Clear Sky Science · pl
Uwaga-kierowana fuzja cech czasowo-przestrzennych dla niezawodnego wykrywania anomalii w nadzorze wideo
Dlaczego inteligentniejsze kamery mają znaczenie
Od zatłoczonych dworców po centra handlowe — współczesne życie wypełnione jest kamerami bezpieczeństwa, które cicho rejestrują wszystko, co się dzieje. Jednak większość tych materiałów i tak pozostaje, jeśli w ogóle, w gestii zmęczonych ludzkich oczu, które łatwo mogą przeoczyć kluczową chwilę. Artykuł bada nowy typ „inteligentnego” systemu nadzoru, który potrafi automatycznie wykrywać nietypowe lub ryzykowne zachowania, takie jak kradzież czy wandalizm, w czasie rzeczywistym, rozumiejąc zarówno to, co pojawia się w scenie, jak i jak się to zmienia w czasie.

Widzieć więcej niż piksele
Tradycyjny obraz z kamery to tylko sekwencja zdjęć. Starsze systemy komputerowe próbowały wykrywać problemy, analizując każdą klatkę osobno, szukając kształtów i krawędzi przypominających ludzi lub obiekty. Autorzy najpierw testują nowoczesną wersję tej idei, wykorzystując zwartą sieć rozpoznawania obrazów połączoną z klasycznymi detektorami krawędzi. Takie rozwiązanie działa całkiem dobrze w starannie skadrowanych scenach, zwłaszcza w wykrywaniu wyraźnych wskazówek wizualnych, jak chwytanie przedmiotu. Jednak skupiając się na pojedynczych migawkach, systemy te mają trudności, gdy ludzie się przesłaniają, tłumy gęstnieją albo ta sama poza może oznaczać zachowanie normalne lub podejrzane w zależności od przebiegu w czasie.
Rozumienie ruchu i zachowania
Aby uchwycić historię stojącą za działaniem, a nie tylko wygląd pojedynczej klatki, badanie ocenia następnie model skoncentrowany na wideo, który analizuje krótkie klipy zamiast statycznych obrazów. Model ten uczy się, jak przepływa ruch przez kilka klatek i lepiej identyfikuje nagłe zmiany, takie jak bieganie, bójka czy wyrwanie. Dobrze radzi sobie z wychwytywaniem wielu nietypowych zdarzeń, co przekłada się na wysoką czułość. Ma jednak klasyczny problem z zastosowań w warunkach rzeczywistych: naprawdę nietypowe zdarzenia są rzadkie w porównaniu do codziennej aktywności. W rezultacie model może stawać się niestabilny, generując zbyt wiele fałszywych alarmów i wymagając starannie przyciętych segmentów wideo, które nie odzwierciedlają chaotycznego, ciągłego charakteru rzeczywistego materiału nadzorczego.
Mieszanie gdzie i kiedy
Budując na mocnych i słabych stronach tych dwóch punktów odniesienia, autorzy proponują nowy hybrydowy system nazwany HybridModel-1, który ma „myśleć” jednocześnie przestrzennie i czasowo. Łączy sieć świetnie rozumiejącą, jakie obiekty występują w każdej klatce, z szybkim detektorem lokalizującym te obiekty w scenie. Specjalny moduł fuzji uczy się podkreślać najbardziej informacyjne szczegóły wizualne — takie jak ludzie i kluczowe przedmioty — przy jednoczesnym pomniejszaniu znaczenia zakłócającego tła, jak ściany, drzewa czy przejeżdżające samochody. Równocześnie nowa strategia treningowa delikatnie karze system za gwałtowne skoki pewności między kolejnymi klatkami, skłaniając go do płynniejszych, bardziej spójnych decyzji na przestrzeni całego materiału wideo.
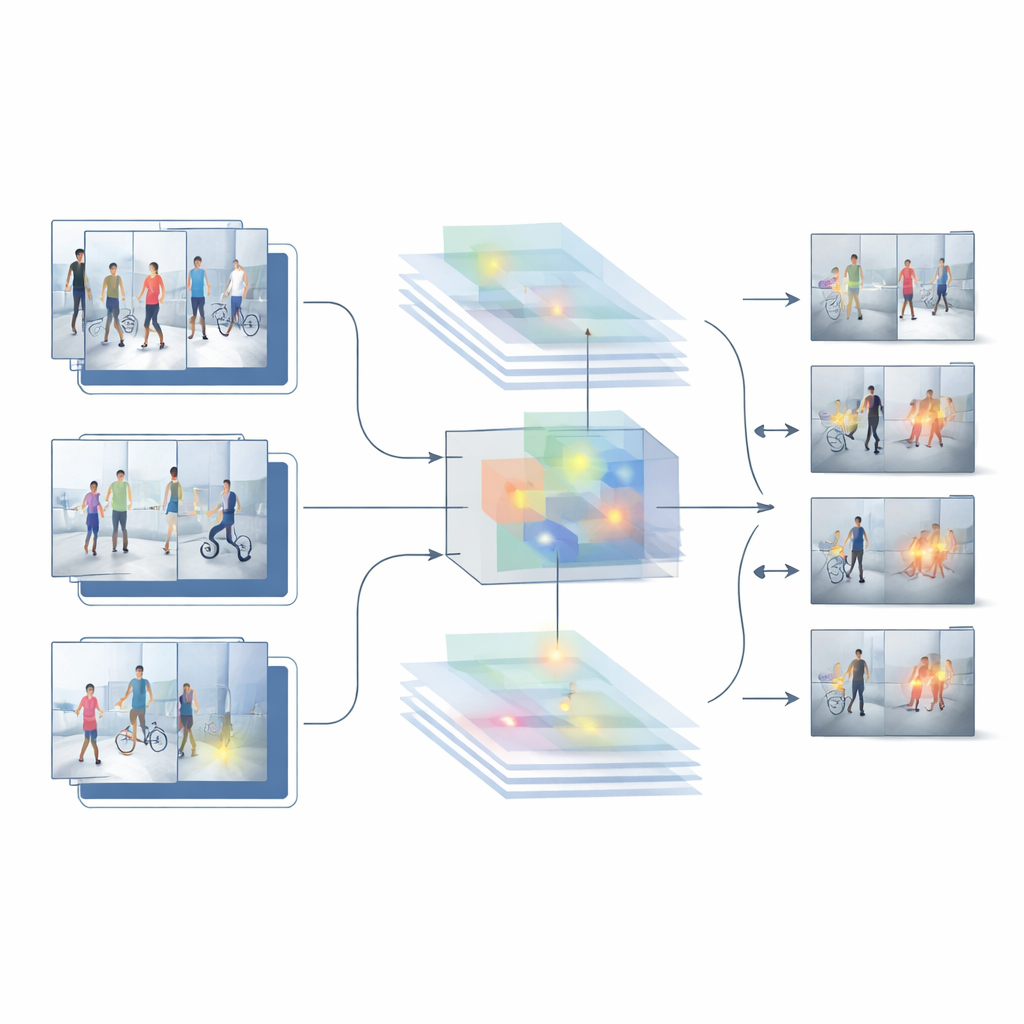
Postawienie systemu na próbę
Aby sprawdzić, czy projekt działa poza laboratorium, badacze testują go na kilku wymagających publicznych zbiorach rzeczywistych nagrań z nadzoru. Zbiory te obejmują wszystko: od scen kradzieży wewnątrz budynków po zewnętrzne alejki kampusów, z różnymi pozycjami kamer, oświetleniem, liczebnością tłumów i typami incydentów. W tych benchmarkach model hybrydowy przewyższa zarówno podejście oparte wyłącznie na obrazach, jak i model oparty tylko na wideo. Osiąga wyższą ogólną dokładność, generuje znacznie mniej fałszywych alarmów i utrzymuje wysoką wydajność nawet podczas oceny na materiałach, na których nie był trenowany. Szczegółowe porównania i badania ablacjyjne — gdzie elementy systemu są usuwane lub modyfikowane — pokazują, że moduł fuzji cech i krok treningowy ukierunkowany na gładkość wnioskują znaczący wkład w te poprawy.
Co to oznacza dla bezpieczeństwa codziennego
Mówiąc prościej, praca ta pokazuje, że systemy nadzoru stają się bardziej niezawodne, gdy uczą się zwracać uwagę na właściwe części sceny i zachowywać stabilność ocen w czasie. Zamiast traktować każdą klatkę jako odizolowany obraz lub polegać wyłącznie na surowym ruchu, proponowane podejście łączy „co” i „kiedy” w jednej, starannie dostrojonej strukturze. Choć wyzwania pozostają w ekstremalnie ciemnych lub mocno zasłoniętych widokach, wyniki wskazują praktyczną ścieżkę prowadzącą do sieci kamer, które mogą dyskretnie przeglądać ogromne ilości materiału, wydobywać rzeczywiście podejrzane zdarzenia i zmniejszać obciążenie fałszywymi alarmami dla operatorów. Dla społeczeństwa może to oznaczać bezpieczniejsze przestrzenie monitorowane przez systemy, które nie tylko oglądają, lecz naprawdę rozumieją to, co widzą.
Cytowanie: Nivethika, S.D., Joshi, S., Verma, K. et al. Attention-guided saptio-temporal feature fusion for robus video surveillance anomaly detection. Sci Rep 16, 8027 (2026). https://doi.org/10.1038/s41598-026-36130-z
Słowa kluczowe: nadzór wideo, wykrywanie anomalii, inteligentne kamery, wykrywanie przestępstw, uczenie maszynowe