Clear Sky Science · pl
Rozróżnianie bezpośrednich i plejotropowych efektów SNP u lucerny (Medicago sativa L.) z wykorzystaniem uczenia grafów przyczynowych
Dlaczego to ma znaczenie dla gospodarstw i żywności
Lucerna jest filarem nowoczesnego rolnictwa: karmi krowy mleczne i pomaga budować zdrowe gleby. Jednak poprawa cech lucerny — roślin, które dobrze znoszą zimę, są odporne na uszkodzenia i dostarczają wysokiej jakości paszę — jest spowolniona przez złożoność jej genetyki. To badanie przedstawia nowy sposób przejścia od długich, mylących list markerów DNA do czytelnych map przyczyna-skutek, pokazujących które fragmenty genomu rzeczywiście sterują istotnymi cechami łodyg, a które jedynie występują w korelacji.
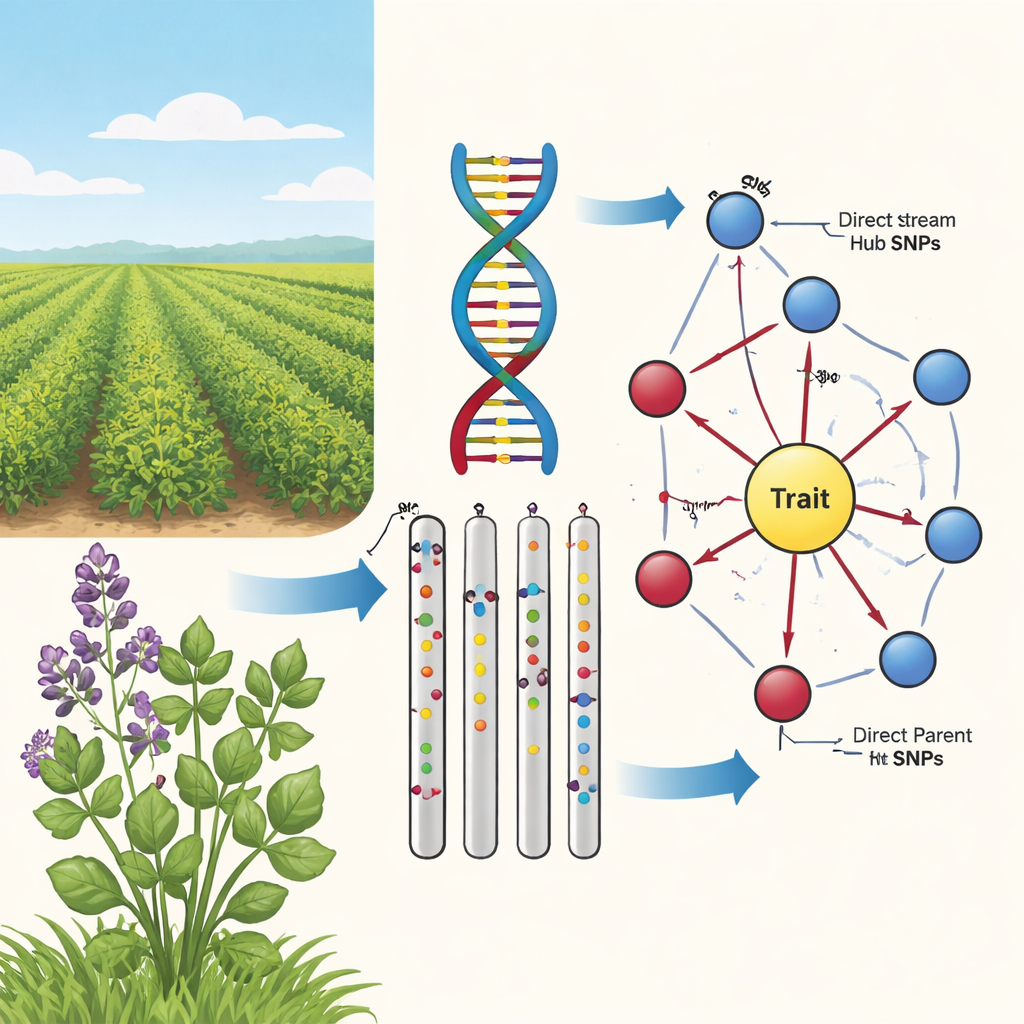
Od luźnych powiązań do przyczyny i skutku
Tradycyjne badania asocjacyjne obejmujące cały genom skanują DNA w poszukiwaniu wariantów, zwanych SNP, które często współwystępują z cechą, taką jak kolor łodygi czy przeżywalność zimowa. W przypadku lucerny sytuacja jest jednak szczególnie zagmatwana: ma cztery kopie każdego chromosomu, duże fragmenty DNA przemieszczają się razem, a populacje roślin są silnie wymieszane genetycznie. Tworzy to „mgłę korelacji”, w której wiele markerów wydaje się ważnych, lecz tylko nieliczne faktycznie wpływają na cechę. Autorzy argumentują, że hodowcy potrzebują czegoś więcej niż prostych statystycznych powiązań — muszą wiedzieć, które markery leżą na rzeczywistych ścieżkach przyczynowych od genotypu do widocznych cech roślin.
Jak działa nowe ramy analityczne
Naukowcy zbudowali dwustopniowe ramy łączące nowoczesne uczenie maszynowe z ideami z teorii grafów przyczynowych. Najpierw użyli techniki zwanej Double Machine Learning, aby przesiewać około 2400 SNP w 500 genotypach lucerny. Ten etap usuwa wpływ ukrytych czynników, takich jak tło rodzinne i geografia, stosując składowe główne genomu jako proxy. Wynikiem jest jaśniejszy obraz, które markery nadal wykazują bezpośredni efekt na cechy, takie jak kolor łodyg, po uwzględnieniu tych zakłócających wpływów. W tym przefiltrowanym widoku pojawiły się silne, stabilne sygnały głównie na chromosomach 2 i 4, a kluczowe markery miały rozmiary efektów, których przedziały ufności jednoznacznie wykluczały zero, sugerując rzeczywisty wpływ przyczynowy.
Przekształcanie markerów w genetyczne mapy drogowe
W drugim etapie zespół zastosował algorytm uczenia grafów przyczynowych znany jako algorytm PC, aby połączyć najbardziej obiecujące markery w sieć kierunkową. W tych diagramach węzły reprezentują SNP i cechę, a strzałki pokazują najbardziej prawdopodobny kierunek wpływu. Poprzez odcięcie krawędzi sprzecznych z podstawową biologią (na przykład cechy nie mogą zmieniać podstawowego DNA) i zachowanie jedynie SNP, które wpływają na cechę, autorzy uzyskali zwarte, biologicznie sensowne mapy. Te sieci przypominające „słoneczniki” ujawniają warstwową strukturę: wewnętrzny pierścień Bezpośrednich Rodziców (Direct Parent), które łączą się bezpośrednio z cechą, oraz zewnętrzny pierścień Głównych Węzłów (Upstream Hub), które wpływają na wiele rodziców, lecz nie oddziałują bezpośrednio na cechę.
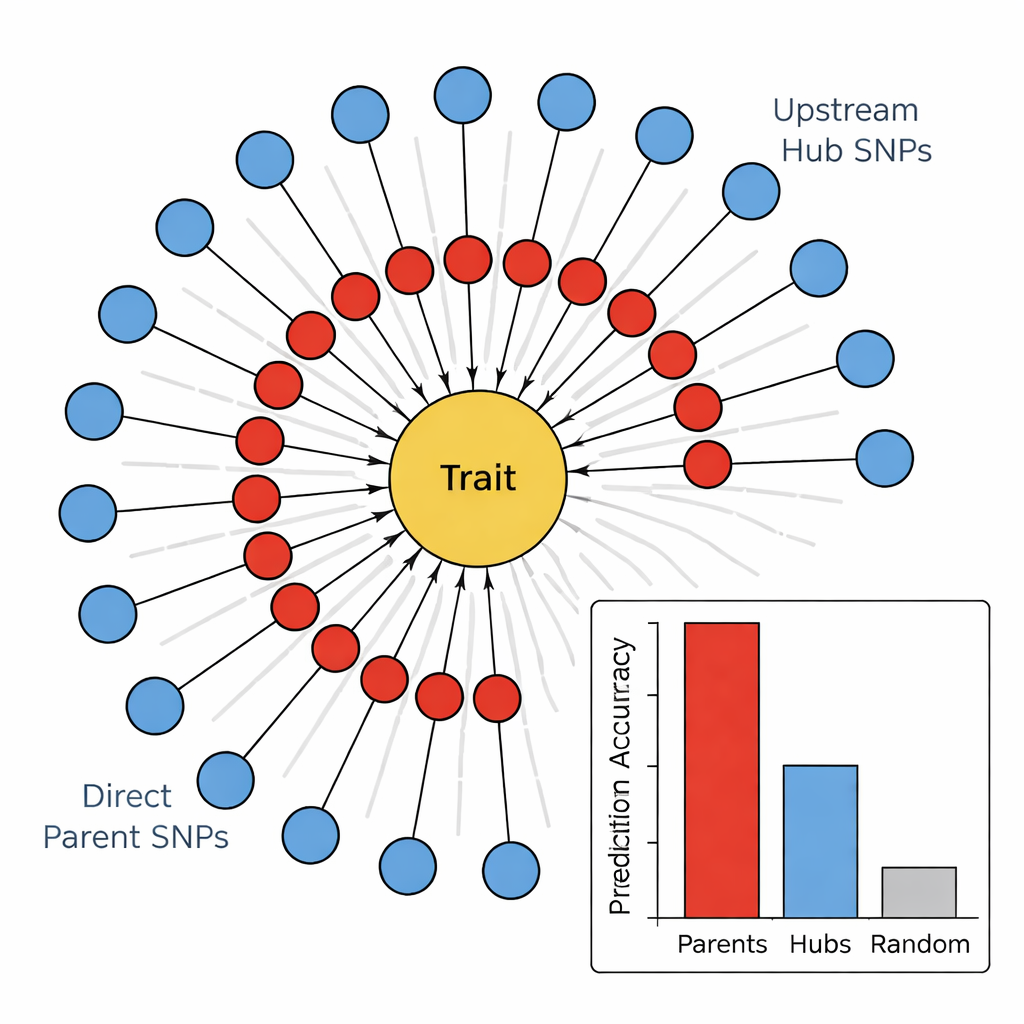
Wykonawcy kontra dyrektorzy w genomie
Aby sprawdzić, czy ta hierarchia ma znaczenie, autorzy porównali, jak dobrze różne grupy markerów potrafiły przewidywać cztery cechy związane z łodygą: kolor łodygi, wypełnienie łodygi, siłę łodygi i uszkodzenia zimowe. We wszystkich cechach SNP z grupy Bezpośrednich Rodziców konsekwentnie były najlepszymi predyktorami, często wyjaśniając wielokrotnie więcej zmienności niż losowe markery czy Główne Węzły. W przeciwieństwie do tego węzły wykazywały słabą lub nawet ujemną moc predykcyjną, mimo że były mocno połączone w sieci. Po powiązaniu tych SNP z poznanymi genami pojawił się wzorzec: Bezpośredni Rodzice często odpowiadali enzymom lub białkom strukturalnym działającym bezpośrednio na ściany komórkowe, pigmenty lub uszkodzenia wywołane stresem, podczas gdy Węzły odpowiadały czynnikom transkrypcyjnym i białkom regulatorowym, które szeroko modulują wiele ścieżek jednocześnie.
Co to oznacza dla przyszłej hodowli lucerny
Dla hodowców i genetyków badanie oferuje sposób przebrnięcia przez hałaśliwe wyniki asocjacyjne i skupienia się na zmianach DNA, które rzeczywiście przesuwają wskazówki dla konkretnych cech. Autorzy pokazują, że połączenie przesiewu pozbawionego konfuzji z grafami przyczynowymi może działać jak wbudowane zabezpieczenie przed przeuczeniem, przekształcając długie listy kandydatów w małe, interpretowalne sieci zgodne z poznaną biologią. W praktyce SNP z grupy Bezpośrednich Rodziców stają się wysokoprecyzyjnymi markerami do selekcji roślin o lepszych łodygach lub przeżywalności zimowej, podczas gdy Główne Węzły wskazują na główne przełączniki, które mogą przekształcić szersze reakcje na stres, lecz z możliwymi kompromisami. Ten strukturalny obraz genomu tworzy podstawę dla bardziej niezawodnej selekcji genomowej w złożonych uprawach oraz dla integrowania przyszłych warstw danych, takich jak ekspresja genów i metabolizm, w spójne modele przyczyna–skutek wydajności roślin.
Cytowanie: Lee, Y., Medina, C.A. & Xu, Z. Disentangling direct and pleiotropic SNP effects in alfalfa (Medicago sativa L.) using causal graph learning. Sci Rep 16, 5216 (2026). https://doi.org/10.1038/s41598-026-35876-w
Słowa kluczowe: genetyka lucerny, uczenie grafów przyczynowych, selekcja genomiczna, hodowla roślin, rośliny poliploidalne