Clear Sky Science · pl
Integracja regresyjnego krigingu opartego na Random Forest do analizy zmienności przestrzennej opadów w regionach suchych i półsuchych
Dlaczego mapowanie opadów na obszarach suchych ma znaczenie
W krajach, gdzie brakuje wody, wiedza o tym, gdzie i kiedy pada deszcz, może przesądzać o bezpieczeństwie żywnościowym. Pakistan obejmuje góry, pustynie i żyzne równiny, a pod wpływem zmian klimatu opady stały się bardziej nieregularne. Jednocześnie naziemne stacje meteorologiczne są rzadkie i rozproszone. Badanie stawia praktyczne pytanie: czy przy ograniczonych danych nowoczesne uczenie maszynowe połączone z klasycznymi technikami kartowania może dostarczyć ostrzejszych, bardziej wiarygodnych map opadów, które pomogą w rolnictwie, planowaniu przeciwpowodziowym i zarządzaniu zasobami wodnymi?
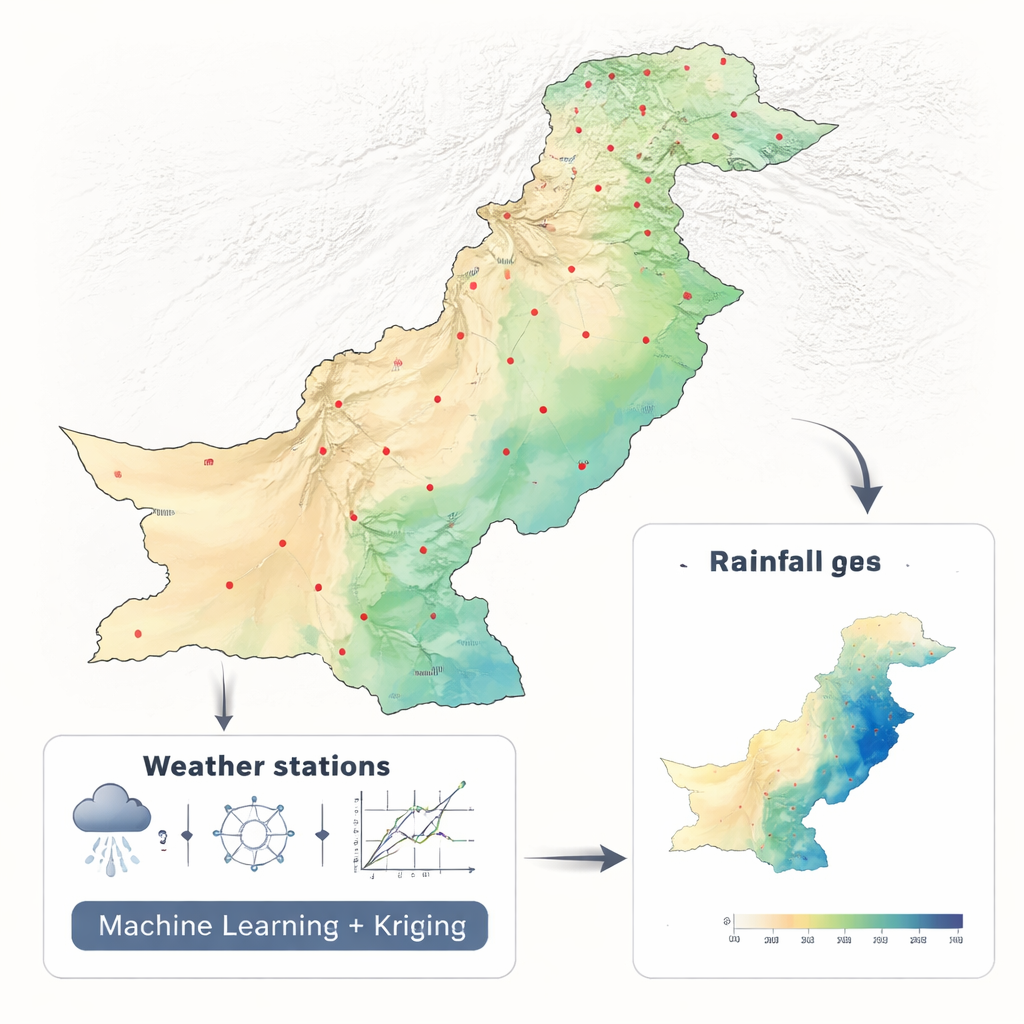
Jak przekształcić rozproszone deszczomierze w pełne mapy
Naukowcy wykorzystali dwie dekady miesięcznych danych opadowych (2001–2010 i 2011–2021) z 42 stacji w całym Pakistanie, korzystając ze spójnego zestawu danych klimatycznych NASA. Zamiast wprowadzać dziesiątki zmiennych środowiskowych do złożonego modelu, celowo użyli jedynie szerokości i długości geograficznej. Tak uproszczone podejście pozwoliło im skupić się na jednym kluczowym zagadnieniu: która metoda matematyczna najlepiej przekształca rozproszone pomiary punktowe w ciągłą mapę. Porównali sześć metod uczenia maszynowego — Random Forest, Support Vector Machine, K-Nearest Neighbors, sieć neuronową, Elastic Net i regresję wielomianową — każdą osadzoną w ramach zwanych regresyjnym krigingiem, powszechnie stosowanym w geonaukach.
Łączenie nauki w stylu big data z intuicją przestrzenną
Regresyjny kriging działa w dwóch etapach. Najpierw model regresyjny przewiduje opady w dowolnej lokalizacji na podstawie jej współrzędnych, wychwytując szerokie wzorce, takie jak mokre góry i suche pustynie. Następnie metoda przestrzenna zwana krigingiem wypełnia pozostałe, lokalne różnice między obserwacjami a przewidywaniami. Aby uczynić ten drugi krok wiarygodnym, zespół najpierw zbadał, jak podobieństwo opadów między parami stacji zmienia się w zależności od odległości — narzędzie to nazywa się wariogramem. Stwierdzili, że proste kształty matematyczne „okrągły” i „liniowy” najlepiej opisują, jak podobieństwo opadów maleje z odległością w różnych porach roku i w obu dekadach, co świadczy o gładkich, obejmujących region systemach opadowych, a nie o nagłych skokach.
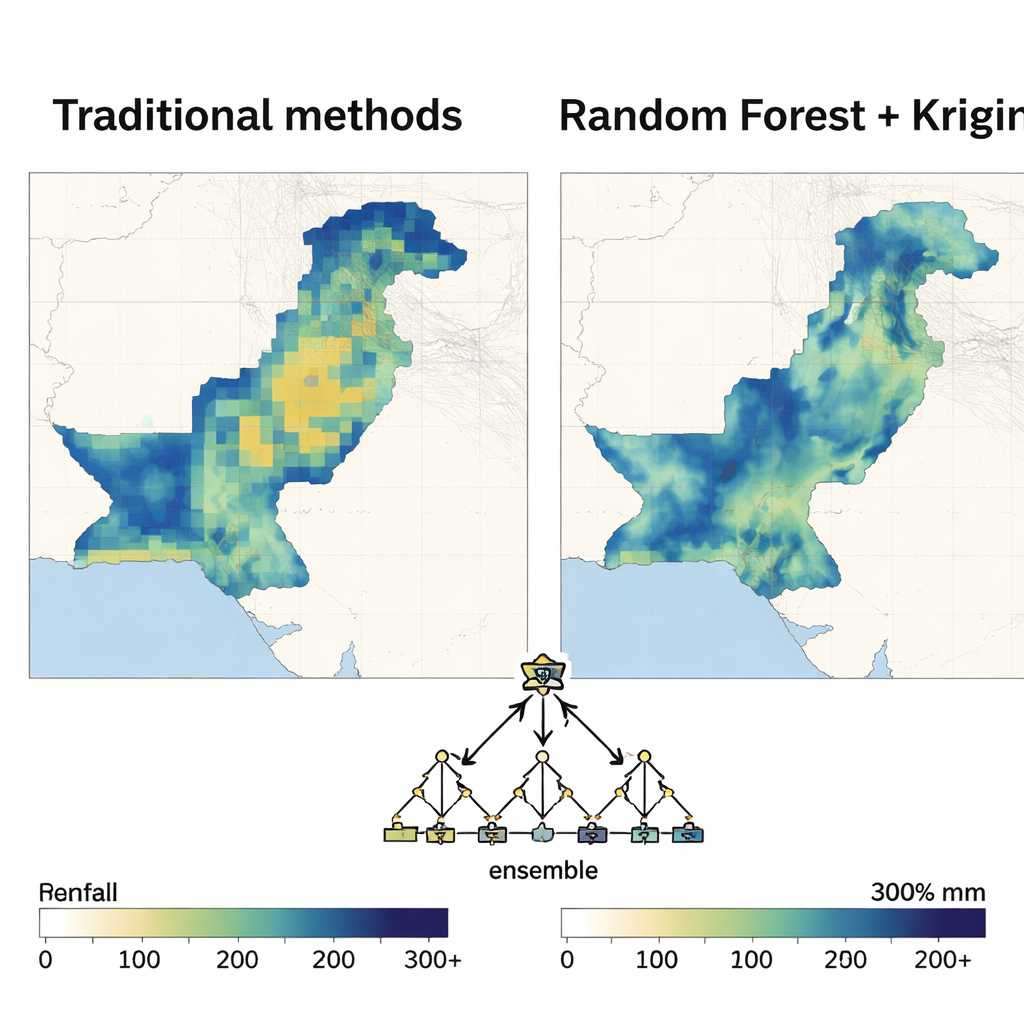
Random Forest wyłania się jako lider
Gdy struktura przestrzenna została określona, każda metoda uczenia maszynowego pełniła po kolei rolę silnika regresyjnego w hybrydowym modelu. Autorzy oceniali wydajność za pomocą standardowych miar błędu oraz zdolności modelu do wyjaśnienia zmienności opadów. W niemal wszystkich miesiącach i w obu dekadach podejście oparte na Random Forest dostarczało najdokładniejszych i najstabilniejszych map. Zredukowało błędy predykcji znacznie bardziej niż regresja wielomianowa i konsekwentnie pokonywało maszyny wektorów nośnych, sieci neuronowe i inne metody, szczególnie w miesiącach monsunowych, gdy opady są największe i najbardziej zmienne. Powstałe mapy były gładkie tam, gdzie oczekiwano, a jednocześnie oddawały ostre kontrasty między suchymi a wilgotnymi strefami, przy relatywnie niskiej niepewności.
Co ujawniają zmieniające się wzorce opadów
Porównanie dwóch dekad ujawniło także oznaki przesunięć w zachowaniu opadów. Średnio późniejsza dekada (2011–2021) była wilgotniejsza, z większą zmiennością miesiąc do miesiąca i miejsce do miejsca, szczególnie wiosną i w okresie monsunowym. Struktura przestrzenna opadów stała się bardziej rozproszona, co sugeruje szersze wahania w miejscach dostarczania wody. Co ważne, kombinacja Random Forest–kriging poradziła sobie zarówno z wcześniejszym, nieco łagodniejszym klimatem, jak i z bardziej zmiennym niedawnym okresem bez utraty dokładności, co sugeruje, że takie elastyczne narzędzia dobrze sprawdzają się w ocieplającym się, mniej przewidywalnym świecie.
Od map do decyzji w terenie
Mówiąc prościej, artykuł pokazuje, że inteligentne algorytmy potrafią wycisnąć więcej wartości z ograniczonych rejestrów opadów, tworząc mapy o wysokiej rozdzielczości przydatne nawet w regionach ubogich w dane. Dla Pakistanu takie mapy mogą wspierać lepsze planowanie nawadniania, zarządzanie zbiornikami i zabezpieczenia przeciwpowodziowe oraz pomóc wskazać społeczności najbardziej narażone na susze lub ulewne opady. Autorzy podkreślają, że ich praca jest dowodem koncepcji skoncentrowanym na technikach mapowania, a nie pełnym systemem ostrzegania przed powodziami czy suszami. Niemniej wniosek jest jasny: łączenie zespołowego uczenia maszynowego, z Random Forest na czele, z geostatystycznym mapowaniem oferuje potężne, praktyczne narzędzie do śledzenia zmian opadów na suchych i półsuchych obszarach na całym świecie.
Cytowanie: Manaf, M., Ali, Z. & Scholz, M. Integrating random forest-based regression kriging for analyzing spatial variability of rainfall in arid and semi-arid regions. Sci Rep 16, 5298 (2026). https://doi.org/10.1038/s41598-026-36074-4
Słowa kluczowe: mapowanie opadów, random forest, regresyjny kriging, klimat Pakistanu, zasoby wodne