Clear Sky Science · pl
Predykcja uzależnienia od jedzenia u studentów przy użyciu uczenia maszynowego na podstawie danych demograficznych, antropometrycznych i cech osobowości
Dlaczego nasza relacja z jedzeniem może wymykać się spod kontroli
Wiele osób żartuje, że jest „uzależnionych” od czekolady czy fast foodów, ale dla niektórych napady głodu i utrata kontroli nad jedzeniem są poważne i stresujące. Studenci są szczególnie narażeni — godzą stres, nowe wolności i zmiany w ciele. Badanie stawia istotne pytanie: czy programy komputerowe potrafią rozpoznać, którzy studenci są bardziej narażeni na uzależnienie od jedzenia, używając prostych informacji o ich tle, pomiarach ciała i cechach osobowości? Jeśli tak, moglibyśmy wcześniej wykrywać problemy i dostosowywać wsparcie, zanim nawyki żywieniowe przerodzą się w długotrwałe problemy zdrowotne.
Analiza studentów z wielu perspektyw
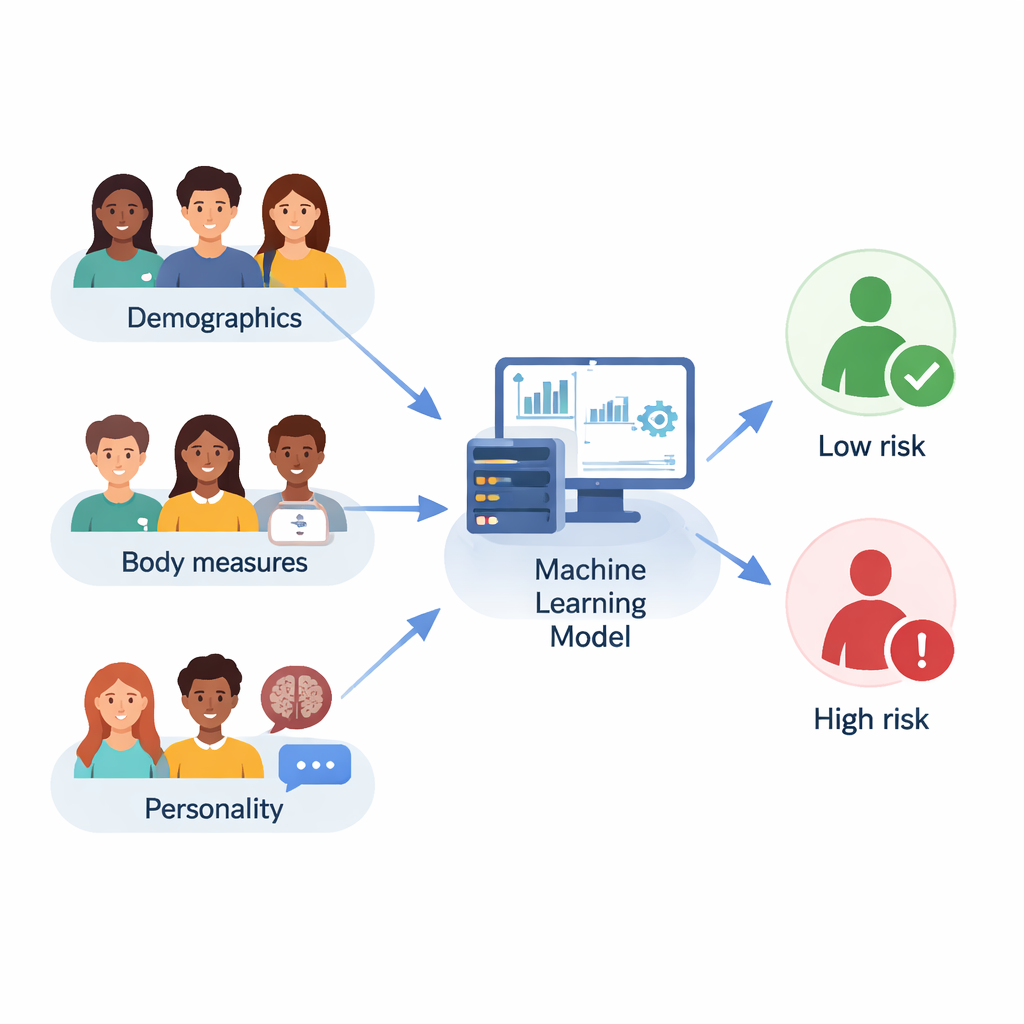
Naukowcy pracowali z 210 studentami z Ahwazu w Iranie w wieku 18–35 lat. Każdy student podał podstawowe dane, takie jak wiek i poziom wykształcenia, zgłosił wzrost i wagę, co pozwoliło obliczyć wskaźnik masy ciała (BMI), oraz wypełnił standardowy kwestionariusz osobowości. Przeprowadzono także krótkie badanie przy użyciu Yale Food Addiction Scale, które klasyfikuje, czy ktoś wykazuje zachowania podobne do uzależnienia wobec wysoko smakowitych produktów — np. silne napady głodu, nieudane próby ograniczenia lub jedzenie pomimo negatywnych konsekwencji. Tylko 30 studentów spełniło kryteria uzależnienia od jedzenia, a 180 nie, co odzwierciedla, że takie problemy dotyczą mniejszej części populacji.
Radzenie sobie z nierównymi danymi i trenowanie inteligentnych maszyn
Ponieważ znacznie mniej studentów zaklasyfikowano jako uzależnionych od jedzenia, zestaw danych był niezrównoważony. Taka nierównowaga może sprawić, że modele komputerowe będą przewidywać głównie grupę większościową, ignorując wysokiego ryzyka mniejszość. Aby temu zapobiec, zespół zastosował dwa zabiegi przetwarzania danych. Najpierw użyli metody zwanej Tomek Links, aby ostrożnie usunąć mylące przypadki z grupy większości, które leżały zbyt blisko przypadków mniejszości. Następnie użyto SMOTE, który tworzy realistyczne syntetyczne przykłady grupy mniejszości, by wyrównać liczebności. Tylko dane treningowe zostały w ten sposób zmienione; oddzielna, nienaruszona grupa testowa została zachowana do oceny, jak modele radzą sobie z nowymi, niewidzianymi wcześniej studentami.
Testowanie wielu algorytmów
Naukowcy nie polegali na jednym wzorcu matematycznym. Zamiast tego porównali dziesięć różnych modeli uczenia maszynowego, od prostych metod, takich jak regresja logistyczna i k‑najbliższych sąsiadów, po bardziej zaawansowane metody zespołowe (ensemble) jak Random Forest, Gradient Boosting, LightGBM i CatBoost. Przetestowali też dwanaście strategii selekcji cech, by ustalić, które pytania i pomiary są najbardziej informatywne, oraz użyli walidacji krzyżowej i automatycznego strojenia parametrów dla każdego modelu. Ogólną wydajność oceniano za pomocą kilku miar, w tym dokładności (jak często model ma rację), F1‑score (równowaga między wykrywaniem prawdziwych przypadków a ograniczeniem fałszywych alarmów) oraz pola pod krzywą ROC, które pokazuje, jak dobrze model rozdziela osoby wysokiego i niskiego ryzyka.
Co napędza przewidywania „pod maską”
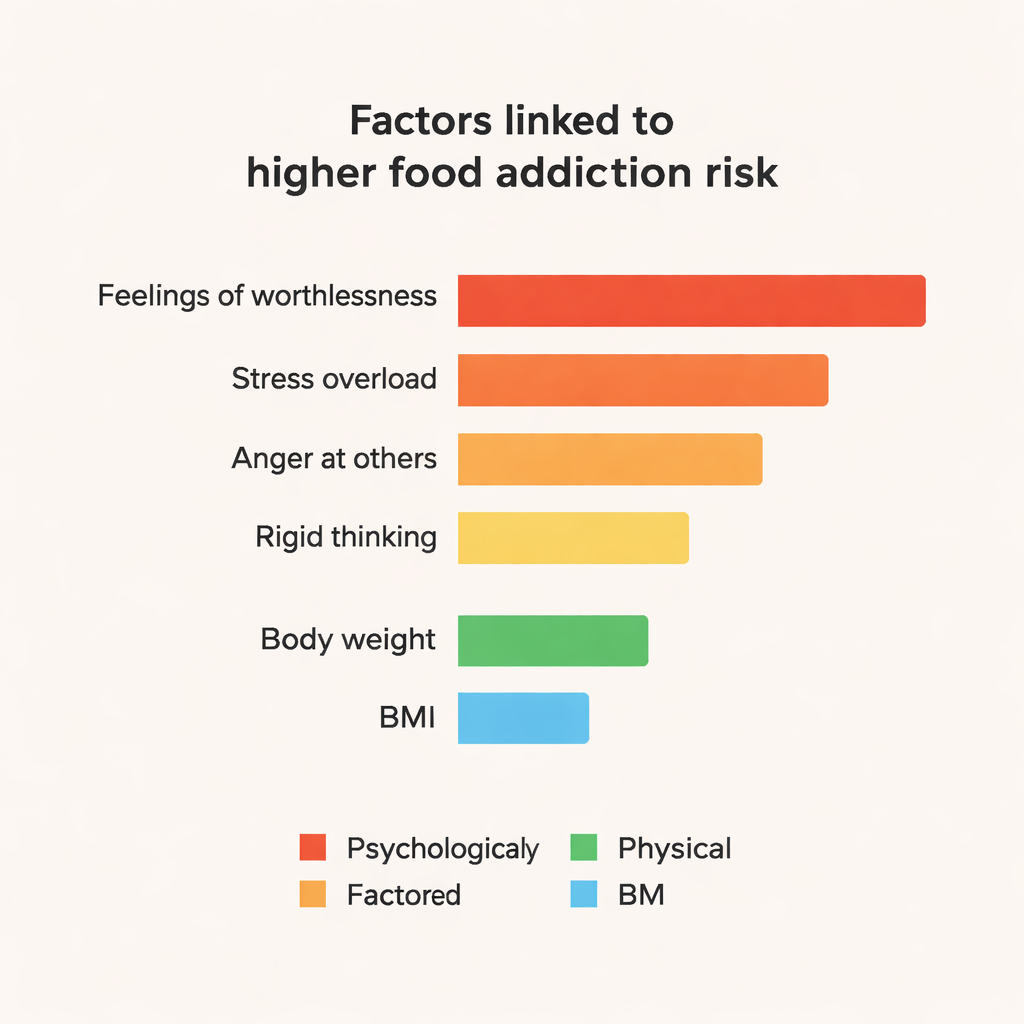
Modele zespołowe, zwłaszcza CatBoost i Random Forest, konsekwentnie przewyższały prostsze podejścia, osiągając około 84% dokładności i F1‑score około 0,84 na tym niewielkim zbiorze danych. Aby wyjść poza „czarną skrzynkę” przewidywań, zespół użył narzędzia SHAP do zbadania, które cechy skłaniają model do oznaczania kogoś jako uzależnionego od jedzenia. Najsilniejsze wpływy miały czynniki psychologiczne: silne stwierdzenia typu „Czasami czuję się całkowicie bezwartościowy”, poczucie „rozpadania się” pod wpływem stresu, częsty gniew z powodu traktowania przez innych, napięcie emocjonalne oraz sztywne, nieelastyczne myślenie. Waga i BMI również miały znaczenie, lecz były mniej centralne niż te sygnały związane z emocjami i osobowością. Cechy związane z pozytywnym nastrojem i dobrą organizacją wykazywały łagodny efekt ochronny.
Co to znaczy dla codziennego życia
Dla przeciętnego czytelnika kluczowy przekaz jest taki, że uzależnienie od jedzenia to nie tylko brak siły woli czy upodobanie do smacznych przekąsek. W tej pilotażowej grupie studentów głębsze trudności emocjonalne — niskie poczucie własnej wartości, problemy z radzeniem sobie ze stresem i napięte relacje — były ściśle powiązane z problematycznym jedzeniem. Wczesne wersje narzędzi uczenia maszynowego, oparte na podstawowych kwestionariuszach i pomiarach ciała, potrafiły wychwycić te wzorce z obiecującą dokładnością. Jednak autorzy podkreślają, że ich próbka była mała, oparta na samoopisach i pochodziła z jednego uniwersytetu, więc wyniki są wstępne. Przy większych i bardziej różnorodnych badaniach podobne modele mogłyby w przyszłości być używane obok standardowych ocen klinicznych, aby wychwycić młode osoby, które mogłyby skorzystać ze wsparcia w zarządzaniu zarówno emocjami, jak i nawykami żywieniowymi.
Cytowanie: Rahimnezhad, A., Mortazavi, S.T., Behdarvand, Y. et al. Machine learning prediction of food addiction in university students using demographic, anthropometric and personality traits. Sci Rep 16, 6745 (2026). https://doi.org/10.1038/s41598-026-36162-5
Słowa kluczowe: uzależnienie od jedzenia, studenci, cechy osobowości, uczenie maszynowe, jedzenie pod wpływem emocji