Clear Sky Science · pl
Ocena czynników wpływających na efekty nauczania na uczelniach z wykorzystaniem technik rozmytych i głębokiego uczenia
Dlaczego lepsze pomiary nauczania mają znaczenie
Każdy, kto siedział zarówno na świetnych, jak i mniej udanych zajęciach, wie, że jakość nauczania może zadecydować o doświadczeniu na uczelni. Mimo to większość uniwersytetów wciąż opiera się na topornych narzędziach, takich jak wyniki testów i ankiety końcowosemestralne, by oceniać, co działa. Artykuł ten bada inteligentniejszy sposób mierzenia efektywności nauczania na uczelniach, łącząc dwie metody komputerowe — jedną dobrze radzącą sobie z nieostrymi, subiektywnymi danymi ludzkimi, a drugą świetną w wykrywaniu ukrytych wzorców. Razem obiecują bardziej wiarygodne wskazówki do poprawy kursów i wsparcia studentów.
Przemyślenie, jak oceniamy „dobrą klasę”
Nauczanie na uczelni kształtuje wiele ruchomych elementów: ile jest studentów w sali, jak doświadczony jest wykładowca, jak trudny jest kurs, atmosfera zajęć i stosowanie technologii, by wymienić kilka. Tradycyjne systemy oceny często sprowadzają to wszystko do pojedynczego wyniku testu lub liczbowej oceny kursu. Takie uproszczenie pomija istotny kontekst i ignoruje nieporządne, subiektywne aspekty uczenia się. Autorzy twierdzą, że jeśli chcemy zrozumieć, dlaczego niektóre zajęcia pomagają studentom rozkwitać, a inne zawodzą, potrzebujemy narzędzi, które potrafią jednocześnie operować wieloma czynnikami i radzić sobie z niedoskonałymi, opartymi na opiniach danymi.
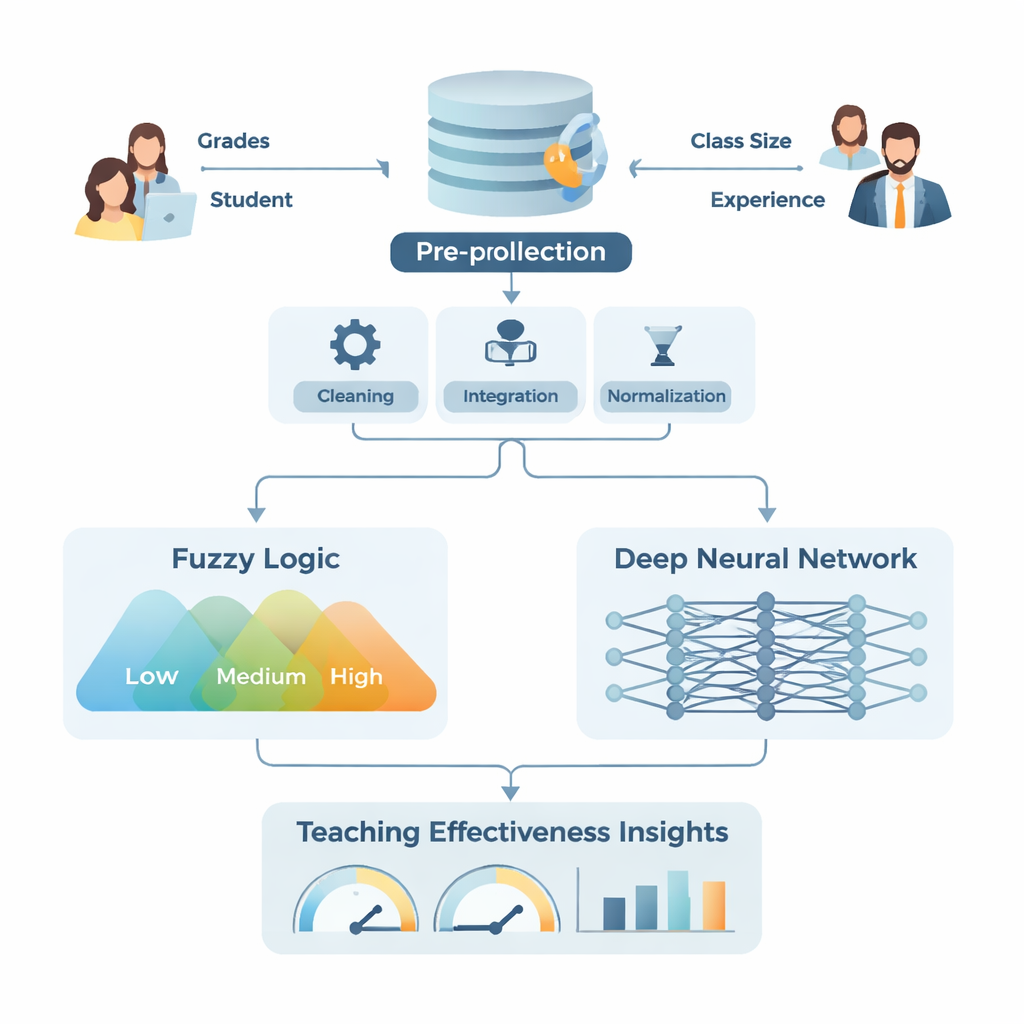
Hybrydowe podejście „ludzkie” i „wykrywanie wzorców”
Badanie wprowadza hybrydowy model nazwany Rozmytym i Głębokim Uczeniem (FDL). Część „rozmyta” naśladuje sposób myślenia ludzi w odcieniach szarości zamiast sztywnych kategorii tak/nie — na przykład określanie wyników studenta jako „niskie”, „średnie” lub „wysokie” z płynnymi przejściami zamiast ostrych progów. Przekształca niejasne wejścia, takie jak doświadczenie nauczyciela, stosunek studentów do wykładowcy czy trudność kursu, w elastyczne kategorie, a następnie stosuje proste reguły typu „jeśli wyniki studentów są wysokie i klasa jest mała, efektywność nauczania jest wysoka”. Tymczasem część oparta na głębokim uczeniu to wielowarstwowa sieć, która przetwarza duże ilości oczyszczonych i znormalizowanych danych, odkrywając złożone powiązania, które mogą być nieoczywiste dla ludzkich recenzentów.
Od surowych ankiet do znaczących sygnałów
Aby przetestować swoje podejście, badacze wykorzystali dane z National Survey of Student Engagement, dużego, powszechnie stosowanego kwestionariusza wypełnianego przez studentów pierwszego roku i studentów końcowych na uczelniach północnoamerykańskich. Dostosowali kilka pytań, by ostrzej skupić się na tym, jak dobrze nauczyciele wypełniają swoje role, a następnie sprawdzili, czy zmodyfikowana ankieta jest wiarygodna. Następnie przeprowadzili gruntowny proces przygotowania danych: oczyszczanie błędów, uzupełnianie brakujących wartości, scalanie informacji ze strony studentów i wykładowców oraz skalowanie wszystkiego do wspólnego zakresu. Stworzyli też wskaźniki złożone, takie jak ważona ocena ogólna oparta na wynikach egzaminów, realizacji prac domowych i frekwencji, oraz zmniejszyli złożoność danych za pomocą standardowej techniki zwanej analizą głównych składowych. Przygotowany zestaw danych zasilił zarówno moduł logiki rozmytej, obsługujący nieprecyzyjne kategorie, jak i sieć głębokiego uczenia, zajmującą się wysokowymiarowymi wzorcami numerycznymi.
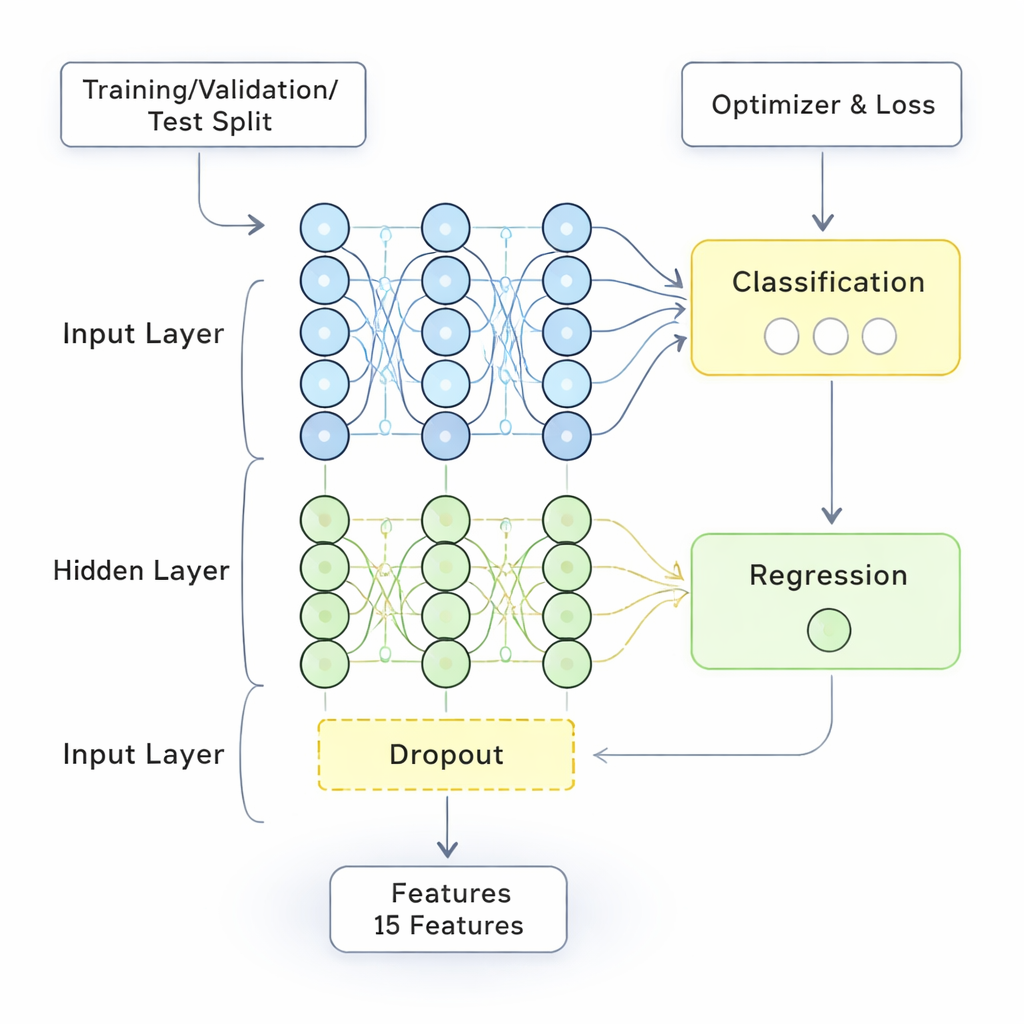
Jak dobrze działa nowy model?
Model FDL był trenowany i testowany na oddzielnych częściach danych, aby uniknąć oszukiwania samego siebie poprzez zapamiętywanie znanych przykładów. Jego wydajność porównano z kilkoma silnymi alternatywami, w tym standardowymi sieciami neuronowymi i bardziej zaawansowanymi modelami głębokimi. W kluczowych miarach — dokładności ogólnej, precyzji, czułości (recall) i wskaźniku F1 — metoda hybrydowa dorównywała lub przewyższała podejścia konkurencyjne, osiągając około 98% dokładności i niski wskaźnik błędu nieco powyżej 10%. Równie istotne jest to, że reguły rozmyte uczyniły jej decyzje bardziej interpretowalnymi niż w przypadku modeli typu black-box. System mógł wskazać, które kombinacje czynników — na przykład duże klasy w połączeniu z niskim doświadczeniem nauczyciela, lub wymagające kursy wspierane silną informacją zwrotną — były najsilniej powiązane z lepszymi lub gorszymi wynikami nauczania.
Co to oznacza dla studentów i uczelni
W prostych słowach, badanie pokazuje, że dziś można zbudować zautomatyzowany „barometr nauczania”, który jest jednocześnie wysoce dokładny i stosunkowo zrozumiały. Zamiast polegać głównie na topornych średnich i jednorazowych ankietach, uczelnie mogłyby używać takiego systemu do wczesnego wykrywania słabych środowisk nauczania, identyfikowania wykładowców lub kursów wymagających ukierunkowanego wsparcia oraz testowania, czy nowe polityki rzeczywiście pomagają studentom uczyć się więcej. Autorzy podkreślają, że model nie jest doskonały — zależy od jakości danych, może być obliczeniowo wymagający i z konieczności upraszcza bogaty, ludzki aspekt edukacji. Mimo to, stosowany rozważnie, oferuje potężną nową perspektywę na uczynienie sal wykładowych bardziej efektywnymi, sprawiedliwymi i reagującymi na potrzeby studentów.
Cytowanie: He, Z., Zhang, X., Zhang, Z. et al. Assessment of influencing factors of college and universities’ teaching effects using fuzzy and deep learning techniques. Sci Rep 16, 5168 (2026). https://doi.org/10.1038/s41598-026-35940-5
Słowa kluczowe: skuteczność nauczania, szkolnictwo wyższe, wyniki studentów, logika rozmyta, głębokie uczenie