Clear Sky Science · pl
Hybrydowe podejście CNN i uczenia przez wzmacnianie do identyfikacji mówcy z użyciem cech Mel-spektrogramu i ciągłej transformacji falkowej
Dlaczego Twój głos może być cyfrowym kluczem
Wyobraź sobie odblokowywanie konta bankowego, drzwi wejściowych lub telefonu wyłącznie głosem. Aby było to bezpieczne, komputery muszą niezawodnie odróżniać jedną osobę od drugiej, nawet przy szumie w tle, emocjach czy słabym mikrofonie. W artykule badacze przedstawiają nowe podejście do nauczenia maszyn rozpoznawania, kto mówi, a nie tylko co mówi, łącząc nowoczesne techniki uczenia głębokiego z formą uczenia metodą prób i błędów zaczerpniętą z robotyki.
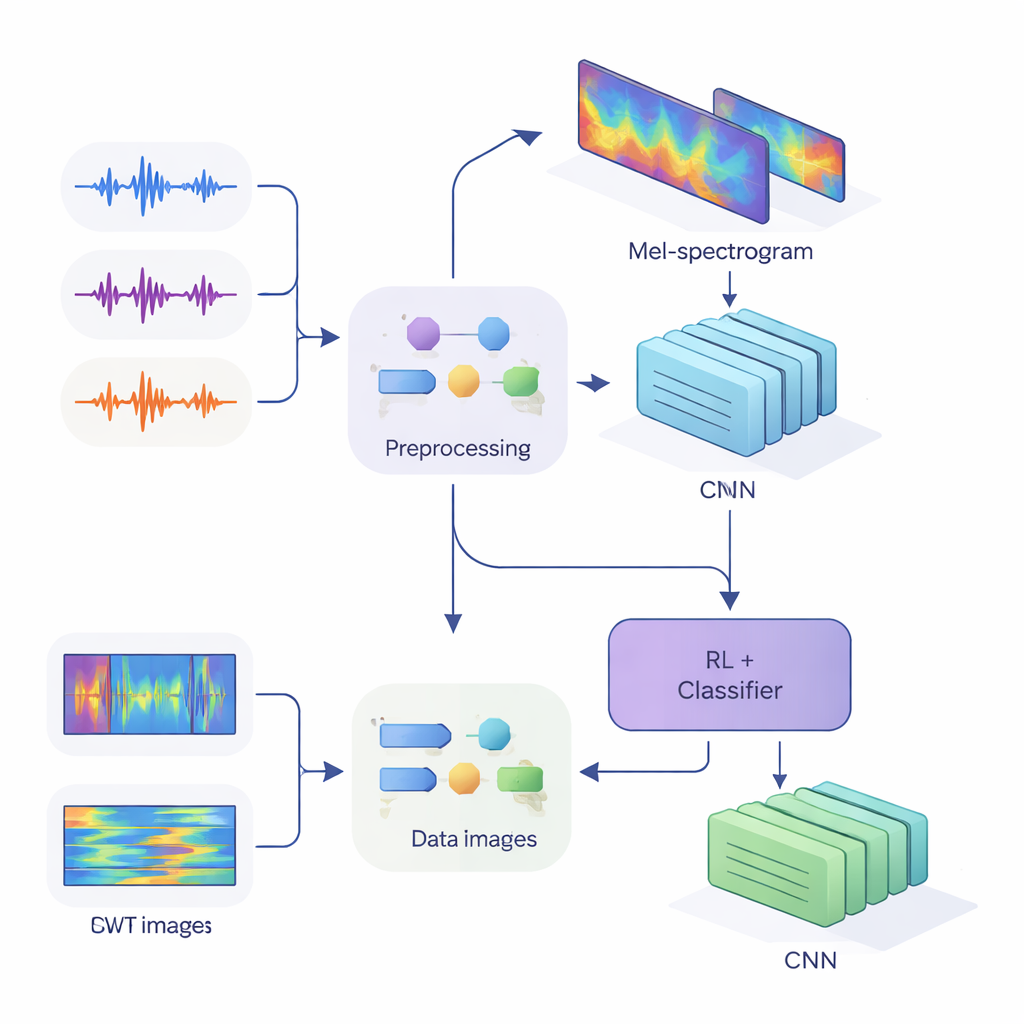
Od fal dźwiękowych do odcisków głosu
Głos każdej osoby niesie subtelne wskazówki kształtowane przez rozmiar i kształt dróg oddechowych, sposób drgania fałdów głosowych oraz styl mówienia. Badacze zaczęli od pytania: które mierzalne właściwości nagranego mówienia rzeczywiście różnią się między osobami? Korzystając z 2 703 klipów audio od 40 anglojęzycznych mówców z zestawu LibriSpeech, przeanalizowali 22 proste cechy akustyczne, takie jak zmienność głośności, energia w różnych pasmach częstotliwości, rytm czy miara nazywana entropią, odzwierciedlająca złożoność lub nieprzewidywalność dźwięku. Testy statystyczne wykazały, że 21 z 22 cech zawierało silne informacje specyficzne dla mówcy, przy czym entropia i energia w wysokich częstotliwościach wyróżniały się jako szczególnie rozróżniające. Innymi słowy „odcisk głosu” osoby rozciąga się na wiele aspektów dźwięku, nie tylko na wysokość czy głośność.
Dwa sposoby zamiany dźwięku na obrazy
Aby dostarczyć te wskazówki do współczesnych sieci neuronowych, zespół przekształcił jednowymiarowe sygnały audio w dwuwymiarowe obrazy, które uchwytują zmiany energii w czasie i częstotliwości. W pierwszym podejściu użyto Mel-spektrogramów, które naśladują sposób, w jaki ludzki słuch grupuje częstotliwości i są standardem w technologii mowy. W drugim zastosowano ciągłe transformaty falkowe, bardziej elastyczne narzędzie pozwalające przybliżać zarówno krótkie, ostre dźwięki, jak i dłuższe samogłoski. Po starannym oczyszczeniu nagrań — usunięciu ciszy, ujednoliceniu głośności i dodaniu drobnych zniekształceń, takich jak szum czy przesunięcia wysokości tonów, by zwiększyć odporność systemu — wygenerowano obrazy Mel o rozmiarze 80 na 313 oraz obrazy falkowe o rozmiarze 128 na 128, gotowe do przetworzenia przez splotowe sieci neuronowe (CNN).
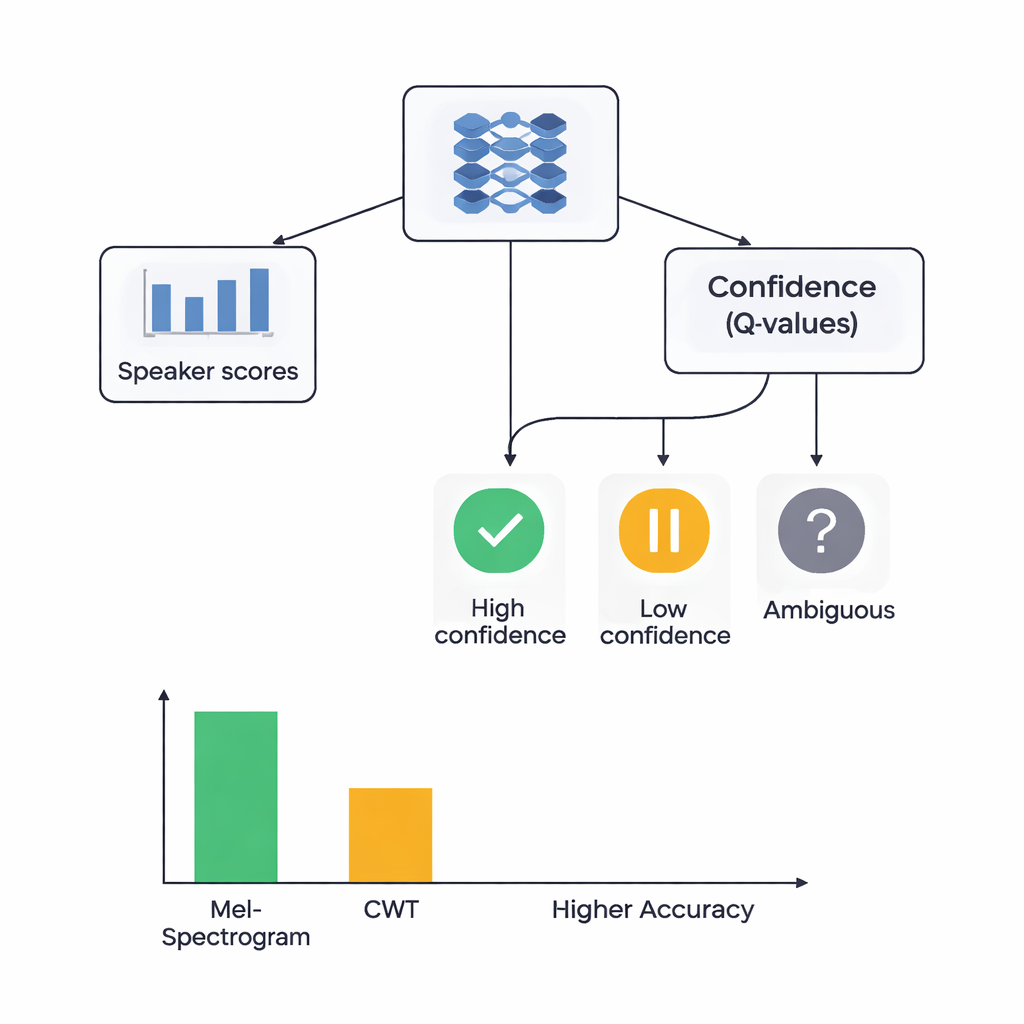
Nauczanie sieci słuchania i wątpienia
W centrum badań znajduje się hybrydowa architektura łącząca dwa style uczenia. Najpierw CNN przeglądają obrazy Mel lub falkowe, wydobywając wzorce charakterystyczne dla konkretnych mówców, podobnie jak sieci rozpoznawania obrazów uczą się wykrywać oczy czy krawędzie. W systemie opartym na Mel autorzy dodali moduł self-attention, który pozwala sieci koncentrować się na najbardziej informatywnych segmentach czasowych. Na szczycie tych ekstraktorów cech umieszczono komponent uczenia przez wzmacnianie (RL), który uczy się, jak pewny powinna być system w każdej decyzji. Zamiast zawsze podejmować twardy wybór, część RL przypisuje wartości do akcji takich jak „zaakceptuj jako wysoką pewność”, „traktuj jako niską pewność” lub „oznacz jako niejednoznaczne”. W trakcie licznych rund treningowych system jest nagradzany, gdy pewne decyzje są poprawne, co skłania sieć do lepiej skalibrowanych ocen.
Jak dobrze działa system hybrydowy?
Badacze porównali cztery modele: oparty na Mel z RL, oparty na Mel bez RL, oparty na falkach z RL oraz oparty na falkach bez RL. Wszystkie testowano z użyciem starannej walidacji krzyżowej pięciokrotnej, co oznaczało, że każdy klip audio służył zarówno do trenowania, jak i do testowania w różnych rundach. System Mel z RL wypadł najlepiej, poprawnie identyfikując mówcę w około 88% przypadków i wykazując niemal doskonałe rozdzielenie mówców według standardowej miary zdolności dyskryminacyjnej. System falkowy z RL osiągnął około 78% dokładności. Co ważne, dodanie komponentu RL poprawiło wyniki dla obu typów cech o około 3 punkty procentowe i uczyniło wyniki bardziej spójnymi między różnymi podziałami danych. Więcej klas mówców uzyskało wysoką jakość rozpoznawania przy uwzględnieniu RL, co sugeruje, że decyzje uwzględniające pewność szczególnie pomogły w trudnych, łatwo mylonych głosach.
Co to oznacza dla codziennego bezpieczeństwa głosowego
Dla osób niebędących specjalistami kluczową myślą jest to, że wiarygodne weryfikacje tożsamości oparte na głosie wymagają zarówno bogatych reprezentacji dźwięku, jak i zdrowego poczucia wątpliwości ze strony maszyny. Badanie pokazuje, że inspirowane słuchem Mel-spektrogramy, połączone z mechanizmem uwagi i uczącym się przez wzmacnianie modułem, który potrafi powiedzieć „nie jestem pewien”, przewyższają bardziej egzotyczne obrazy falkowe w zadaniu rozróżniania mówców. Choć badanie używa stosunkowo małego, czystego zbioru danych i nie jest jeszcze dostrojone do hałaśliwych, rzeczywistych warunków, demonstruje, że dodanie warstwy świadomej pewności nad sieciami głębokimi może uczynić uwierzytelnianie głosowe zarówno dokładniejszym, jak i bardziej godnym zaufania — ważny krok, jeśli nasze głosy mają stać się bezpiecznymi cyfrowymi kluczami.
Cytowanie: Heir, F.M., Najafzadeh, H. & Erfani, S. A hybrid CNN and reinforcement learning framework for speaker identification using Mel-Spectrogram and continuous wavelet transform features. Sci Rep 16, 5954 (2026). https://doi.org/10.1038/s41598-026-35858-y
Słowa kluczowe: identyfikacja mówcy, biometria głosowa, uczenie głębokie, uczenie przez wzmacnianie, Mel-spektrogramy