Clear Sky Science · pl
Dialektyczna substytucja jako podejście przeciwnika do oceny odporności przetwarzania języka arabskiego
Dlaczego codzienny arabski myli inteligentne komputery
Wiele aplikacji potrafi dziś czytać teksty po arabsku, by ocenić sentyment, sortować wiadomości czy odpowiadać na pytania. Tymczasem systemy te uczone są głównie na Nowoczesnym Standardowym Arabskim (MSA), podczas gdy ludzie na co dzień mieszają go z regionalnymi dialektami. Artykuł pokazuje, jak zamiana tylko jednego słowa na egipskie lub zatokowe arabskie potrafi zmylić nowoczesne modele językowe, co budzi obawy u wszystkich korzystających z arabskiej sztucznej inteligencji w obsłudze klienta, monitoringu mediów czy zapewnianiu bezpieczeństwa w sieci.
Jeden język, wiele głosów
Arabski nie jest jednolitym sposobem mówienia. MSA używany jest w szkołach, wiadomościach i oficjalnych pismach, ale codzienne rozmowy opierają się na dialektach, takich jak arabski egipski czy zatokowy. Te odmiany różnią się słownictwem, formami wyrazów, a nawet składnią zdań. Na przykład proste słowo „teraz” ma różne formy w różnych regionach. Dla ludzkich czytelników te warianty są naturalne i łatwe do zrozumienia. Dla modeli uczonych prawie wyłącznie na MSA słowa dialektalne mogą wyglądać obco, zamieniając jasne zdanie w coś zagadkowego.
Przekształcanie dialektów w test odporności AI
Aby sprawdzić, jak kruche są modele językowe dla arabskiego, autor proponuje prosty, dwuetapowy test. Najpierw model jest wielokrotnie zapytywany, by odnaleźć pojedyncze słowo w zdaniu, które ma największe znaczenie dla jego decyzji — często jest to mocne przymiotnik, kluczowe czasownik lub istotny rzeczownik. Po drugie, to jedno słowo jest zastępowane odpowiednikiem z arabskiego egipskiego lub zatokowego za pomocą dużego, starannie dopracowanego modelu „dialektyzującego”. Reszta zdania pozostaje niezmieniona, a dla ludzkiego czytelnika znaczenie pozostaje takie samo. To sprawia, że zmienione zdanie jest realistycznym przykładem adwersarialnym: drobna, naturalnie wyglądająca modyfikacja stworzona, by oszukać system bez zmiany przekazu.
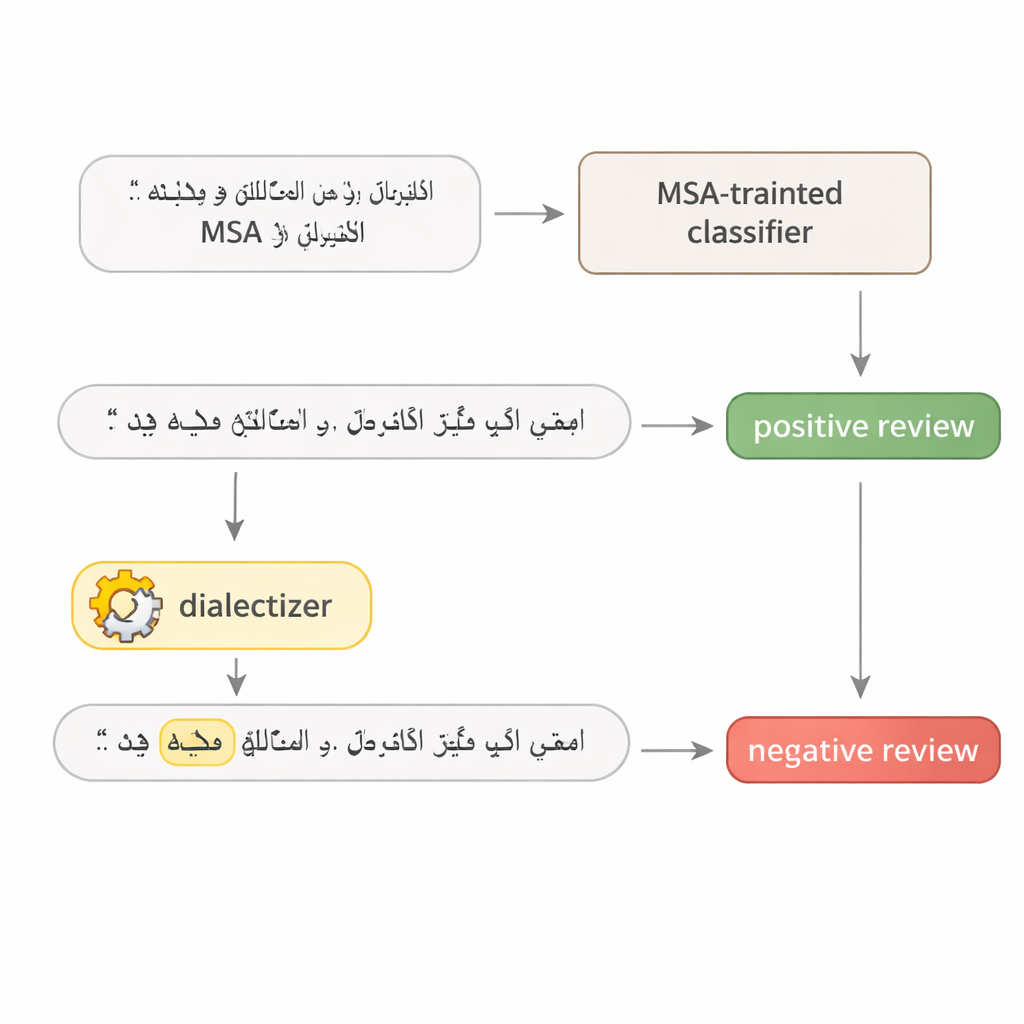
Testowanie recenzji hotelowych i artykułów prasowych
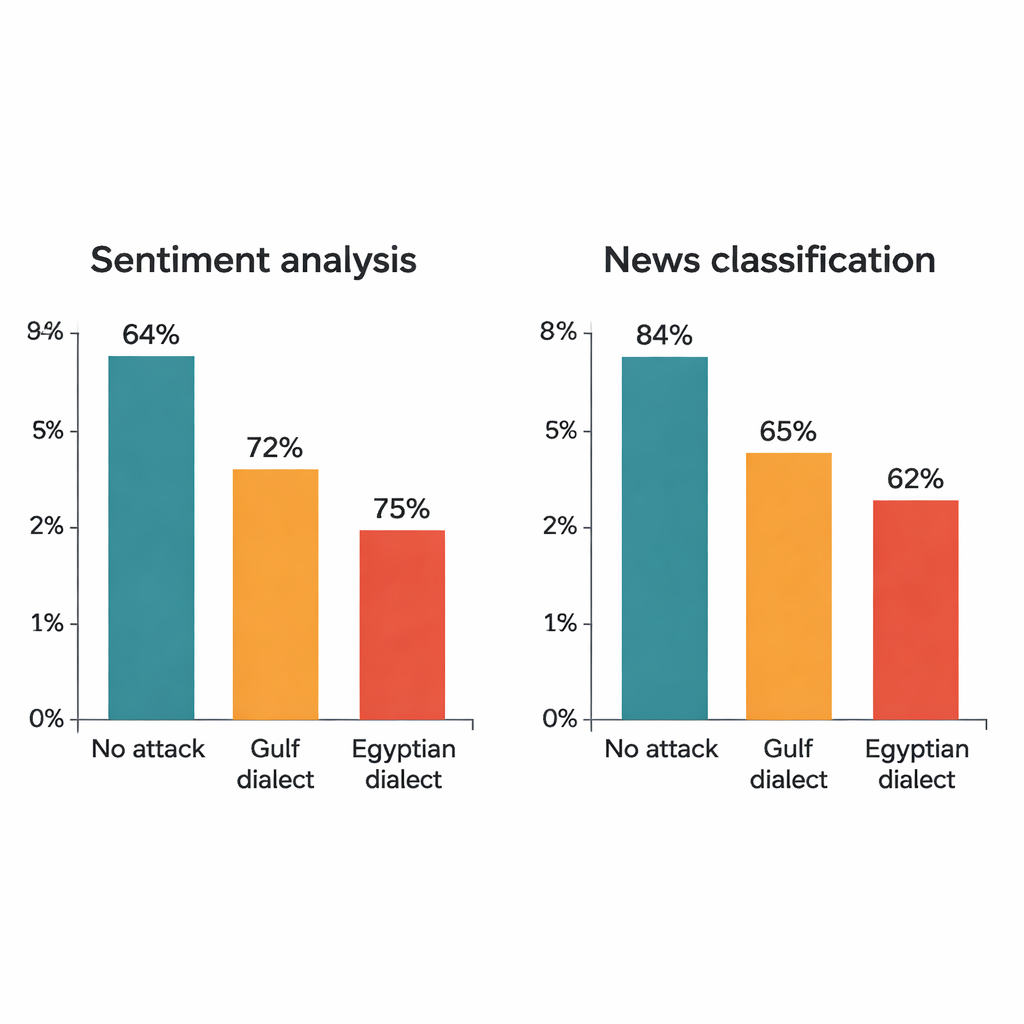
Badanie atakuje cztery znane modele głębokiego uczenia: dwa duże modele transformatorowe (AraBERT i CAMeLBERT) oraz dwie mniejsze sieci (model konwolucyjny i dwukierunkowy LSTM). Zostały one wytrenowane na dwóch głównych zbiorach MSA: recenzjach hotelowych do analizy sentymentu oraz artykułach prasowych do klasyfikacji tematów. Z każdego zestawu testowego autor pobiera 1280 przykładów i stosuje procedurę substytucji dialektalnej. Mimo że w każdym zdaniu zmieniane jest tylko jedno słowo, wpływ jest uderzający. W recenzjach hotelowych dokładność AraBERT spada z 94 procent na czystym tekście do około 72 procent przy substytucjach zatokowych i 65 procent przy egipskich. CAMeLBERT wypada jeszcze gorzej, spadając do około 63 i 55 procent. Klasyfikatory wiadomości także cierpią: model konwolucyjny traci około 18–22 punkty procentowe, a LSTM wykazuje podobne spadki.
Co idzie nie tak wewnątrz modeli
Bliższe przyjrzenie się ujawnia, że najbardziej wrażliwe słowa pokrywają się z tym, jak ludzie faktycznie czytają tekst. W recenzjach hotelowych niemal połowa atakowanych słów to przymiotniki, takie jak „dobry” czy „okropny”, niosące wyraźny ładunek emocjonalny. W artykułach prasowych większość wybranych słów to rzeczowniki i nazwy sygnalizujące tematy takie jak polityka, sport czy finanse. Gdy te wywołujące słowa zostają zastąpione formami dialektalnymi, modele uczone wyłącznie na MSA często nie potrafią ich rozpoznać. Modele transformatorowe okazują się szczególnie kruche: ich zależność od fragmentów podwyrazów i uwaga skoncentrowana na kilku silnie ocenionych tokenach sprawiają, że jedno dialektalne słowo wystarcza, by odwrócić predykcję. Mniejsze modele, które rozkładają uwagę bardziej równomiernie po zdaniu, również dają się oszukać, ale są nieco bardziej odporne.
Egipski kontra zatokowy: nie wszystkie dialekty są równe
Ataki pokazują także, że arabski egipski częściej wyprowadza modele z równowagi niż arabski zatokowy. Badania lingwistyczne to potwierdzają: odmiany zatokowe często są bliższe MSA pod względem słownictwa i struktury, podczas gdy arabski egipski przyswoił więcej odrębnych form w wyniku historii i kontaktów z innymi językami. W efekcie substytucje zatokowe czasem przypominają oryginalne MSA na tyle, że model potrafi sobie z nimi poradzić, podczas gdy egipskie zamienniki częściej wykraczają poza to, czego model wcześniej widział. Testy statystyczne potwierdzają, że zaobserwowane spadki wydajności nie są przypadkowe — odzwierciedlają systemowe luki w sposobie, w jaki obecne systemy radzą sobie z diglosją arabską.
Co to oznacza dla arabskiej sztucznej inteligencji
Dla codziennych użytkowników wniosek jest prosty: dzisiejsza arabska AI może być łatwo zmylona przez zwykłe słowa dialektalne, nawet gdy ludzie uważają tekst za całkowicie zrozumiały. Jedno dialektalne słowo w recenzji hotelu może zmienić ocenę modelu z pozytywnej na negatywną albo błędnie oznaczyć temat artykułu prasowego. Dla badaczy i deweloperów przesłanie to wezwanie do budowy systemów „świadomych diglosji”, które uczą się zarówno MSA, jak i regionalnych dialektów, oraz do stosowania realistycznych testów obciążeniowych, takich jak substytucja dialektalna, przy ocenie odporności. Dopóki tego nie zrobimy, każda aplikacja zakładająca, że „arabski to tylko MSA”, naraża się na poważne nieporozumienia w praktyce.
Cytowanie: Alshemali, B. Dialectal substitution as an adversarial approach for evaluating Arabic NLP robustness. Sci Rep 16, 5996 (2026). https://doi.org/10.1038/s41598-026-36252-4
Słowa kluczowe: Przetwarzanie języka arabskiego, wariacja dialektalna, przykłady adwersarialne, analiza sentymentu, klasyfikacja tekstu