Clear Sky Science · pl
Integracja optymalizacji i uczenia maszynowego w estymacji rezystywności wody i nasycenia w zbiornikach typu shaley sand
Dlaczego to ma znaczenie dla energii i środowiska
Firmy naftowe i gazowe polegają na pomiarach wykonywanych w otworze wiertniczym, aby ustalić, gdzie ukrywają się węglowodory i czy pole jest warte zagospodarowania. W wielu złożach, szczególnie tych bogatych w iły i muł, te pomiary są wyjątkowo trudne do interpretacji, co może prowadzić do zaniżenia ilości ropy lub gazu. W pracy przedstawiono nowy sposób wydobycia bardziej wiarygodnych informacji z istniejących danych, łącząc optymalizację opartą na prawach fizyki z nowoczesnym uczeniem maszynowym, co potencjalnie poprawia odzysk zasobów przy jednoczesnym ograniczeniu potrzeby kosztownych pobrań rdzeni.
Problem z „błotnymi” skałami
Wiele światowych złóż węglowodorów to „shaley sands” – mieszaniny ziaren piasku, płynów porowych i przewodzących minerałów ilastych. Iły zniekształcają pomiary elektryczne stosowane do oszacowania, jaka część porów skały jest wypełniona wodą, a jaka węglowodorami. Klasyczne narzędzia i wykresy, opracowane dla czystszych piasków, zakładają proste struktury skały i niewielką zawartość iłu. W shaley sands te założenia zawodzą, często powodując, że skały wydają się bardziej wilgotne niż są w rzeczywistości, co prowadzi do odrzucenia partii, które mogą zawierać istotne ilości ropy lub gazu.
Przekształcanie rzadkich pomiarów w solidny punkt odniesienia
Autorzy zajmują się kluczową wielkością zwaną rezystywnością wody formacyjnej, opisującą, jak dobrze woda w porach przewodzi prąd. Jeśli ta wartość jest błędna, wszystkie kolejne oszacowania nasycenia wodą są zniekształcone. Zamiast polegać na kilku pomiarach laboratoryjnych czy subiektywnych metodach graficznych, stawiają problem jako zadanie optymalizacyjne: znaleźć pojedynczą wartość rezystywności wody, która sprawia, że model fizyczny dla shaley sand najlepiej dopasowuje się do rezystywności zmierzonej wzdłuż szybu. Testują kilka algorytmów poszukiwań i pokazują, że proste, bezpochodne metody, takie jak Powell i Nelder–Mead, potrafią odzyskać prawdziwą rezystywność wody z ekstremalnie małym błędem, w porównaniu z danymi rdzeniowymi i próbkami wody z 11 szybów w Norweskim Morzu Północnym i Zachodniej Pustyni w Egipcie.
Tworzenie „pseudo-rdzenia” jako logu do uczenia maszynowego
Gdy zoptymalizowana rezystywność wody jest znana, ten sam model fizyczny służy do obliczenia ciągłego profilu nasycenia wodą wzdłuż każdego szybu. Profil ten traktowany jest jako etykieta wysokiej jakości, informowana fizyką – swego rodzaju „pseudo-rdzeń” – dostępna na każdej głębokości, nie tylko w nielicznych pobranych odcinkach. Naukowcy następnie podają standardowe logi odwiertowe, takie jak gamma, porowatość neutronowa, gęstość i głęboka rezystywność, do szerokiego spektrum modeli uczenia maszynowego. Obejmują one zespoły oparte na drzewach (Random Forest, XGBoost, CatBoost), maszyny wektorów nośnych oraz kilka architektur sieci neuronowych, w tym specjalną sieć rekurencyjną LSTM, zdolną rozpoznawać wzorce zmieniające się z głębokością. Staranna obróbka wstępna, filtrowanie wartości odstających i normalizacja pomagają zapewnić, że modele uczą się rzeczywistych zależności geologicznych, a nie szumu.
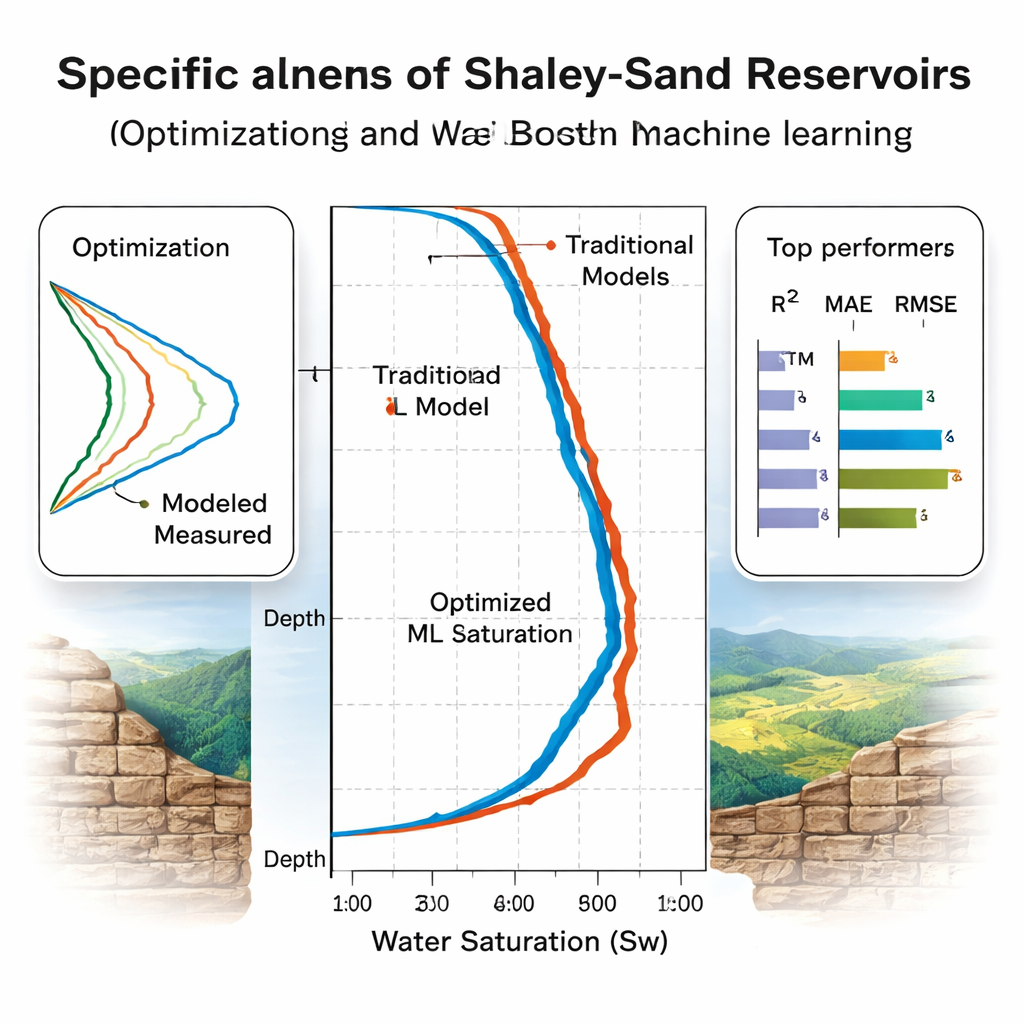
Które modele rzeczywiście uogólniają?
Zespół ocenia modele w dwóch etapach. Najpierw używają pięciokrotnej walidacji krzyżowej na ośmiu szybach z Morza Północnego, aby dostroić i uszeregować modele, przy czym Random Forest wydaje się zwycięzcą pod względem standardowych miar dokładności. Następnie przeprowadzają bardziej wymowny test: trzy „ślepe” szyby, w tym dwie z geologicznie odmiennego basenu egipskiego, które nigdy nie były użyte w treningu. W tych przypadkach niektóre modele zawodzą. Wydajność Random Forest spada, co sygnalizuje przeuczenie na oryginalnym basenie. Natomiast drzewa ze wzmocnieniem stopniowym (CatBoost i XGBoost) oraz sieci LSTM i sieci neuronowe z regularizacją bayesowską utrzymują wysoką dokładność, wyjaśniając ponad 93–94% zmienności nasycenia wodą przy umiarkowanych błędach. Analiza istotności cech za pomocą SHAP, nowoczesnego narzędzia do interpretowalności, potwierdza, że modele silnie opierają się na fizycznie sensownych wejściach, takich jak rezystywność, porowatość i objętość iłu.
Co to znaczy prostymi słowami
Dla osób niebędących specjalistami istotna idea jest taka: autorzy najpierw używają fizyki, aby oczyścić i ustabilizować problem, a dopiero potem wprowadzają uczenie maszynowe. Pozwalając procedurze optymalizacyjnej znaleźć najlepiej dopasowaną rezystywność wody i przekształcając to w gęsty, zgodny z fizyką zbiór treningowy, omijają typowy wąski gardłowy problem rzadkich i drogich danych rdzeniowych. Ich wyniki pokazują, że podejście „najpierw optymalizacja, potem ML” może dostarczyć wiarygodnych estymatów, ile części zbiornika typu shaley jest wypełnione wodą versus węglowodorami, nawet w nowych basenach nieużytych w treningu. W praktyce może to pomóc operatorom rzetelniej mapować strefy płatne, ograniczyć niepotrzebne pobieranie rdzeni i ulepszyć oszacowania zasobów w miejscu — wszystko poprzez mądrzejsze wykorzystanie danych, które już zbierają.
Cytowanie: Hameedy, M.A.E., Mabrouk, W.M. & Metwally, A.M. Integrating optimization and machine learning for estimating water resistivity and saturation in shaley sand reservoirs. Sci Rep 16, 6342 (2026). https://doi.org/10.1038/s41598-026-36133-w
Słowa kluczowe: zbiorniki typu shaley sand, nasycenie wodą, rezystywność wody formacyjnej, uczenie maszynowe w petrofizyce, charakteryzacja złoża