Clear Sky Science · pl
HEViTPose: w kierunku wysoko dokładnego i wydajnego estymowania 2D pozycji człowieka z kaskadową grupową przestrzenną redukcją uwagi
Nauczanie komputerów czytania mowy ciała
Od aplikacji fitness po systemy wspomagania kierowcy — wiele technologii opiera się teraz na zdolności komputera do rozumienia, jak poruszają się ludzie. Ta umiejętność, nazywana estymacją pozycji człowieka, polega na znajdowaniu położeń stawów — takich jak barki, kolana i kostki — na obrazie lub w wideo. Wyzwanie polega na osiągnięciu zarówno wysokiej dokładności, jak i wystarczającej szybkości działania w czasie rzeczywistym na powszechnym sprzęcie. W artykule przedstawiono HEViTPose, nową metodę, która ma na celu zachowanie wysokiej dokładności przy jednoczesnym mniejszym zużyciu mocy obliczeniowej niż wiele obecnych systemów.
Dlaczego znajdowanie stawów na zdjęciach jest takie trudne
Pierwsze spojrzenie może sugerować, że lokalizowanie stawów jest proste: wystarczy znaleźć ręce i nogi. W praktyce ludzie pojawiają się w różnych rozmiarach, w nietypowych pozach, w zatłoczonych scenach i często częściowo za przesłonami, takimi jak meble czy samochody. Nowoczesne systemy estymacji pozycji zwykle radzą sobie z tym, tworząc szczegółową „mapę cieplną” (heatmap) dla każdego stawu, gdzie jasne punkty wskazują prawdopodobne pozycje. Mapy cieplne są bardzo precyzyjne, ale kosztowne obliczeniowo. Tradycyjne systemy opierają się głównie na splotowych sieciach neuronowych (CNN), które dobrze wykrywają lokalne wzorce, ale muszą być coraz głębsze i cięższe, aby uchwycić relacje na dużą skalę obejmujące całe ciało. Nowsze modele oparte na transformerach lepiej radzą sobie z długodystansowymi zależnościami, jednak często wymagają dużych zbiorów danych i sporych zasobów obliczeniowych, co utrudnia ich użycie w czasie rzeczywistym lub na mniejszych urządzeniach.
Nakładające się fragmenty dla płynniejszego postrzegania
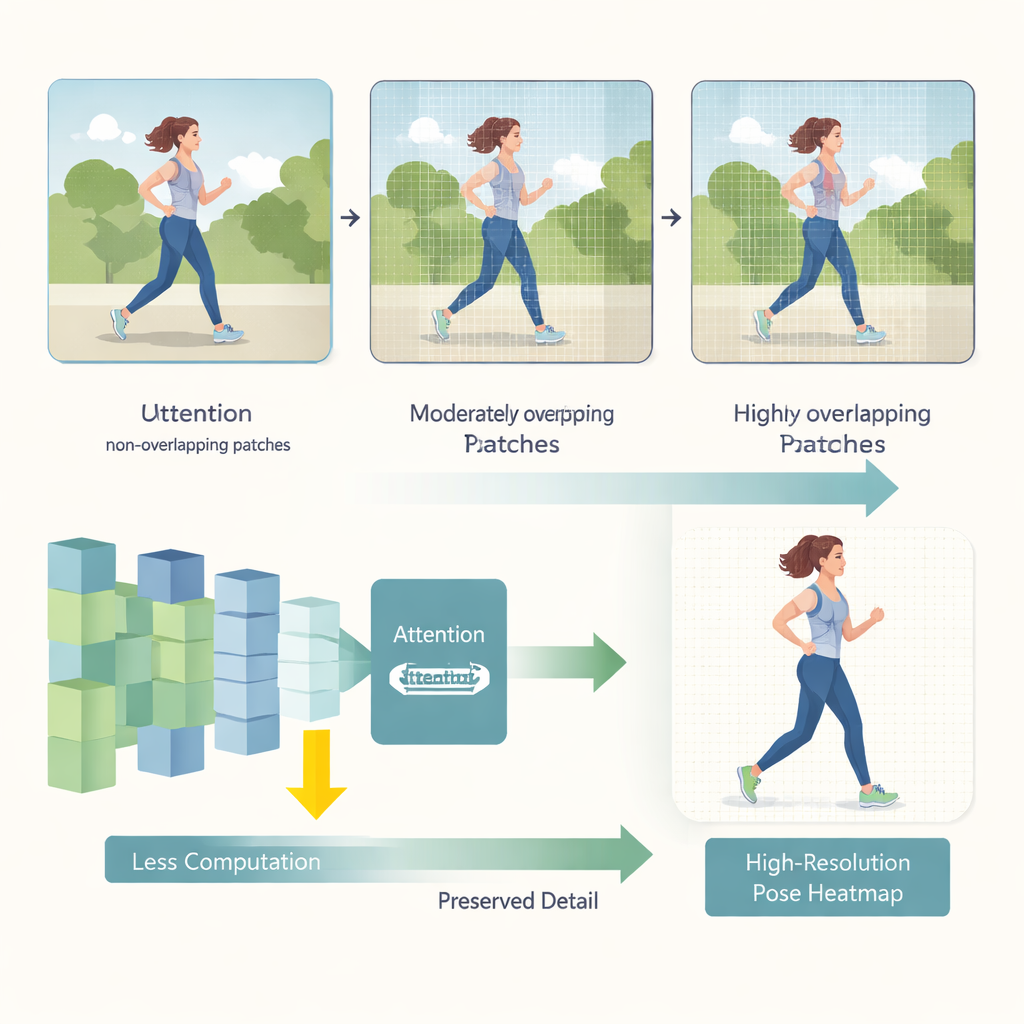
HEViTPose zaczyna od przemyślenia sposobu dzielenia obrazu na fragmenty do analizy. Wcześniejsze modele transformerowe często dzieliły obrazy na niepokrywające się kafelki, co może zaburzać ciągłość wizualną między sąsiadującymi obszarami — jakby przeciąć ramię osoby na krawędzi kafelka. HEViTPose opiera się na pomyśle nakładającego się osadzania patchy (overlapping patch embedding) i wprowadza czytelny, regulowany wskaźnik nazwany Patch Embedding Overlap Width (PEOW). PEOW po prostu określa, ile pikseli są wspólnych dla sąsiadujących kafelków wzdłuż ich krawędzi. Systematycznie zmieniając ten nakład, autorzy pokazują, że umiarkowane nachodzenie pozwala sieci lepiej „wyczuć” płynne przejścia koloru i kształtu między kafelkami. Ta bogatsza lokalna ciągłość prowadzi do dokładniejszego określania położeń stawów, bez znaczącego zwiększania rozmiaru modelu czy kosztu obliczeniowego.
Inteligentniejsza uwaga przy mniejszym koszcie
Drugą kluczową innowacją jest nowy moduł uwagi nazwany Cascaded Group Spatial Reduction Multi-Head Attention (CGSR-MHA). Mechanizmy uwagi informują sieć, które części obrazu powinny wpływać na dane predykcje, ale zazwyczaj ich koszt rośnie niekorzystnie wraz ze wzrostem rozmiaru obrazu. CGSR-MHA rozwiązuje to na trzy sposoby. Po pierwsze, dzieli cechy na grupy, dzięki czemu każda grupa zajmuje się tylko częścią informacji zamiast wszystkiego na raz. Po drugie, zmniejsza rozdzielczość przestrzenną wewnątrz każdej grupy przed obliczeniem uwagi, co znacznie redukuje liczbę operacji. Po trzecie, wykorzystuje kilka małych głów uwagi zamiast kilku dużych, zachowując różnorodność tego, na co model może „zwracać uwagę”, przy jednoczesnym obniżeniu kosztów. Starannie dobrane ustawienia liczby grup, stopnia redukcji i liczby głów osiągają równowagę między szybkością a dokładnością.
Modele lekkie, które nadal konkurują z najlepszymi
Aby przetestować HEViTPose, autorzy ocenili go na dwóch powszechnie używanych zestawach: MPII zawierającym codzienne aktywności ludzi oraz większym zbiorze COCO z ludźmi w wielu różnych scenach. W różnych rozmiarach modeli HEViTPose dorównuje lub niemal dorównuje dokładności wiodących systemów estymacji pozycji, jednocześnie używając znacznie mniej parametrów i mniejszej ilości obliczeń. Na przykład jedna wersja osiąga podobną dokładność do popularnej sieci wysokiej rozdzielczości (HRNet), przy zmniejszeniu liczby uczonych parametrów o ponad 60% i redukcji kosztu obliczeniowego o ponad 40%. W porównaniu z innym nowoczesnym modelem hybrydowym łączącym sploty i transformatory, HEViTPose daje podobne wyniki, ale działa na procesorze graficznym około 2,6 raza szybciej. Te oszczędności przekładają się bezpośrednio na płynniejsze działanie w czasie rzeczywistym i niższe wymagania sprzętowe.
Co to oznacza dla zastosowań codziennych
Mówiąc prosto, HEViTPose pokazuje, że nie trzeba wybierać między dokładnością a wydajnością przy uczeniu komputerów czytania mowy ciała. Poprzez staranne nakładanie badanych fragmentów obrazu i przeprojektowanie sposobu obliczania uwagi w sieci, system potrafi precyzyjnie wskazywać stawy, pozostając jednocześnie kompaktowym i szybkim. To czyni go atrakcyjnym do zastosowań w świecie rzeczywistym, takich jak śledzenie sportowe, monitoring wideo, interakcja człowiek–robot oraz monitorowanie kierowcy w samochodzie, gdzie liczy się zarówno szybkość, jak i zużycie energii. Pomysły stojące za HEViTPose — inteligentne nakładanie i wydajna uwaga — mogą też zostać zaadaptowane do pokrewnych zadań, jak śledzenie pozycji zwierząt czy wykrywanie punktów orientacyjnych twarzy, potencjalnie zapewniając ostrzejsze „cyfrowe oczy” wielu urządzeniom bez potrzeby superkomputerowego sprzętu.
Cytowanie: Wu, C., Chen, Z., Ying, B. et al. HEViTPose: towards high-accuracy and efficient 2D human pose estimation with cascaded group spatial reduction attention. Sci Rep 16, 5637 (2026). https://doi.org/10.1038/s41598-026-35859-x
Słowa kluczowe: estymacja pozycji człowieka, widzenie komputerowe, transformer wizji, wydajne uczenie głębokie, mechanizm uwagi