Clear Sky Science · pl
Ogólne ramy adaptacyjnej nieparametrycznej redukcji wymiarowości
Dlaczego zmniejszanie dużych zbiorów danych ma znaczenie
Współczesne życie opiera się na danych: skany medyczne, historie zakupów online, zdjęcia, strumienie wiadomości i wiele innych. Każdy rekord może zawierać setki lub tysiące pomiarów, co utrudnia ich przechowywanie, analizę czy nawet wizualizację. Naukowcy stosują „redukcję wymiarowości”, aby skompresować tę złożoność do prostszych obrazów i modeli, zachowując przy tym istotne wzorce. Jednak popularne dziś narzędzia często wymagają wielu ręcznych wyborów i poprawiania metodą prób i błędów. Ten artykuł przedstawia sposób pozwalający danym samym zdecydować, jak najlepiej się skurczyć, dążąc do jaśniejszych obrazów, dokładniejszego uczenia i mniejszej liczby domysłów ze strony użytkownika.
Od prostych linii do zakrzywionej rzeczywistości
Klasowym narzędziem upraszczającym dane jest analiza składników głównych (PCA), działająca niczym oświetlenie obiektu i obserwowanie jego cienia: znajduje najlepsze płaskie kierunki wyjaśniające większość zmienności. To potężne podejście, gdy struktura danych jest w przybliżeniu prosta lub płaska. Jednak prawdziwe dane — takie jak obrazy, teksty czy odczyty czujników — często leżą na zakrzywionych powierzchniach ukrytych w przestrzeni o wysokiej wymiarowości. W ciągu ostatnich dwóch dekad powstały nowe, „nieliniowe” metody, takie jak Isomap, Locally Linear Embedding (LLE), osadzanie spektralne i UMAP, zaprojektowane specjalnie do odkrywania tych krętych kształtów. Polegają one na lokalnych sąsiedztwach: dla każdego punktu patrzą na jego najbliższych sąsiadów i próbują zachować te małoskalowe relacje przy rysowaniu niższej wymiarowości. Jednak te metody zmuszają użytkownika do wyboru dwóch kluczowych parametrów: ile sąsiadów użyć i na ile wymiarów rzutować. Zły wybór może prowadzić do mylących wyników lub wysokich kosztów obliczeniowych.
Pozwolić danym wybrać własne sąsiedztwo
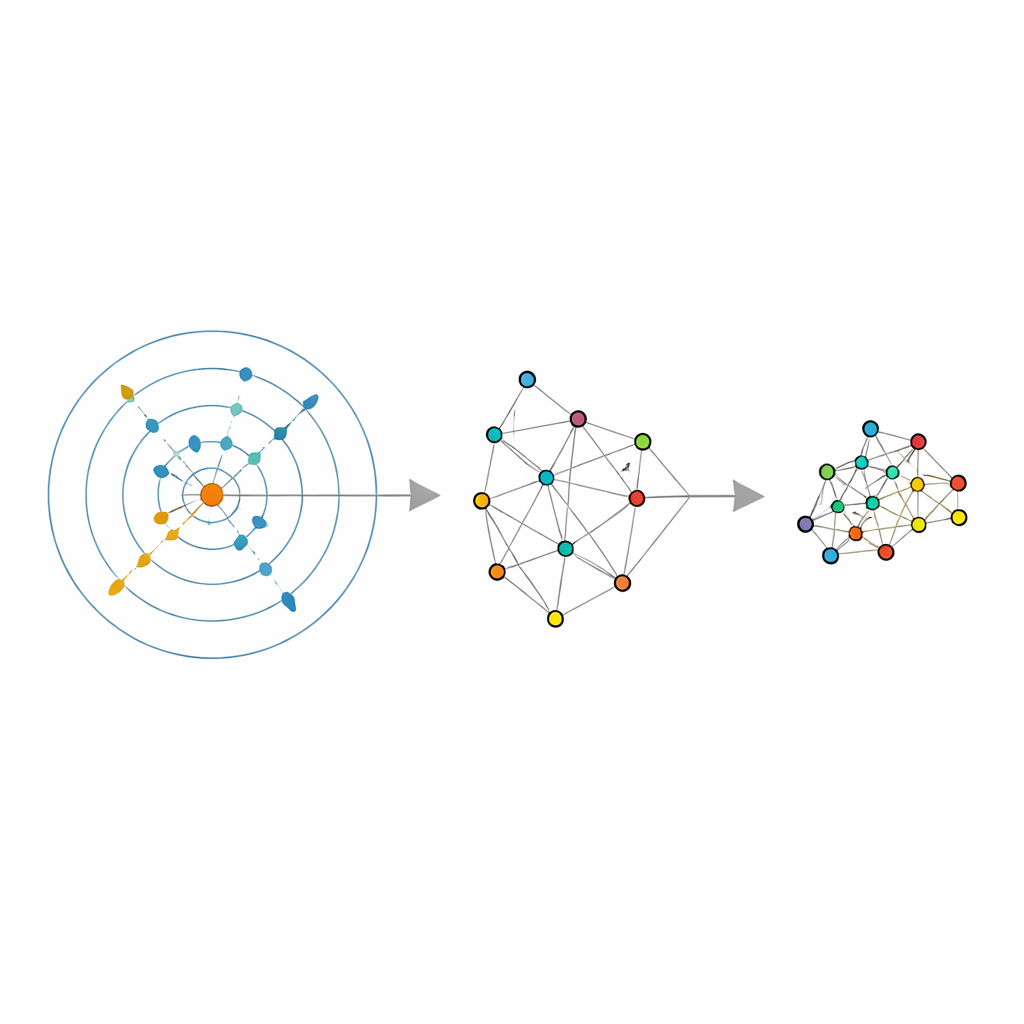
Autorzy opierają się na niedawnym narzędziu statystycznym zwanym estymatorem wymiaru wewnętrznego, które stara się odpowiedzieć na proste pytanie: w ilu niezależnych kierunkach dane rzeczywiście się zmieniają, po odfiltrowaniu szumu? Ich estymator, nazwany ABIDE, idzie dalej. Wokół każdego punktu automatycznie wyszukuje on takie sąsiedztwo, które wydaje się względnie jednorodne — ani zbyt małe i zawierające szum, ani zbyt duże i zdeformowane. W ten sposób zwraca dwie informacje: globalną estymację prawdziwej wymiarowości danych oraz dostosowany rozmiar sąsiedztwa dla każdego punktu. Dzięki temu zwykła stała liczba sąsiadów staje się lokalnie adaptacyjną wielkością, która może rosnąć w rzadkich obszarach i kurczyć się w zatłoczonych, dopasowując się do rzeczywistej gęstości danych.
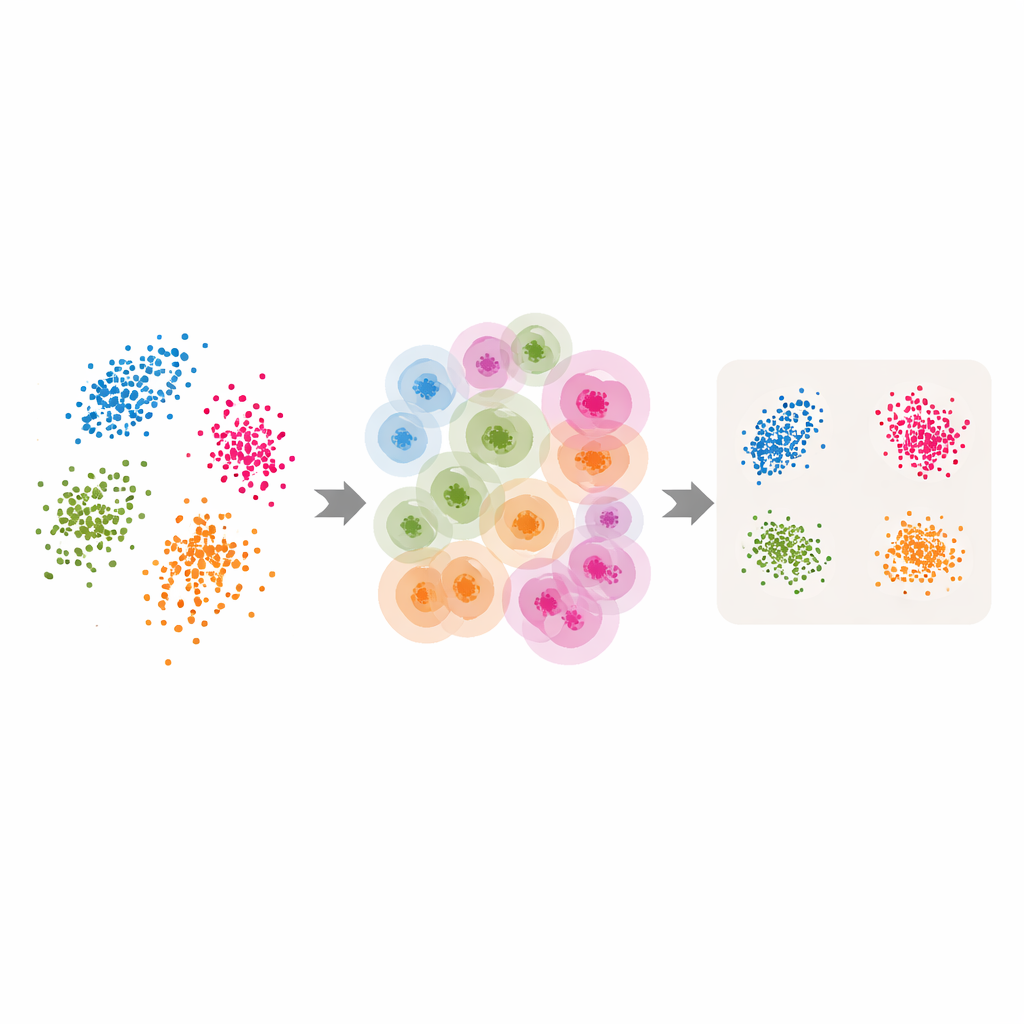
Przekształcanie klasycznych narzędzi w adaptacyjne
Wyposażeni w te adaptacyjne sąsiedztwa i oszacowaną wymiarowość wewnętrzną, autorzy dostosowują kilka popularnych metod redukcji wymiarowości i grupowania. W LLE zastępują pojedynczą, wybraną przez użytkownika liczbę sąsiadów wartościami per‑punkt zwracanymi przez ABIDE, a wymiar docelowy ustalają równy oszacowanej wymiarowości wewnętrznej. Algorytm uczy się wtedy rekonstruować każdy punkt z odpowiednio dobranej lokalnej grupy, po czym znajduje globalne niskowymiarowe ułożenie, które najlepiej zachowuje te lokalne rekonstrukcje. Podobne pomysły stosuje się w grupowaniu spektralnym — gdzie do grupowania używana jest grafowa reprezentacja podobieństw między punktami — oraz w UMAP, które buduje rozmytą mapę połączeń między punktami. W każdym przypadku sztywna wielkość sąsiedztwa zostaje zastąpiona elastyczną, napędzaną przez dane strukturą, która podąża za naturalną geometrią zbioru danych.
Testy na kwiatach, cyfrach, tekstach i kształtach syntetycznych
Aby sprawdzić, czy podejście adaptacyjne się opłaca, autorzy przeprowadzają eksperymenty na kilku benchmarkach: klasycznych pomiarach irysa, obrazach odręcznych cyfr (MNIST), artykułach prasowych reprezentowanych przez osadzenia modeli językowych oraz syntetycznych trójwymiarowych kształtach z dodanym szumem. Porównują wersje adaptacyjne ze standardowymi ustawieniami oprogramowania oraz z dokładnie dostrojonymi siatkami hiperparametrów. W zadaniach bez nadzoru, takich jak grupowanie i wizualizacja, metody adaptacyjne zwykle dają wyraźniejsze klastry, ściślejsze grupowania i lepsze wyniki w standardowych miarach jakości. Na przykład na złożonych rozmaitościach o nierównomiernej gęstości punktów metody adaptacyjne odzyskują prawdziwą strukturę znacznie lepiej niż wersje ze stałą liczbą sąsiadów. W testach nadzorowanych, gdzie zredukowane dane są podawane do klasyfikatora, podejście adaptacyjne ponownie dorównuje lub przewyższa najlepsze ustawienia stałe, bez potrzeby wyczerpującego strojenia.
Co to oznacza dla codziennej analizy danych
Dla nieekspertów i praktyków główny przekaz jest taki, że zmniejszanie danych nie musi opierać się na domysłach. Dzięki wykorzystaniu własnej geometrii danych do decyzji „ile sąsiadów” i „na ile wymiarów”, ta rama zamienia szeroko stosowane narzędzia, takie jak LLE, grupowanie spektralne i UMAP, w ich inteligentniejsze, bardziej odporne wersje. Efektem są bardziej wiarygodne widoki w niskiej wymiarowości — wykresy i cechy lepiej odzwierciedlające prawdziwy kształt danych — przy jednoczesnym skróceniu czasu poświęcanego na ręczne przeszukiwanie hiperparametrów. W praktyce oznacza to, że zadania takie jak wizualizacja dużych zbiorów obrazów, grupowanie dokumentów czy przygotowywanie wejść do modeli predykcyjnych mogą stać się prostsze i bardziej niezawodne, jeśli pozwoli się danym adaptacyjnie kierować sposobem ich kompresji.
Cytowanie: Di Noia, A., Ravenda, F. & Mira, A. A general framework for adaptive nonparametric dimensionality reduction. Sci Rep 16, 9028 (2026). https://doi.org/10.1038/s41598-026-35847-1
Słowa kluczowe: redukcja wymiarowości, uczenie się rozmaitości, najbliżsi sąsiedzi, wymiar wewnętrzny, wizualizacja danych