Clear Sky Science · pl
Zmodyfikowany uprzywilejowany algorytm DDPG do wspólnej optymalizacji formowania wiązki i faz RIS w systemach MISO downlink
Inteligentne powierzchnie na kolejną falę łączności bezprzewodowej
W miarę jak nasze telefony, samochody i czujniki wymagają coraz szybszych i bardziej niezawodnych połączeń, współczesne sieci bezprzewodowe są wystawiane na coraz większe obciążenia. W tej pracy badano nowy sposób, aby przyszłe sieci 6G były jednocześnie bardziej ekologiczne i bardziej niezawodne, łącząc „inteligentne” powierzchnie odbijające na budynkach z techniką sztucznej inteligencji, która uczy się samodzielnie, jak kierować sygnały radiowe przy mniejszym zużyciu energii.
Przekształcanie ścian w pomocne zwierciadła sygnału
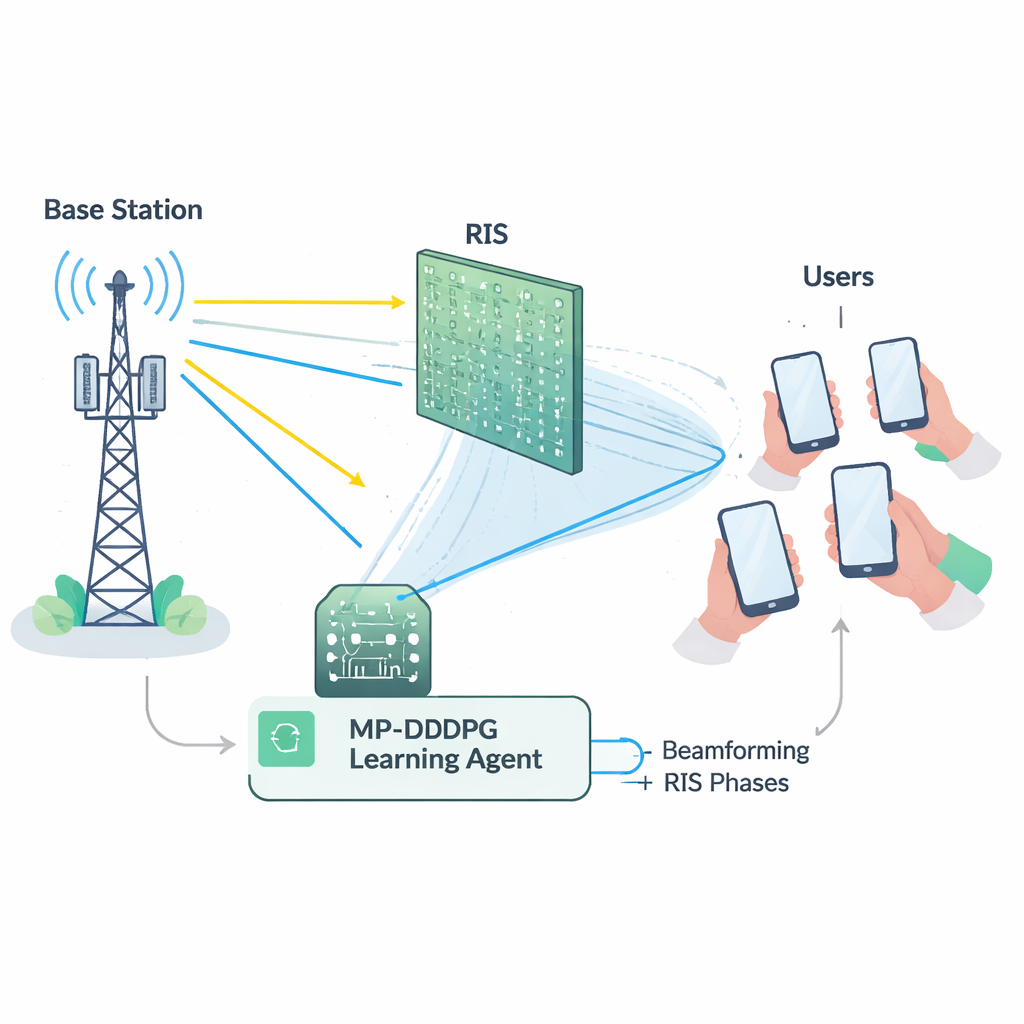
Przyszłe systemy 6G będą musiały obsługiwać ogromną liczbę urządzeń przy wysokich przepływnościach danych, ponadprzeciętnej niezawodności i bardzo niskich opóźnieniach. Spełnienie tych wymagań używając wyłącznie tradycyjnych stacji bazowych wymagałoby znacznego dodatkowego sprzętu i energii. Konfigurowalne powierzchnie inteligentne (RIS) oferują inne podejście: panele pokryte wieloma drobnymi, niskomocowymi elementami, które mogą odbijać padające fale radiowe w kontrolowanych kierunkach, działając jak programowalne zwierciadło. Poprzez staranny dobór faz odbić, RIS może kierować sygnały wokół przeszkód, wzmacniać słabe łącza i redukować interferencję, wszystko bez aktywnego nadawania własnej mocy. To daje projektantom sieci potężne nowe narzędzie do rozszerzania zasięgu i poprawy efektywności.
Trudna sztuka zachowania równowagi w sieci
Efektywne wykorzystanie RIS nie jest proste. Stacja bazowa musi zdecydować, jak skierować swoje anteny (formowanie wiązki), podczas gdy RIS musi ustawić fazę każdego z wielu elementów odbijających. Te wybory są ściśle powiązane i muszą jednocześnie spełniać kilka ograniczeń: utrzymać całkowitą moc nadawczą poniżej maksimum, zagwarantować każdemu użytkownikowi minimalną jakość sygnału oraz respektować fizyczne limity sprzętu RIS. Matematycznie taki problem wspólnej regulacji jest silnie nieliniowy i "niewypukły", co oznacza, że konwencjonalne narzędzia optymalizacyjne zwykle są wolne, kruche lub utkwią w rozwiąza‑niach suboptymalnych, szczególnie w większych sieciach. Dodatkowo dokładne pomiarowanie stanu każdego łącza radiowego (tzw. informacji o stanie kanału) samo w sobie jest kosztowne i podatne na błędy w rzeczywistych wdrożeniach.
Pozwolenie agentowi AI na naukę formowania wiązek
Aby pokonać te trudności, autorzy stworzyli agenta uczącego się z użyciem głębokiego uczenia ze wzmocnieniem, gałęzi AI, w której agent odkrywa dobre strategie poprzez próby i błędy w środowisku. Ich metoda, nazwana Zmodyfikowany Uprzywilejowany Głęboki Deterministyczny Gradient Polityki (MP‑DDPG), obserwuje bieżący stan sieci — wcześniejsze kierunki wiązek, ustawienia RIS, odbieraną moc i jakość sygnału — a następnie wybiera nowe wartości formowania wiązki i faz RIS. Po każdej decyzji otrzymuje nagrodę zachęcającą do trzech celów jednocześnie: niższej mocy nadawczej, spełnienia celów jakości obsługi dla użytkowników oraz przestrzegania limitu mocy stacji bazowej. W trakcie wielu symulowanych interakcji agent stopniowo uczy się polityki sterowania, która równoważy te cele bez konieczności jawnego podawania wzoru opisującego kanał radiowy.
Szybsza nauka przez skupienie na tym, co istotne
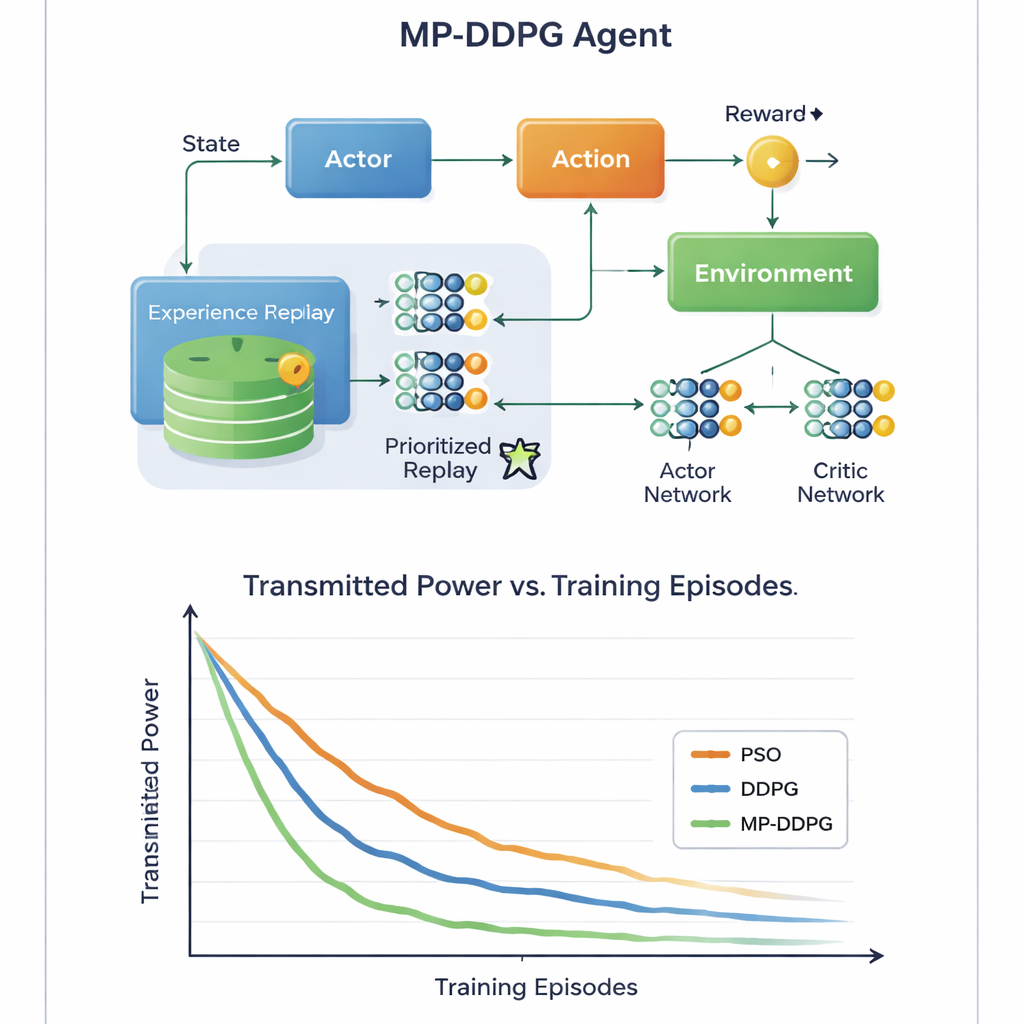
Kluczowa innowacja polega na sposobie, w jaki algorytm uczy się z przeszłych doświadczeń. Standardowe podejścia przechowują wiele wcześniejszych sytuacji i losowo je próbkują podczas treningu, co może być nieefektywne i wolne. MP‑DDPG zamiast tego przydziela każdemu zapisowi doświadczenia priorytet zależny zarówno od otrzymanej nagrody, jak i od tego, jak bardzo jego stan różni się od najbliższych sąsiadów. Doświadczenia, które są jednocześnie informacyjne i różnorodne, są pobierane częściej, podczas gdy redundantne są pomijane. Ta "zmodyfikowana uprzywilejowana pamięć odtwarzania" sprawia, że każdy krok uczenia jest bardziej użyteczny, przyspieszając zbieżność i pomagając agentowi unikać słabych lokalnych rozwiązań. Autorzy analizują też dodatkowe obciążenie obliczeniowe związane z tym podejściem i wykazują, że chociaż prowadzenie księgowości jest bardziej złożone niż w metodzie podstawowej, szybsze uczenie w praktyce więcej rekompensuje.
Bardziej ekologiczne sygnały przy mniejszym sprzęcie
Na podstawie szczegółowych symulacji komputerowych scenariusza downlinkowego, badanie porównuje MP‑DDPG z dwiema alternatywami: tradycyjną metodą optymalizacji rojem cząstek oraz oryginalnym algorytmem DDPG. Nowa metoda konsekwentnie osiąga niższą moc nadawczą w mniejszej liczbie epizodów treningowych, i robi to przy użyciu mniejszej liczby elementów RIS oraz mniejszej liczby anten stacji bazowej dla tego samego poziomu wydajności. Mówiąc prosto, sieć uczy się wyciągać większą korzyść z każdej płytki odbijającej i każdej anteny. Dla czytelnika niebędącego specjalistą przesłanie jest takie, że pozwalając kontrolerowi AI inteligentnie stroić zarówno wiązki stacji bazowej, jak i inteligentne powierzchnie na pobliskich ścianach, przyszłe sieci 6G mogłyby dostarczać silne, niezawodne sygnały przy mniejszym zużyciu energii i mniejszej ilości sprzętu, co pomaga uczynić nasz coraz bardziej połączony świat bardziej zrównoważonym.
Cytowanie: Shukry, S., Fahmy, Y. Modified prioritized DDPG algorithm for joint beamforming and RIS phase optimization in MISO downlink systems. Sci Rep 16, 5942 (2026). https://doi.org/10.1038/s41598-026-36179-w
Słowa kluczowe: konfigurowalna powierzchnia inteligentna, bezprzewodowe 6G, głębokie uczenie ze wzmocnieniem, optymalizacja formowania wiązki, sieci energooszczędne