Clear Sky Science · pl
Uczenie samonadzorowane na grafach przewiduje powiązania między RNA niekodującym a chorobami
Dlaczego ukryte RNA ma znaczenie dla naszego zdrowia
Większość z nas nauczyła się, że główną rolą RNA jest pomoc w budowie białek. Jednak w ciągu ostatniej dekady naukowcy odkryli ogromne ilości RNA „niekodujących”, które nigdy nie stają się białkami, a mimo to kontrolują funkcjonowanie komórek. Wiele z tych cząsteczek wiadomo, że napędza lub tłumi nowotwory i inne złożone choroby. Ustalenie, które RNA niekodujące są związane z którymi chorobami, może ujawnić nowe sposoby wczesnej diagnozy lub projektowania precyzyjniejszych terapii — ale testowanie każdej możliwości w laboratorium byłoby niewyobrażalnie powolne. W tym badaniu wprowadzono potężną metodę komputerową, która potrafi przesiać ogromne sieci biologiczne i wiarygodnie zaproponować najbardziej obiecujące powiązania RNA–choroba do sprawdzenia w eksperymentach.
Z odpadków do kluczowych uczestników komórkowych
Przez lata RNA niekodujące były odrzucane jako bezsensowne pozostałości aktywności genów. Dziś wiemy, że rodziny takie jak mikroRNA, długie RNA niekodujące czy RNA koliste uczestniczą w organizowaniu kluczowych procesów — od pakowania DNA po włączanie i wyłączanie genów oraz przekazywanie sygnałów wewnątrz komórek. Ponieważ znajdują się w wielu punktach kontroli, nawet niewielkie zmiany w tych RNA mogą przesunąć równowagę w stronę nowotworu lub innych schorzeń. Klinicyści zaczęli już traktować je jako potencjalne markery i cele lekowe. Wyzwanie polega na skali: istnieją tysiące różnych RNA i setki chorób, a tradycyjne eksperymenty testujące każde możliwe powiązanie są kosztowne i czasochłonne. Tu wkracza predykcja obliczeniowa, oferując sposób zawężenia przestrzeni poszukiwań.
Jak odczytać sieć biologiczną
Wcześniejsze metody komputerowe próbowały przewidywać powiązania RNA–choroba, dzieląc duże tabele danych na prostsze kawałki lub trenując modele uczenia maszynowego na znanych przykładach. Podejścia te pomagały, ale często ignorowały, jak RNA i choroby są splecione w sieci. Nowoczesne „grafowe sieci neuronowe” traktują RNA i choroby jako węzły połączone krawędziami, podobnie jak sieć społeczna. Potrafią nauczyć się wzorców tego, kto jest z kim powiązany. Jednak większość tych metod grafowych wymaga wielu wiarygodnych przykładów treningowych i wielu starannie zaprojektowanych cech wejściowych. Uczyniło to te metody wrażliwymi na brakujące dane, hałas pomiarowy i przeuczenie — dobrze działają na znanych danych, ale zawodzą, gdy trzeba przewidzieć nowe powiązania.
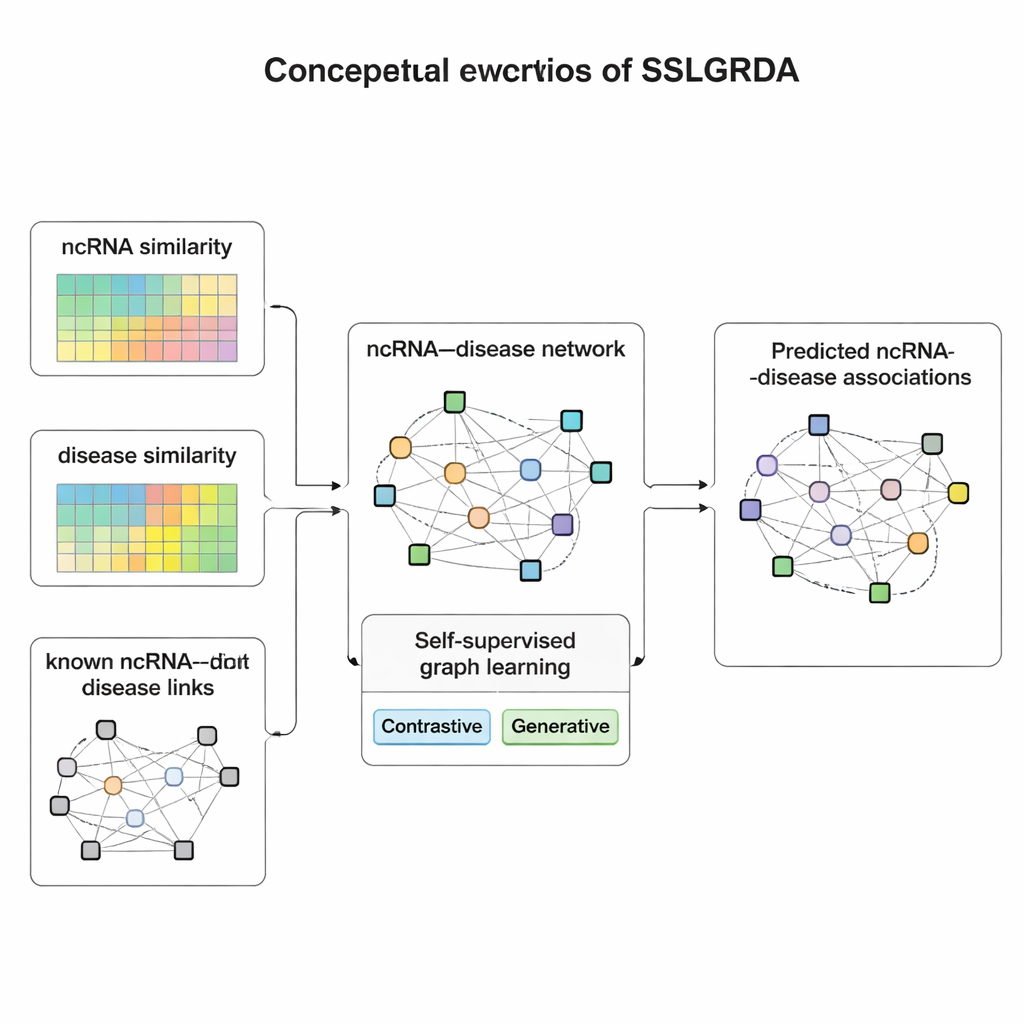
Nauka z samego danych
Autorzy przedstawiają SSLGRDA, nowe ramy, które uczą model grafowy rozpoznawać użyteczne wzorce bez silnego polegania na etykietowanych danych treningowych. Kluczową ideą jest „uczenie samonadzorowane”: zamiast podawać modelowi, które RNA łączy się z którą chorobą, model wymyśla własne zadania ćwiczeniowe oparte wyłącznie na strukturze i atrybutach sieci. Badacze budują dwa typy grafów. Jeden zachowuje RNA i choroby jako różne typy węzłów połączone znanymi powiązaniami. Drugi scala je w jedną dużą sieć (homogeniczną), która dodatkowo zawiera informacje o podobieństwie — jak bardzo dwa RNA lub dwie choroby są do siebie podobne — dzięki czemu nawet słabo połączone elementy zyskują wspierających sąsiadów. Na tych grafach SSLGRDA stosuje dwa style samonauczania. Strategie kontrastowe proszą model, by rozpoznał, że różne „widoki” tego samego węzła (na przykład jego połączenia kontra jego atrybuty) powinny prowadzić do podobnych reprezentacji wewnętrznych, jednocześnie wyraźnie rozdzielając niepowiązane węzły. Strategie generatywne celowo ukrywają części cech wejściowych i wyzywają model do ich rekonstrukcji, zachęcając do uchwycenia głębszej struktury zamiast zapamiętywania szumu.
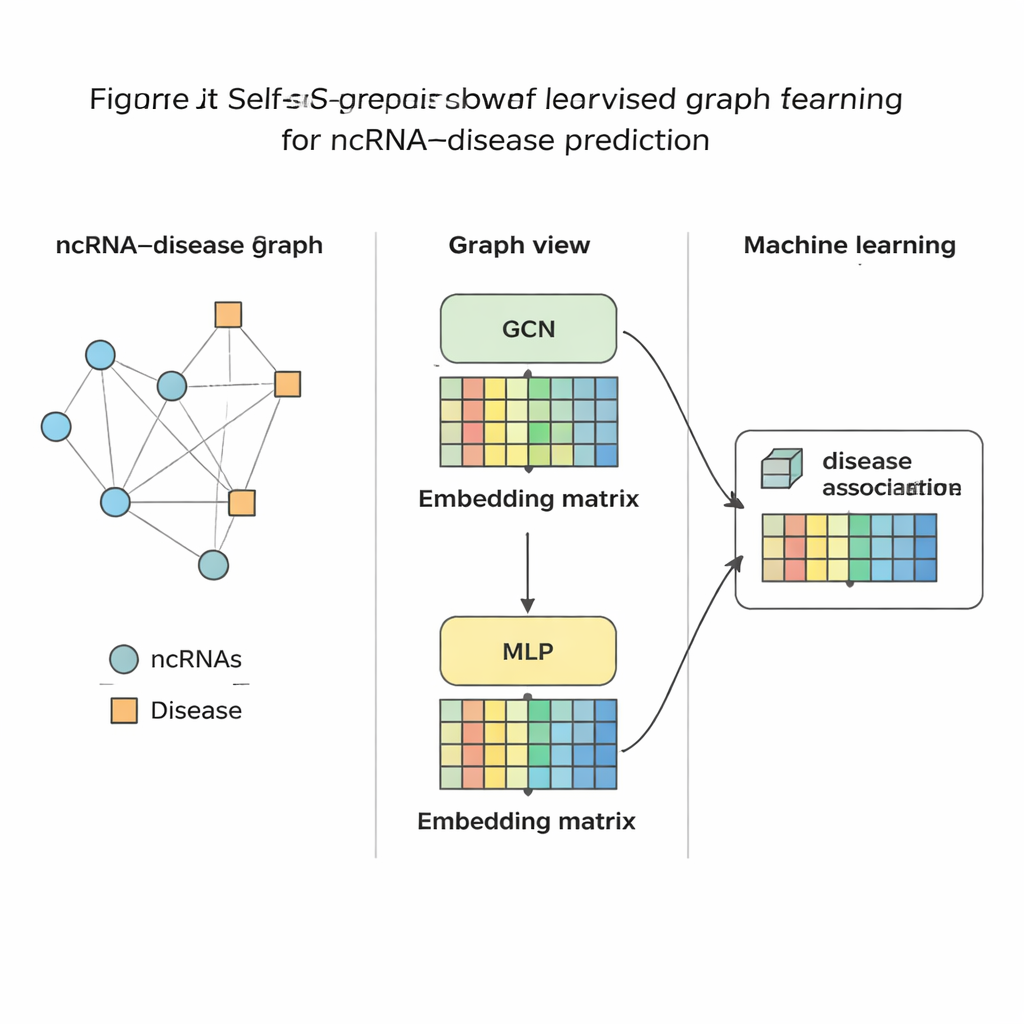
Sprawdzenie metody w praktyce
Gdy SSLGRDA skondensuje każde RNA i każdą chorobę do zwartego numerycznego odcisku, standardowy klasyfikator uczenia maszynowego jest trenowany, by ocenić, czy powiązanie między nimi jest prawdopodobne. Autorzy ocenili to podejście na dziewięciu różnych zestawach danych obejmujących trzy główne typy RNA i setki chorób. We wszystkich testach ich kontrastowe warianty uczenia samonadzorowanego na grafie jednorodnym wypadały najlepiej, przewyższając szereg istniejących narzędzi, w tym silne grafowe benchmarki. Metoda nie tylko osiągnęła wyższą dokładność w testach globalnych, lecz także zajmowała wysokie miejsca, gdy skupiano się na jednym RNA lub jednej chorobie — co jest kluczowe w zastosowaniach praktycznych, gdzie biolog może zacząć od jednego nowotworu i zapytać, które RNA warto badać. Pokazano też, że te same idee dobrze przenoszą się na inne sieci biomedyczne, na przykład łączące mikroby z chorobami lub lekami.
Od przewidywań do potencjalnych terapii
Aby wykazać wartość praktyczną, zespół zastosował SSLGRDA do poszukiwania nowych RNA niekodujących zaangażowanych w raka piersi, raka jelita grubego i kilka innych schorzeń. Wiele z najwyżej ocenionych propozycji zostało później potwierdzonych w niezależnych bazach danych lub raportach naukowych, co potwierdza zdolność modelu do wychwytywania biologicznie istotnych wzorców. Dla osób niebędących specjalistami wniosek jest taki, że praca ta dostarcza sprytniejszego sposobu wydobywania ukrytych wskazówek o chorobach z ciągle rosnącego splotu danych biologicznych. Dzięki automatycznemu uczeniu się, jak RNA i choroby się grupują i wchodzą ze sobą w interakcje, metody grafowe oparte na uczeniu samonadzorowanym, takie jak SSLGRDA, mogą kierować badaniami laboratoryjnymi ku najbardziej obiecującym celom, potencjalnie przyspieszając drogę od surowych danych do lepszych diagnostyk i terapii.
Cytowanie: Wu, Q., Tang, S. Self-supervised learning on graphs predicts non-coding RNA and disease associations. Sci Rep 16, 5231 (2026). https://doi.org/10.1038/s41598-026-36030-2
Słowa kluczowe: RNA niekodujące, powiązania z chorobami, grafowe sieci neuronowe, uczenie samonadzorowane, biologia obliczeniowa