Clear Sky Science · pl
Wieloparametrowa zoptymalizowana baza reguł wiarygodności do przewidywania wyników uczniów z zachowaniem interpretowalności
Dlaczego przewidywanie ocen to sprawa wszystkich
Świadectwa mogą wyglądać prosto, ale czynniki wpływające na oceny ucznia wcale takie nie są. Szkoły coraz częściej sięgają po modele komputerowe, by wcześnie wykrywać uczniów mających trudności i ukierunkować wsparcie. Wiele z tych modeli to jednak „czarne skrzynki”: mogą być dokładne, lecz nawet nauczyciele i rodzice nie widzą, dlaczego postawiono daną prognozę. Ten artykuł przedstawia nowe podejście, które ma być jednocześnie wysoce dokładne i łatwe do zrozumienia, tak aby edukatorzy mogli ufać wynikom i podejmować działania.
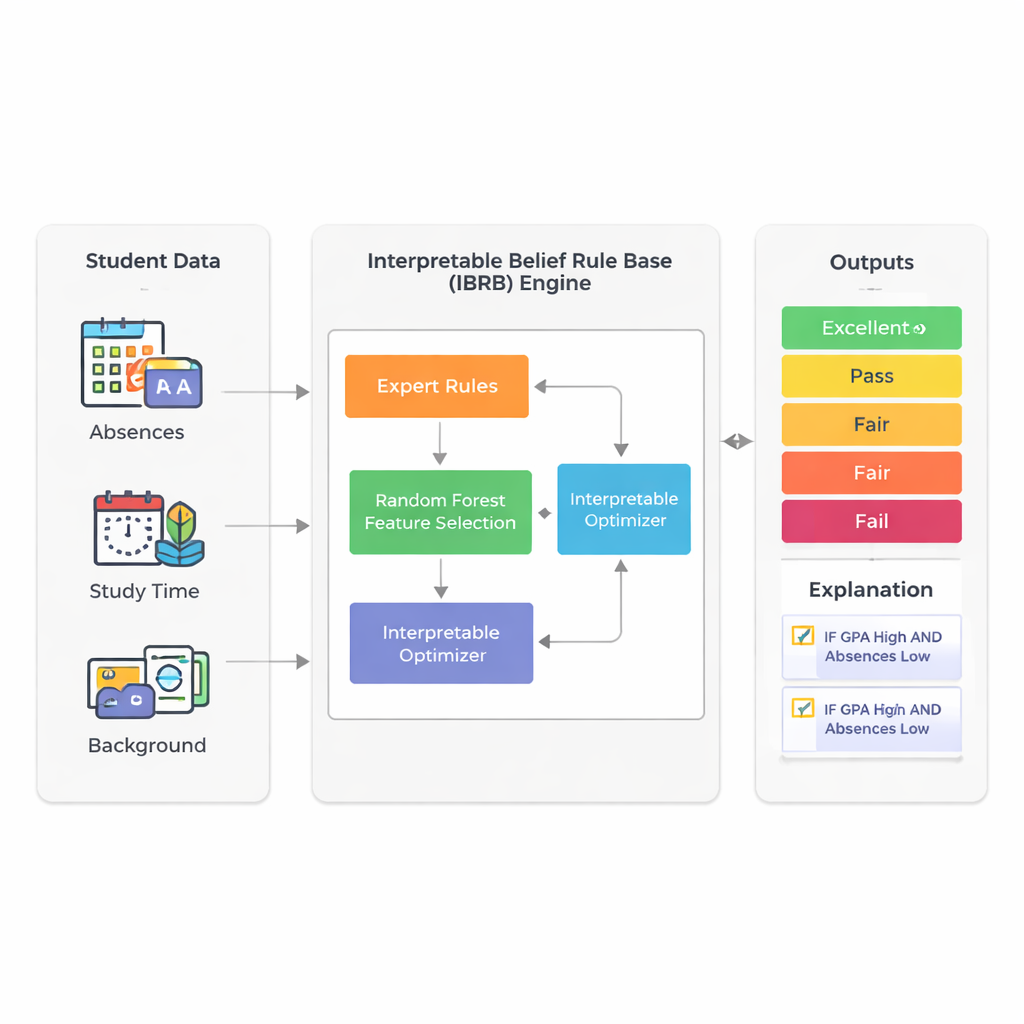
Inteligentniejszy sposób odczytywania sygnałów
Badanie skupia się na przewidywaniu, jak dobrze uczniowie ostatecznie sobie poradzą, wykorzystując informacje, które szkoły już zbierają: średnią ocen (GPA), nieobecności, czas poświęcony na naukę, tło społeczne oraz czynniki rodzinne i aktywności. Zamiast polegać na nieprzejrzystych systemach głębokiego uczenia, autorzy budują model oparty na technice zwanej bazą reguł wiarygodności. W tym ramach eksperci zapisują reguły przypominające to, co mógłby powiedzieć nauczyciel: „Jeśli GPA jest wysoka, a nieobecności niskie, to uczeń prawdopodobnie poradzi sobie dobrze.” Każda reguła niesie stopień wiary w możliwe wyniki, takie jak Doskonały, Dobry, Zaliczenie, Przeciętny czy Niepowodzenie. Dzięki temu proces wnioskowania jest widoczny i w zasadzie wyjaśnialny dla laików.
Oswajanie złożoności bez utraty sensu
Głównym problemem systemów opartych na regułach jest to, że mogą wymknąć się spod kontroli, gdy uwzględni się wiele atrybutów ucznia: każdy dodatkowy czynnik mnoży liczbę możliwych reguł. Aby uniknąć tej „eksplozji reguł”, badacze najpierw używają lasu losowego — powszechnie stosowanego zespołu drzew decyzyjnych — aby zmierzyć, które cechy mają największe znaczenie dla przewidywania wyników. W ich rzeczywistym zbiorze danych obejmującym 2392 uczniów z publicznego źródła, GPA i liczba nieobecności wyjaśniają około 73% mocy predykcyjnej modelu. Świadomie zachowując tylko te dwa wejścia, ostateczny model pozostaje zwarty i łatwiejszy do interpretacji, jednocześnie odzwierciedlając większość zmienności wyników uczniów.
Budowanie reguł, które ludzie potrafią śledzić
Rdzeniem nowego modelu, nazwanego IBRB-m, jest starannie zbudowany zestaw 25 reguł łączących poziomy GPA i nieobecności ze stopniami wiary dla pięciu kategorii wyników. Autorzy formalizują, co oznacza, że taki model jest „interpretowalny”. Wśród ich wymagań: każdy poziom odniesienia (na przykład „niska GPA”) musi obejmować jasny i odrębny zakres; baza reguł musi pokrywać wszystkie realistyczne kombinacje wejść; parametry takie jak wagi reguł i wagi atrybutów muszą mieć zrozumiałe, przyziemne znaczenie; a wewnętrzne obliczenia systemu muszą przekształcać informacje w przejrzysty, matematycznie spójny sposób. Do tych tradycyjnych warunków dodają wytyczne specyficzne dla edukacji, które wymuszają, by prognozy modelu miały zdroworozsądkowe kształty — na przykład unikając dziwnych przypadków, w których uczeń jednocześnie byłby oceniony jako bardzo prawdopodobny do osiągnięcia sukcesu i do porażki.
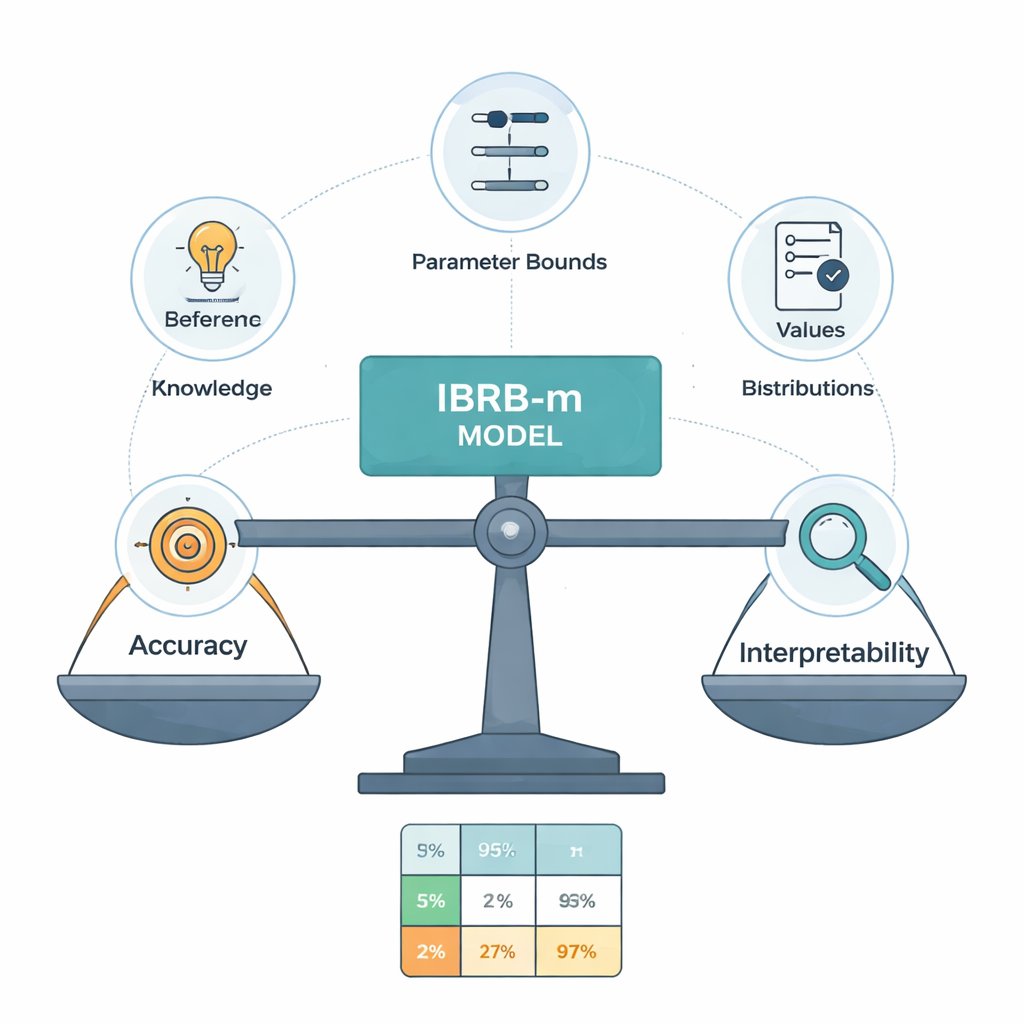
Pozwalanie danym dopracować to, co mówią eksperci
Eksperci nie zawsze się zgadzają, a ich początkowe reguły mogą być nieprecyzyjne. Aby dopracować te reguły, nie zamieniając modelu w czarną skrzynkę, autorzy opracowują ulepszony algorytm optymalizacji, który poszukuje lepszych wartości parametrów przy jednoczesnym przestrzeganiu surowych ograniczeń interpretowalności. Algorytm ten dostosowuje nie tylko wagi reguł i stopnie wiary, ale także progi definiujące kategorie takie jak Doskonały czy Zaliczenie. Wszystkie zmiany mieszczą się w granicach zatwierdzonych przez ekspertów i wymuszają rozsądne, płynne wzorce wiary wzdłuż skali ocen. W praktyce komputer „delikatnie popchnie” system ekspercki w stronę większej dokładności, ale nie ma prawa wymyślać reguł, które zaskoczyłyby doświadczonego nauczyciela.
Jak to działa w praktyce?
Testowany na zbiorze danych uczniów z Kaggle, model IBRB-m poprawnie przewiduje końcowe poziomy osiągnięć w ponad 99% przypadków, przewyższając zarówno wcześniejsze systemy oparte na bazie reguł wiarygodności, jak i powszechne narzędzia uczenia maszynowego, takie jak sieci neuronowe, lasy losowe czy k-najbliższych sąsiadów. Równie ważne jest to, że zoptymalizowane reguły pozostają bliskie pierwotnym ocenom ekspertów, mierzone prostą metryką odległości, co oznacza, że rozumowanie stojące za każdą prognozą wciąż można prześledzić i uzasadnić. Walidacja krzyżowa na wielu podziałach danych pokazuje, że wydajność modelu jest stabilna, a nie wynikiem szczęśliwego podziału.
Co to znaczy dla klas
Dla czytelników niebędących specjalistami główne wnioski są takie, że możliwe jest posiadanie narzędzi do przewidywania wyników uczniów, które są zarówno skuteczne, jak i zrozumiałe. Zamiast wydawać tajemnicze oceny ryzyka, model może wskazywać konkretne wzorce, takie jak „umiarkowane GPA, ale częste nieobecności”, i pokazać, jak wpływają one na prognozę Przeciętny lub Niepowodzenie. Nauczyciele i doradcy mogą dzięki temu reagować celowanymi działaniami — na przykład wsparciem frekwencji lub treningiem umiejętności uczenia się — równocześnie potrafiąc jasno wytłumaczyć uczniom i rodzicom, dlaczego model doszedł do takiego wniosku. Autorzy twierdzą, że to połączenie dokładności i przejrzystości jest niezbędne, jeśli systemy oparte na danych mają odgrywać zaufaną rolę w promowaniu sprawiedliwej i skutecznej edukacji.
Cytowanie: Li, J., Zhou, W., Jiang, S. et al. The multi-parameter optimized belief rule base for predicting student performance with interpretability. Sci Rep 16, 5772 (2026). https://doi.org/10.1038/s41598-026-35950-3
Słowa kluczowe: prognozowanie wyników uczniów, interpretowalna sztuczna inteligencja, baza reguł wiarygodności, eksploracja danych edukacyjnych, wyjaśnialne uczenie maszynowe