Clear Sky Science · pl
IASUNet: ekstrakcja budynków oparta na ulepszonej uwadze Swin-UperNet
Dlaczego wykrywanie każdego budynku z kosmosu ma znaczenie
W miarę rozrastania się miast i postępujących zmian klimatu znajomość dokładnego położenia budynków — oraz tego, jak zmieniają się w czasie — stała się niezbędna. Od planowania bezpieczniejszych dzielnic i wykrywania nielegalnej zabudowy po wspieranie akcji ratunkowych po powodziach czy trzęsieniach ziemi, szczegółowe mapy budynków są dziś kluczowym elementem inteligentnych, odpornych miast. W artykule tym przedstawiono IASUNet — nowy system sztucznej inteligencji, który uczy się automatycznie wyodrębniać budynki z obrazów satelitarnych o wysokiej rozdzielczości z imponującą precyzją, nawet w złożonych, zatłoczonych scenach rzeczywistych.
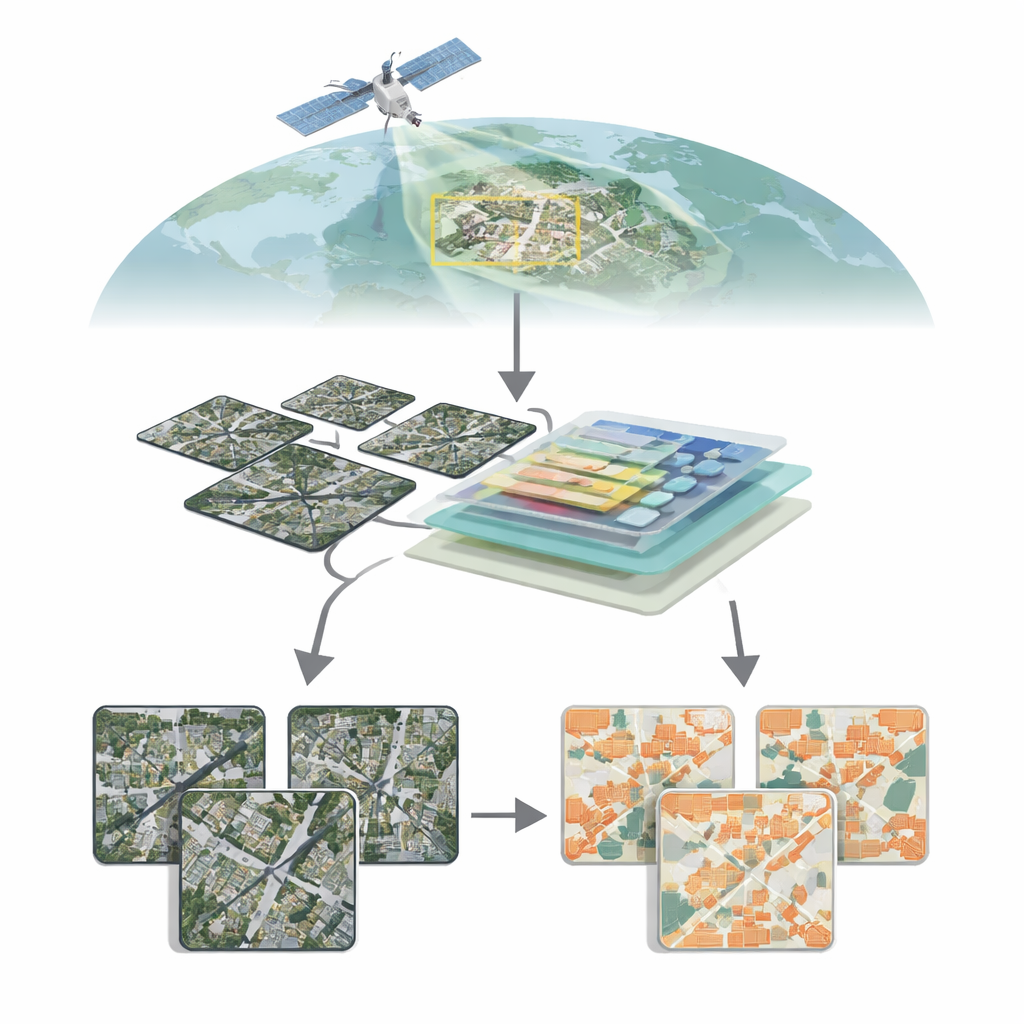
Obserwowanie miast z góry
Współczesne satelity mogą fotografować Ziemię w niezwykłym detalu, ukazując pojedyncze dachy, drogi, a nawet wąskie alejki. Przekształcenie tej masy pikseli w czyste mapy budynków jest jednak dalekie od trywialnego. Budynki bardzo różnią się rozmiarem, kształtem, kolorem i otoczeniem: szklane wieżowce w centrach miast, niskie domy na przedmieściach, rozrzucone zabudowania gospodarcze na wsi. Na terenach wiejskich lub mieszanych budynki mogą zajmować jedynie niewielki fragment obrazu, podczas gdy roślinność, gleba i woda dominują. Tradycyjne metody widzenia komputerowego, oparte głównie na sieciach konwolucyjnych, mogą mieć trudności z uchwyceniem szerokiego kontekstu całej sceny przy jednoczesnym zachowaniu precyzyjnych granic, co prowadzi do pomijania drobnych struktur lub rozmytych krawędzi.
Sprytniejsza uwaga na detale
IASUNet sprosta tym wyzwaniom, łącząc dwie silne koncepcje: enkoder oparty na Transformerze o nazwie Swin Transformer oraz elastyczny dekoder znany jako UperNet. Swin Transformer dzieli obraz na wiele małych fragmentów i uczy się, jak się one ze sobą odnoszą w całej scenie, zamiast patrzeć wyłącznie przez okno o stałym rozmiarze. Pomaga to modelowi zrozumieć szerszy kontekst — na przykład czy jasny prostokąt znajduje się wewnątrz gęstej miejskiej zabudowy, czy na odosobnionym polu — przy zachowaniu szczegółów. Do tego autorzy dodają mechanizm uwagi zwany Convolutional Block Attention Module (CBAM) na kilku etapach. CBAM uczy się, kanał po kanale i region po regionie, które cechy obrazu najprawdopodobniej należą do budynków, a które są tłem, wzmacniając te pierwsze i tłumiąc drugie, zanim dekoder złoży wszystko z powrotem w kompletną mapę budynków.
Równoważenie szans, gdy budynków jest mało
Kolejną praktyczną przeszkodą jest niezrównoważenie: na wielu satelitarnych scenach większość pikseli przedstawia drogi, pola, drzewa lub wodę, podczas gdy budynki zajmują jedynie małe wyspy. Standardowe metody treningowe mają tendencję do faworyzowania tego, co pojawia się najczęściej, co grozi tym, że model potraktuje rzadziej występujące budynki jako marginalne. Aby temu zaradzić, autorzy adaptują funkcję straty zwaną Focal Cross‑Entropy. Strategia ta zmniejsza wpływ „łatwych” pikseli tła i wzmacnia znaczenie trudniejszych do sklasyfikowania pikseli budynków podczas treningu. W rezultacie model zwraca większą uwagę na małe, słabo widoczne lub nietypowe obiekty, które mogłyby zostać pominięte, poprawiając czułość bez zalewu fałszywych alarmów.
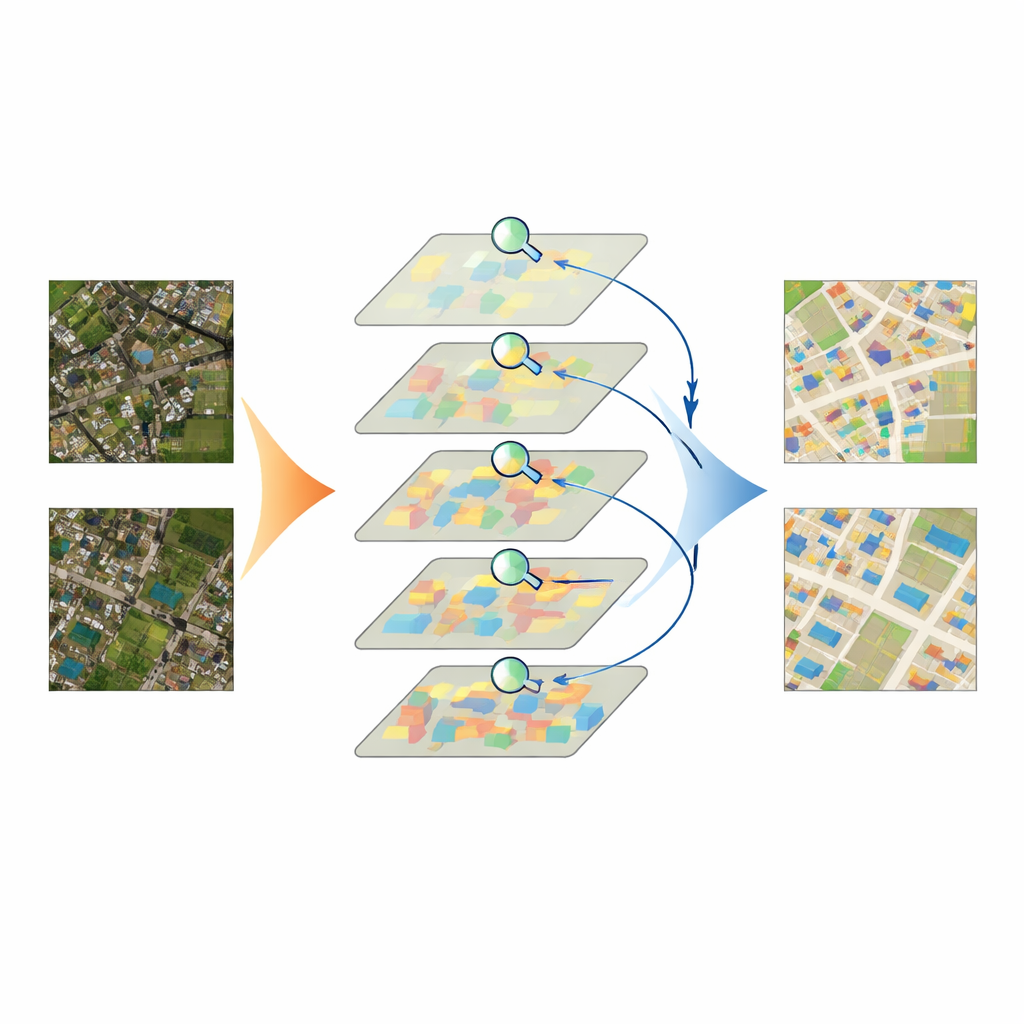
Testowanie modelu
Zespół przetestował IASUNet na trzech dobrze znanych zbiorach danych budynków z Niemiec, Nowej Zelandii i Stanów Zjednoczonych, a także na starannie przygotowanym i sprawdzonym jakościowo zbiorze obrazów satelitarnych z Chin, który sami opracowali. W tych benchmarkach IASUNet konsekwentnie dorównywał lub przewyższał wiodące podejścia, w tym silne sieci konwolucyjne i inne modele oparte na Transformerach. Na bardzo szczegółowym zbiorze Potsdam osiągnął niemal doskonałe pokrycie między przewidywanymi a rzeczywistymi obszarami budynków, zachowując jednocześnie praktyczne prędkości działania na nowoczesnym sprzęcie graficznym. Nawet na bardziej nieregularnych krajobrazach, gdzie budynki są rozproszone, częściowo ukryte lub ciasno upakowane, IASUNet rysował czyściejsze kontury, wychwytywał więcej małych obiektów i unikał wielu pominięć oraz błędów granicznych widocznych w metodach konkurencyjnych.
Od pikseli do lepszych miast
Mówiąc prościej, badanie pokazuje, że możemy teraz nauczyć komputery czytać panoramy miejskie z orbity z bezprecedensową przejrzystością. Poprzez umiejętne kierowanie „uwagi” modelu na właściwe części obrazu i świadome ważenie rzadkich, lecz kluczowych pikseli budynków, IASUNet przekształca surowe zdjęcia satelitarne w dokładne, aktualne mapy zabudowy przy niewielkim dodatkowym koszcie obliczeniowym. Takie mapy mogą zasilać planowanie miejskie, badania energetyczne i zjawiska „wyspy ciepła”, regulacje użytkowania terenu oraz szybkie oceny szkód po katastrofach. Choć praca jest w swej istocie techniczna, jej wniosek jest prosty: mądrzejsza sztuczna inteligencja może dać decydentom ostrzejszy, bardziej wiarygodny obraz zabudowanego środowiska, pomagając miastom rozwijać się w bezpieczniejszy i bardziej zrównoważony sposób.
Cytowanie: Zhang, H., Ma, Y., Wang, G. et al. IASUNet: building extraction based on impoved attention Swin-UperNet. Sci Rep 16, 7969 (2026). https://doi.org/10.1038/s41598-026-36270-2
Słowa kluczowe: teledetekcja, ekstrakcja budynków, segmentacja semantyczna, siecże transformatorowe, mapowanie miejskie