Clear Sky Science · pl
Modelowanie kontekstu o długim zasięgu do wykrywania podatności w oprogramowaniu przy użyciu podejścia opartego na XLNet
Dlaczego ukryte błędy w oprogramowaniu mają znaczenie
Współczesne życie opiera się na oprogramowaniu — od bankowości internetowej i systemów szpitalnych po odtwarzacze wideo i aplikacje czatu. Nawet drobne błędy w kodzie mogą jednak otworzyć drzwi dla włamywaczy, narażając dane na kradzież lub powodując przerwy w usługach. Specjaliści od bezpieczeństwa coraz częściej sięgają po sztuczną inteligencję, aby przeskanować miliony linii kodu w poszukiwaniu takich słabości. W artykule opisano nową metodę opartą na SI, nazwaną XLNetVD, zaprojektowaną do wykrywania subtelnych podatności poprzez analizę znacznie dłuższych fragmentów kodu niż wiele istniejących narzędzi.
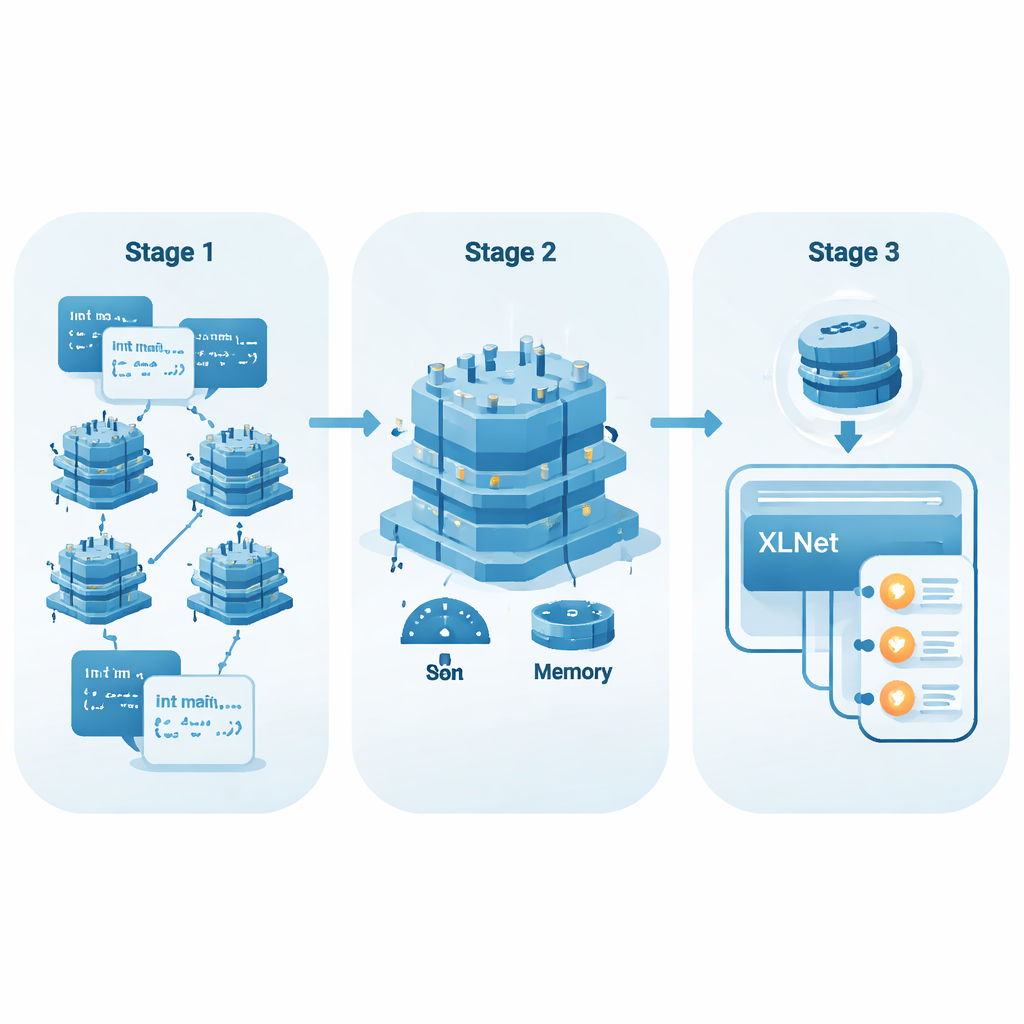
Od prostych list słów do kodu rozumiejącego kontekst
Pierwsze metody AI analizujące kod traktowały każdy token — na przykład nazwę zmiennej czy symbol — niemal jak słowo ze stałym znaczeniem. Techniki takie jak Word2Vec czy GloVe uczyły jednego wektora na token, niezależnie od kontekstu wystąpienia. To działa w miarę dobrze w przypadku języka naturalnego, ale zawodzą w programach, gdzie ta sama nazwa zmiennej może zachowywać się zupełnie inaczej w zależności od miejsca i sposobu użycia. Nowsze modele, zwane kontekstowymi osadzeniami, analizują całą funkcję naraz i dostosowują reprezentację każdego tokena do jego otoczenia. Pozwala to wychwycić wzorce związane z przepływem danych, sterowaniem i zależnościami między zmiennymi — wzorce, które często decydują o tym, czy kod jest bezpieczny czy nie.
Pozwolenie SI na czytanie większej części pliku
Popularne modele do pracy z kodem, takie jak CodeBERT i GraphCodeBERT, również stosują podejście uwzględniające kontekst, ale zwykle ograniczają swoją „perspektywę” do około 512 tokenów. Dla długich funkcji lub podatności sygnalizowanych przez odległe fragmenty kodu takie okno może być zbyt krótkie. Istotne kontrole blisko początku funkcji mogą zostać odcięte od ryzykownych operacji pod koniec. Autorzy oparli się zamiast tego na XLNet, modelu bazującym na Transformer-XL, który potrafi pamiętać informacje między segmentami i komfortowo przetwarzać dłuższe sekwencje (w ich eksperymentach do 768 tokenów). Dzięki temu lepiej łączy odległe zdarzenia w kodzie — na przykład rozumie, że wartość została wcześniej sprawdzona, albo stwierdza, że nigdy nie została.
Uczynienie potężnych modeli lżejszymi i szybszymi
Duże modele SI często wymagają wydajnego sprzętu, co ogranicza ich zastosowanie w codziennych środowiskach programistycznych. Aby temu zaradzić, autorzy zastosowali metodę do-dostrajania zwaną Low-Rank Adaptation (LoRA). Zamiast modyfikować wszystkie liczne parametry XLNet, LoRA dodaje małe warstwy adapterów, które są znacznie tańsze w trenowaniu i przechowywaniu. Zespół wprowadza prosty wskaźnik, EffScore, który waży oszczędności pamięci i czasu względem ewentualnego spadku jakości wykrywania. W testach na kilku wiodących modelach XLNet z LoRA wychodzi jako najbardziej wydajny całościowo, oferując silną dokładność przy znacznie mniejszym zużyciu zasobów.
Testy na rzeczywistych i syntetycznych projektach
Naukowcy ocenili XLNetVD na dwóch bardzo różnych zestawach danych. Jeden zawiera rzeczywisty kod C z 12 projektów open-source — takich jak biblioteki multimedialne i serwery WWW — z wyraźnie zniekształconym stosunkiem około 1 funkcji podatnej na 65 niepodatnych, co odzwierciedla rzeczywistość dużych baz kodu. Drugi to zbalansowany, syntetyczny zbiór z projektu SARD, gdzie każda funkcja została opracowana tak, by reprezentować znany typ słabości. XLNetVD nie tylko dorównuje lub przewyższa wcześniejsze systemy uczące się głęboko i klasyczne narzędzia analizy statycznej w tych testach, lecz także sprawdza się w ustawieniach międzyporjektowych, gdzie musi wykrywać błędy w nieznanym wcześniej projekcie. Jego przewaga jest szczególnie wyraźna dla długich funkcji, gdzie dłuższy kontekst ma kluczowe znaczenie, oraz w różnych kategoriach podatności, w tym przepełnienia całkowitoliczbowe, nieprawidłowe zarządzanie zasobami i nieodpowiednie przetwarzanie danych wejściowych.
Co to oznacza dla codziennego bezpieczeństwa oprogramowania
Dla osoby niebędącej specjalistą zasadniczy wniosek jest taki, że bardziej inteligentna, świadoma kontekstu SI potrafi czytać i rozumować o kodzie bardziej jak doświadczony recenzent, ale w skali maszynowej. Pozwalając modelowi zobaczyć większą część każdej funkcji i dobierając go efektywnie, XLNetVD daje praktyczny sposób priorytetyzacji fragmentów ogromnej bazy kodu, które wymagają dokładniejszej kontroli przez człowieka. Nie zastępuje ręcznych audytów bezpieczeństwa ani metod formalnych i nie gwarantuje, że oprogramowanie jest wolne od błędów. Zwiększa jednak znacząco szanse na wykrycie niebezpiecznych błędów wcześnie, nawet w nieznanych projektach, co czyni go obiecującym elementem budowy bardziej niezawodnej i bezpiecznej infrastruktury cyfrowej.
Cytowanie: Zhao, Y., Lin, G. & Liao, Z. Long-range context modeling for software vulnerability detection using an XLNet-based approach. Sci Rep 16, 5338 (2026). https://doi.org/10.1038/s41598-026-36196-9
Słowa kluczowe: podatności oprogramowania, bezpieczeństwo kodu, uczenie głębokie, XLNet, do-dostrajanie LoRA