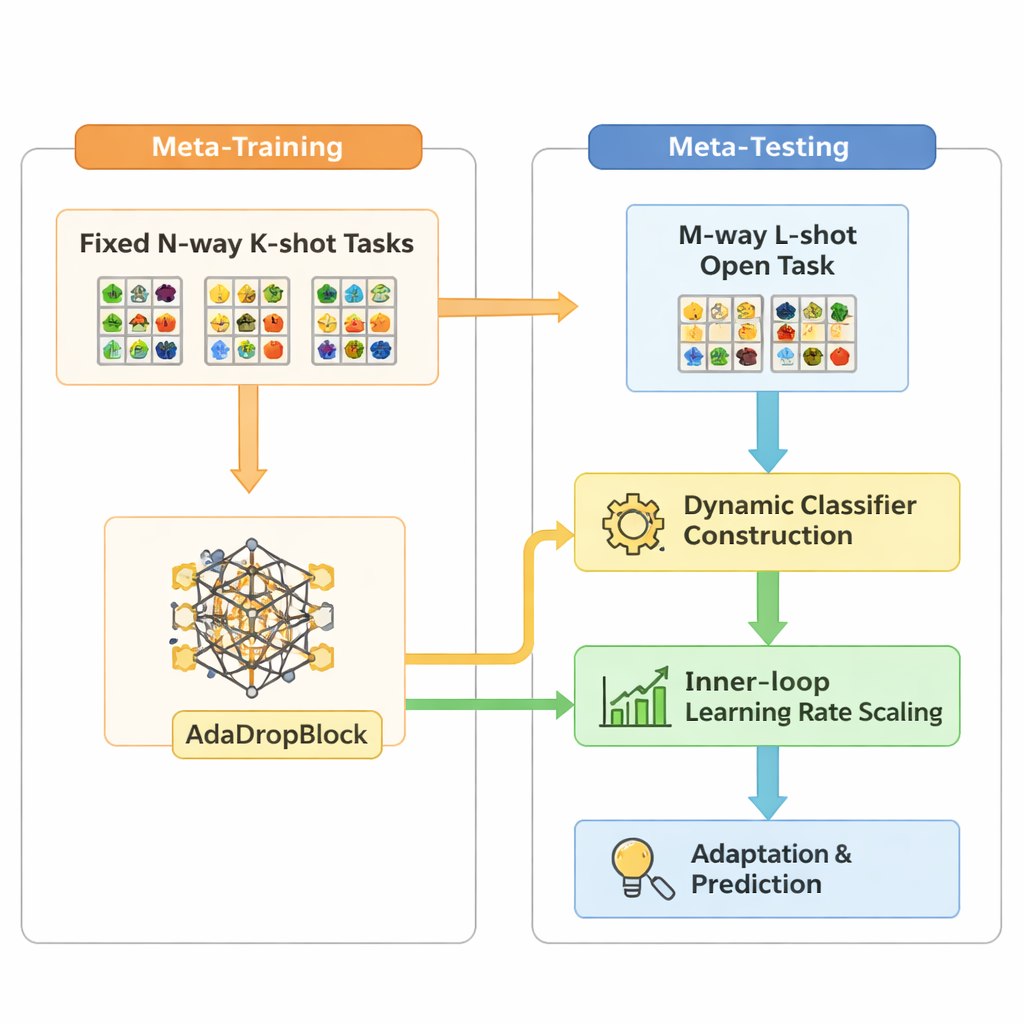
Wystawienie elastycznego uczenia na próbę
Naukowcy oceniają Open-MAML na standardowych benchmarkach few-shot oraz w nowych scenariuszach open-task, porównując go z kilkoma znanymi bazowymi metodami. Są wśród nich modele trenowane od zera dla każdego zadania, modele wykorzystujące silny wstępnie wytrenowany ekstraktor cech z dopasowywanym klasyfikatorem oraz metody oparte na metrykach, które klasyfikują obrazy na podstawie odległości do „prototypów” klas. Wszystkie metody korzystają z tej samej sieci bazowej, aby różnice wynikały ze strategii uczenia, a nie z architektury. Na dziesiątkach tysięcy zadań testowych Open-MAML konsekwentnie osiąga wyższą dokładność — zwykle o 1–7 punktów procentowych lepiej, gdy zmienia się tylko liczba klas lub przykładów, i o 3–6 punktów lepiej, gdy oba te czynniki się zmieniają. Zyski są jeszcze bardziej widoczne w trudniejszych ustawieniach z większą liczbą klas, większą liczbą przykładów lub przy przejściu do zbioru ptaków, co sugeruje, że mechanizmy adaptacyjne rzeczywiście pomagają w złożonym, nieznanym terenie.
Co to oznacza dla systemów SI w praktyce
Dla ogólnego czytelnika główne przesłanie jest takie: nie wszystkie systemy uczące się z nielicznymi przykładami są sobie równe, gdy wyjdziemy poza komfortowe warunki laboratorium. Metoda, która błyszczy na jednym, stałym benchmarku, może zawodzić, gdy zmienia się liczba kategorii lub ilość oznaczonych danych. Open-MAML pokazuje, że przez jawne przygotowanie się na takie strukturalne zmiany — pozwolenie klasyfikatorowi na rozrost lub kurczenie się, skalowanie szybkości uczenia z wielkością zadania oraz regularizowanie cech w sposób niezależny od zadania — systemy SI mogą lepiej radzić sobie ze zmiennymi warunkami, z jakimi spotkają się w praktyce. W zastosowaniach takich jak obrazowanie medyczne, monitorowanie satelitarne czy inspekcja przemysłowa, gdzie zarówno zestaw kategorii, jak i dostępność etykiet są w ciągłym ruchu, tego typu odporność na otwarte zadania może uczynić uczenie z nielicznymi przykładami znacznie bardziej praktycznym poza starannie dobranymi benchmarkami badawczymi.
Cytowanie: Han, X., Shi, D., Wang, Z. et al. Meta-learning for few-shot open task recognition. Sci Rep 16, 5624 (2026). https://doi.org/10.1038/s41598-026-36291-x
Słowa kluczowe: uczenie z nielicznymi przykładami, meta-uczenie, rozpoznawanie otwartych zadań, klasyfikacja obrazów, generalizacja