Clear Sky Science · pl
Optymalizacja predykcji śmiertelności w sepsie przy użyciu hybrydowego federacyjnego uczenia i wyjaśnialnej sztucznej inteligencji
Dlaczego śmiertelne infekcje wciąż zaskakują szpitale
Sepsa jest jednym z najgroźniejszych stanów nagłych we współczesnej medycynie. Rutynowa infekcja — z dróg moczowych, płuc czy nawet skóry — może nagle wywołać reakcję ogólnoustrojową, która zatrzymuje pracę narządów i prowadzi do zgonu w ciągu kilku godzin. Lekarze wiedzą, że wczesne działanie ratuje życie, jednak wykrycie pacjentów, którzy mają wkrótce popaść w ciężki stan, pozostaje trudne. W tym badaniu autorzy badają, jak nowe połączenie prywatności‑chroniącej sztucznej inteligencji i „szkatułkowych” wyjaśnień mogłoby pomóc szpitalom wcześniej identyfikować pacjentów z wysokim ryzykiem sepsy, nie narażając jednocześnie na ujawnienie wrażliwych danych medycznych.
Od prostych wykresów punktowych do inteligentnych, łaknących danych narzędzi
Dotąd wiele szpitali polegało na listach kontrolnych i systemach punktacji, takich jak SOFA i qSOFA. Narzędzia te obserwują kilka podstawowych pomiarów — np. ciśnienie krwi i częstość oddechów — i dają przybliżone wyobrażenie o stanie pacjenta. Często jednak stosowane są zbyt późno i pomijają bogate strumienie informacji przechowywane dziś w elektronicznych kartach pacjentów i monitorach przy łóżku. W efekcie mogą przeoczyć złożone wzorce zapowiadające niewydolność narządów i zgon związany z sepsą. Badacze zwrócili się ku uczeniu maszynowemu, które potrafi przesiać tysiące danych na pacjenta, ale ta zmiana przynosi dwa nowe problemy: szpitale niechętnie łączą surowe dane z obawy przed naruszeniem prywatności, a wiele zaawansowanych modeli działa jak nieprzejrzyste „czarne skrzynki”, którym klinicyści trudno zaufać.
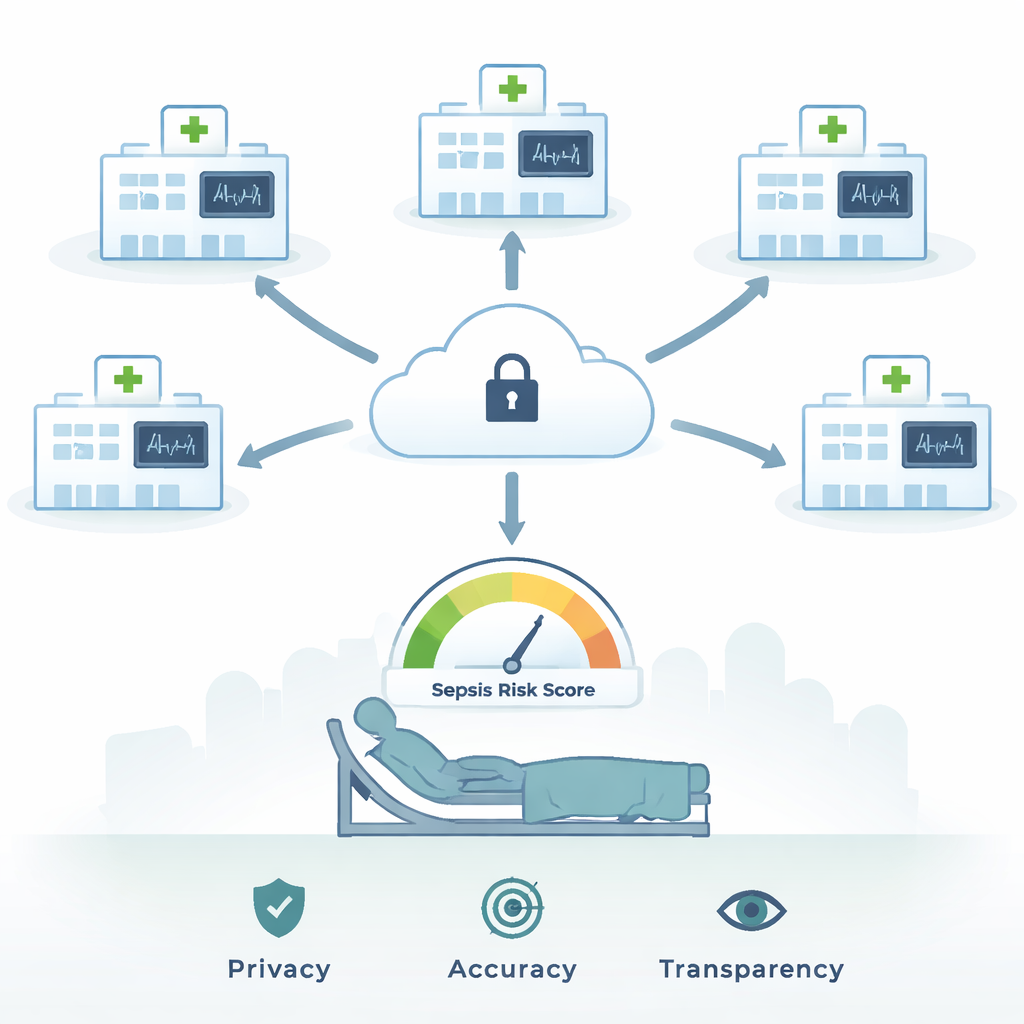
Sieć szpitali uczących się bez dzielenia się sekretami
Autorzy proponują ramy, które rozwiązują jednocześnie problemy prywatności i zaufania. Wykorzystują federacyjne uczenie, strategię, w której każdy szpital trenuje ten sam zestaw modeli predykcyjnych na własnych danych z oddziału intensywnej terapii — tętno, ciśnienie krwi, poziomy tlenu, badania laboratoryjne i inne — nie wysyłając nigdy rekordów pacjentów do centralnego serwera. Zamiast tego jedynie aktualizacje modelu są bezpiecznie łączone w chmurze, tworząc silniejszy model globalny. W ten sposób system uczy się na dużej i zróżnicowanej puli pacjentów, jednocześnie utrzymując ich zapisy w obrębie zapór każdej instytucji. Aby model nie nauczył się po prostu, że „większość pacjentów przeżywa”, zespół dodatkowo zrównoważył dane tak, by przypadki śmiertelne i nieśmiertelne sepsy były reprezentowane bardziej równomiernie, stosując technikę tworzenia realistycznych syntetycznych przykładów rzadszego wyniku.
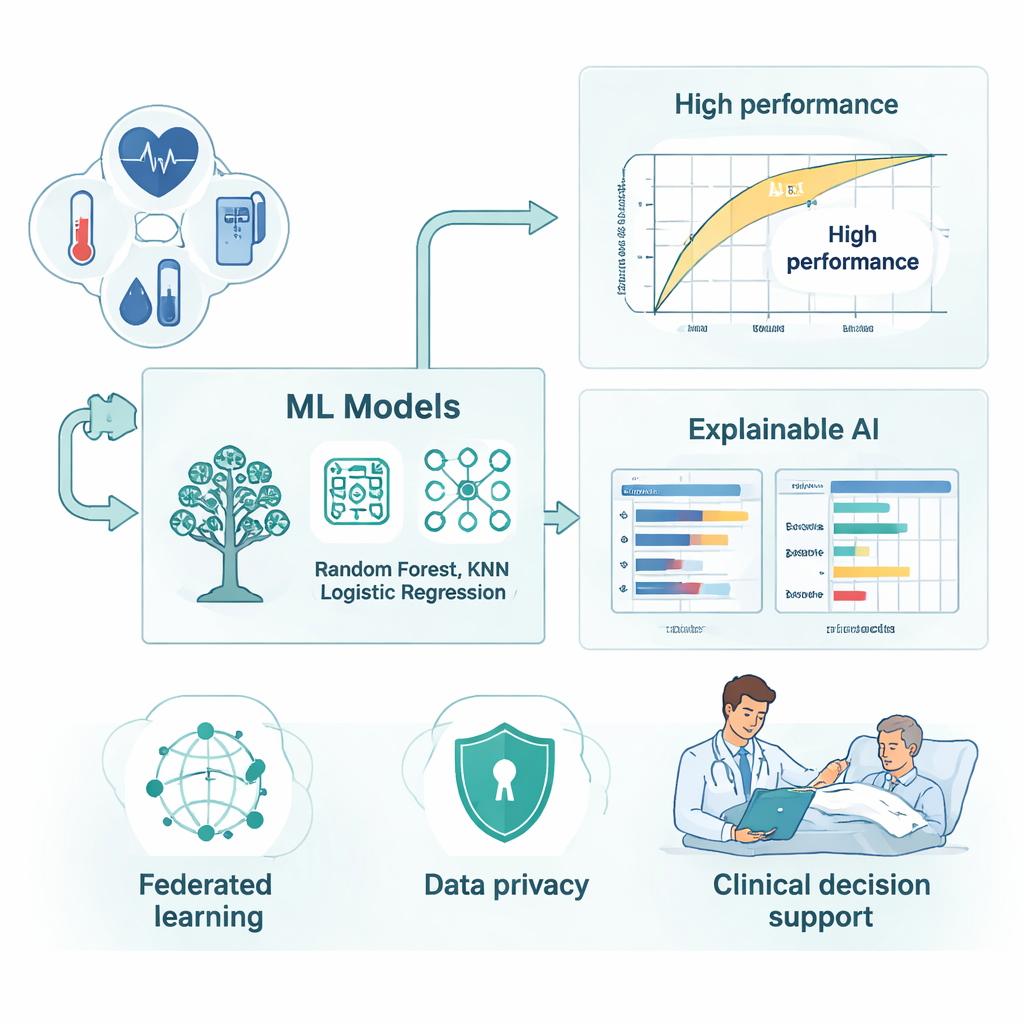
Otwarcie czarnej skrzynki dla lekarzy przy łóżku
W ramach tego federacyjnego układu badacze przeszkolili kilka dobrze znanych modeli uczenia maszynowego, w tym Random Forest, LightGBM, XGBoost, K‑Nearest Neighbors oraz regresję logistyczną. Następnie opakowali te modele w warstwę „wyjaśnialnej AI”, zaprojektowaną tak, by pokazywać nie tylko wynik ryzyka, lecz także uzasadnienie stojące za nim. Narzędzia takie jak SHAP i LIME rozkładają każdą prognozę na wkłady poszczególnych cech klinicznych — o ile wzrost częstości oddechów, dłuższy pobyt na intensywnej terapii czy spadek wysycenia tlenem przesuwają pacjenta w stronę kategorii wysokiego ryzyka. Wykresy zależności częściowej dają szerszy obraz, ujawniając na przykład, jak przewidywane ryzyko rośnie stopniowo, gdy częstość oddechów lub długość pobytu przekraczają określone progi. Te wyjaśnienia pomagają klinicystom ocenić, kiedy ostrzeżenie modelu pokrywa się z ich własnym osądem, a kiedy może reagować na ukryte trendy w danych, które wymagają bliższej uwagi.
Dobra skuteczność bez poświęcania prywatności
Wykorzystując dużą, publicznie dostępną bazę danych sepsy zbudowaną z zapisów oddziałów intensywnej terapii, zespół przetestował swoje podejście zarówno w tradycyjnym scentralizowanym treningu, jak i w bardziej realistycznym ustawieniu federacyjnym. Modele zespołowe — szczególnie Random Forest i metody boostingowe — wyróżniały się najlepiej. W przypadku scentralizowanym najlepszy model poprawnie sklasyfikował niemal wszystkich pacjentów i osiągnął bliską perfekcji dyskryminację między ocalałymi a zmarłymi. Gdy te same modele trenowano w symulowanej sieci pięciu wirtualnych szpitali o różnym składzie pacjentów, wydajność spadła tylko nieznacznie, pozostając nadal bardzo wysoka. Ten niewielki kompromis przyniósł jednak znaczące korzyści w zakresie prywatności i niezależności instytucjonalnej: żadne surowe dane pacjentów nie opuściły lokalnych serwerów, a system wciąż wykrywał zdecydowaną większość przypadków wysokiego ryzyka.
Co to oznacza dla pacjentów i klinicystów
Dla osoby niezwiązanej ze specjalistyczną dziedziną wniosek jest prosty: pozwalając szpitalom „uczyć się razem” bez udostępniania ich rzeczywistych kart oraz zmuszając komputer do pokazywania swoich rozumowań, te ramy przybliżają potężną predykcję ryzyka sepsy do zastosowań praktycznych. Lekarze mogliby otrzymywać wczesne, wyjaśnialne alerty, że infekcja pacjenta przechyla się w stronę niewydolności narządów, poparte jasnymi wskazówkami, które parametry życiowe i wyniki badań laboratoryjnych generują to ostrzeżenie. Według badania taki system może pozostać dokładny nawet przy surowych zasadach prywatności i zróżnicowanych warunkach szpitalnych. Jeśli zostanie zweryfikowany w warunkach klinicznych na żywo, ta hybryda federacyjnego uczenia i wyjaśnialnej AI może stać się ważną siecią bezpieczeństwa na oddziałach intensywnej terapii, wykrywając więcej pacjentów z sepsą, zanim będzie za późno.
Cytowanie: Fuzail, M.Z., Din, I.u., Ahmed, S. et al. Optimizing sepsis mortality prediction using hybrid federated learning and explainable AI framework. Sci Rep 16, 5218 (2026). https://doi.org/10.1038/s41598-026-36245-3
Słowa kluczowe: sepsa, predykcja śmiertelności, federacyjne uczenie, wyjaśnialna sztuczna inteligencja, oddział intensywnej terapii