Clear Sky Science · pl
Metody jądrowe kwantowe dla analityki marketingowej z teorią zbieżności i granicami separacji
Dlaczego ważne są lepsze prognozy dotyczące klientów
Firmy coraz częściej opierają decyzje o tym, którym klientom kierować oferty, wsparcie czy kampanie retencyjne na danych. W miarę jak dane stają się bardziej złożone, tradycyjne narzędzia mogą mieć trudności ze wychwyceniem subtelnych wzorców — a każdy przeoczony klient o wysokiej wartości bywa kosztowny. W artykule badane jest, czy rozwijające się komputery kwantowe — maszyny wykorzystujące zasady fizyki kwantowej — mogłyby poprawić takie prognozy w zadaniach marketingowych, przy czym autorzy uwzględniają obecny, niedoskonały i „szumiały” sprzęt.

Od rekordów klientów do układów kwantowych
Autorzy koncentrują się na praktycznym zadaniu, które nazywają klasyfikacją konsumentów: przewidywaniu, którzy użytkownicy zaangażują się lub przyjmą usługę cyfrową. Każdy użytkownik jest opisany przez niewielki zbiór cech numerycznych, takich jak dane demograficzne i zachowanie na platformie. Zamiast wprowadzać te dane bezpośrednio do standardowego algorytmu, najpierw kodują je w stanach kilku kubitów przy użyciu zwartego obwodu kwantowego. Obwód ten działa jak transformacja cech, przekształcając dane w formę, którą może być łatwiej rozdzielić na dwie grupy — „prawdopodobnie się zaangażuje” i „mało prawdopodobne, że się zaangażuje”. Na tej kwantowej transformacji opierają znaną metodę klasyfikacji, maszynę wektorów nośnych, w kwantowej odsłonie zwanej Q-SVM (quantum-kernel SVM).
Testowanie kwantowych pomysłów w realistycznych warunkach
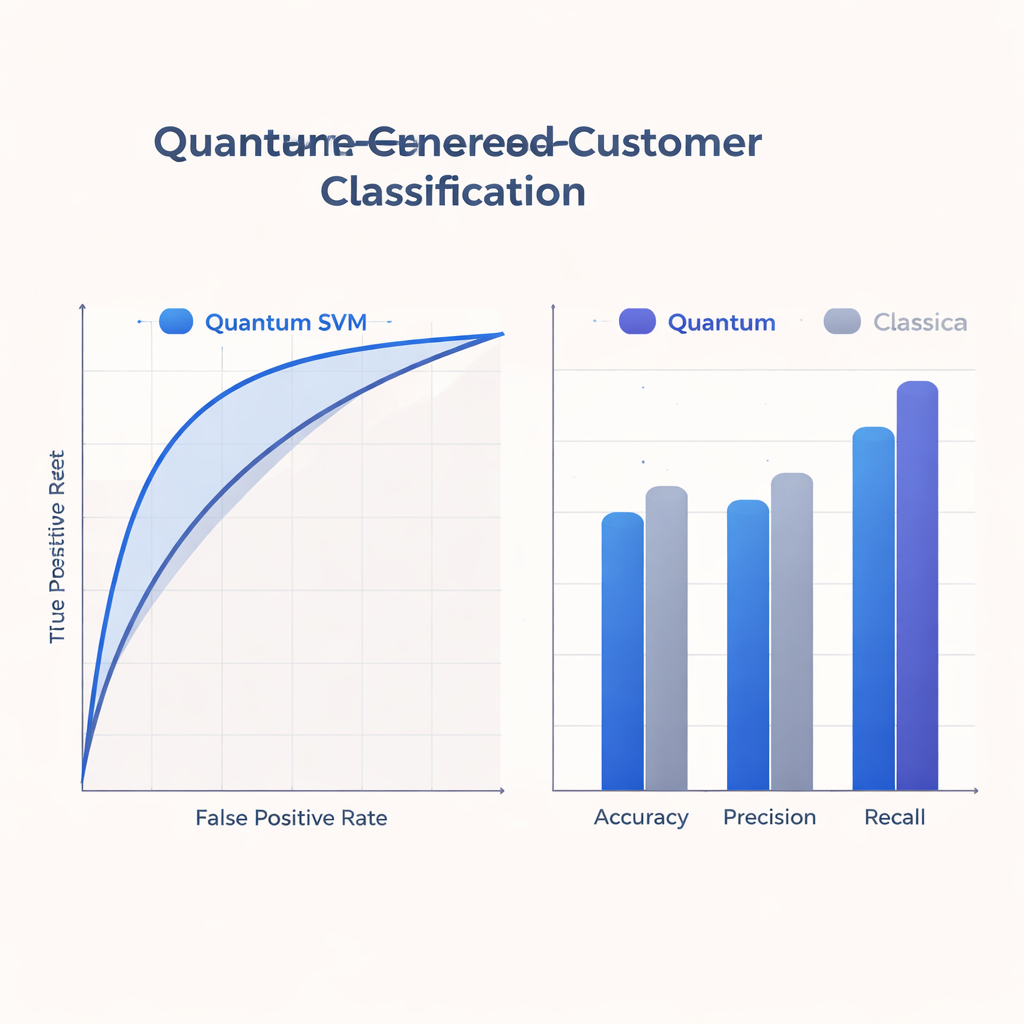
Ponieważ dzisiejsze urządzenia kwantowe są małe i podatne na błędy, badanie ogranicza się do płytkich obwodów zgodnych z możliwościami sprzętu dostępnego w najbliższej przyszłości. Zespół trenuje i ocenia swoje Q-SVM na rzeczywistym, zanonimizowanym zestawie danych zawierającym około 500 przypadków treningowych i 125 testowych z ośmioma cechami na użytkownika, symulując zarówno idealne, jak i zaszumione zachowanie kwantowe. Porównują podejście kwantowe ze silnymi klasycznymi punktami odniesienia wykorzystującymi popularne metody jądrowe na standardowych komputerach. Wskaźniki takie jak trafność, precyzja, recall (czułość) oraz pole pod krzywą ROC (podsumowanie kompromisów między wykrywaniem prawdziwych pozytywów a unikaniem fałszywych alarmów) pokazują, że Q-SVM osiąga wyniki konkurencyjne lub lepsze, ze szczególnie silnym recall: poprawnie identyfikuje wyższy odsetek rzeczywiście zainteresowanych użytkowników niż modele klasyczne.
Teoretyczne gwarancje w tle
Poza surową wydajnością, artykuł stawia głębsze pytanie: kiedy można oczekiwać, że metody kwantowe w ogóle pomogą? Autorzy rozwijają trzy główne wyniki teoretyczne. Po pierwsze, wykazują, że jeśli problem uczenia spełnia pewne warunki gładkości, a obwody kwantowe pozostają płytkie, proces trenowania jąder kwantowych powinien zbiegać się niezawodnie w rozsądnej liczbie kroków. Po drugie, przedstawiają granice separacji sugerujące, że ich kwantowe wydobywanie cech może, przy określonych założeniach, powiększyć dystans między dwoma klasami klientów w porównaniu z transformacjami klasycznymi — w praktyce ułatwiając rozwiązanie zadania. Po trzecie, analizują, jak metody przybliżone mogą dramatycznie obniżyć koszty pracy z dużymi przestrzeniami cech pochodzącymi z kwantów, dzięki czemu podejście pozostaje wykonalne obliczeniowo.
Co to może znaczyć dla marketerów
Dla zespołów zajmujących się marketingiem i analityką klientów najkonkretniejszy zysk polega na tym, jak model kwantowy równoważy utracone szanse względem nieefektywnego dotarcia. Wyższy recall Q-SVM oznacza mniejsze prawdopodobieństwo przeoczenia użytkowników, którzy pozytywnie zareagowaliby na ofertę — kluczowa zaleta w kampaniach retencyjnych lub proaktywnych usługach. Jednocześnie jego precyzja i ogólna trafność pozostają na poziomie porównywalnym z silnymi klasycznymi modelami, wspierane solidną krzywą ROC. Ponieważ metoda dobrze działa w szerokim zakresie progów decyzyjnych, zespoły mogą regulować, jak agresywne lub ostrożne chcą być — preferując albo recall, albo precyzję — bez potrzeby każdorazowego retrenowania modelu.
Obiecujący początek, nie rewolucja kwantowa (jeszcze)
Autorzy podkreślają, że ich ustalenia to wczesne kroki, a nie dowód na wszechstronną przewagę kwantów. Wyniki pochodzą z symulacji na jednym zbiorze danych, a nie z dużych uruchomień na rzeczywistym sprzęcie czy z wielu rynków. Ich matematyczne gwarancje opierają się też na idealizowanych założeniach, które mogą nie w pełni obowiązywać na zaszumionych urządzeniach. Mimo to praca pokazuje, że starannie zaprojektowane kwantowe jądra już dziś mogą dorównywać lub nieco przewyższać dobre metody klasyczne w realistycznym zadaniu konsumenckim, oferując jednocześnie jasną ścieżkę do większych korzyści w miarę rozwoju sprzętu kwantowego. Dla czytelników wniosek jest taki, że kwantowe uczenie maszynowe przesuwa się od abstrakcyjnej obietnicy ku narzędziom, które pewnego dnia mogą uczynić prognozy dotyczące klientów bardziej dokładnymi i elastycznymi w warunkach biznesowych.»
Cytowanie: Sáez Ortuño, L., Forgas Coll, S. & Ferrara, M. Quantum kernel methods for marketing analytics with convergence theory and separation bounds. Sci Rep 16, 6645 (2026). https://doi.org/10.1038/s41598-026-35793-y
Słowa kluczowe: kwantowe uczenie maszynowe, analityka marketingowa, klasyfikacja klientów, maszyny wektorów nośnych, kwantowe jądra