Clear Sky Science · pl
Fuzja obrazów w podczerwieni i w paśmie widzialnym przez wzmocnienie wizualne i sprzężenie semantyczne
Bardziej ostre widzenie dzięki kamerom dziennym i nocnym
Współczesne samochody, drony i systemy zabezpieczeń często dysponują dwoma rodzajami „oczu”: zwykłą kamerą rejestrującą kolor i fakturę oraz kamerą podczerwieni rejestrującą ciepło. Każda z nich ma swoje mocne i słabe strony, a połączenie ich w jeden czytelny obraz jest zaskakująco trudne. Artykuł przedstawia nowy sposób łączenia tych dwóch widoków w jeden obraz, który jest nie tylko przyjemniejszy dla oka, lecz także łatwiejszy do interpretacji dla programów komputerowych.
Dlaczego dwa „oczy” są lepsze niż jedno
Kamera w paśmie widzialnym uchwyca ostre detale, takie jak oznakowanie drogi, krawędzie budynków czy elementy ubioru, ale ma trudności w nocy, we mgle lub gdy obiekty zlewają się z tłem. Kamery podczerwieni robią odwrotnie: uwypuklają ciepłe obiekty, takie jak ludzie i pojazdy, nawet w ciemności, lecz ich obrazy bywają rozmyte i pozbawione drobnych szczegółów. Fuzja tych dwóch widoków w obraz „z najlepszego z obu światów” może pomóc w zadaniach od wykrywania pieszych w systemach wspomagania kierowcy po nadzór i akcje poszukiwawczo-ratownicze. Jednak wiele istniejących metod fuzji skupia się tylko na powierzchownych cechach — jasnych plamach z podczerwieni i teksturach z obrazu widzialnego — zaniedbując głębsze, sceniczne znaczenie, które jest istotne dla inteligentnych maszyn.
Inteligentniejszy sposób łączenia obrazów
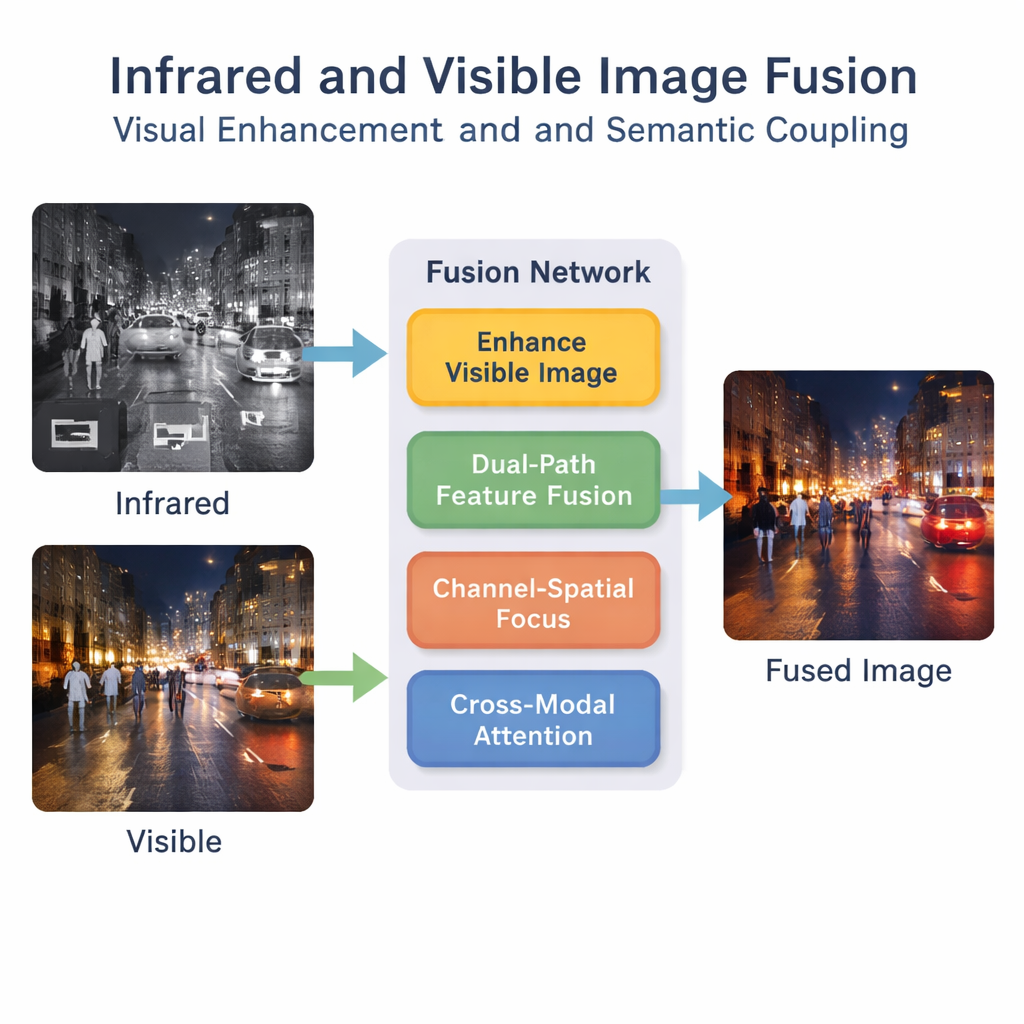
Autorzy proponują ramy oparte na uczeniu głębokim, które traktują fuzję jako coś więcej niż proste nałożenie obrazów. Najpierw specjalny etap wzmocnienia rozjaśnia i wyrównuje obraz widzialny, zwłaszcza w scenach słabo oświetlonych, tak aby cenne detale nie zniknęły zanim zacznie się fuzja. Następnie dwutorowa sieć przetwarza wejścia z podczerwieni i widzialnego równolegle. Jeden tor koncentruje się na lokalnych wzorcach, takich jak krawędzie i tekstury, podczas gdy drugi analizuje szerszy kontekst sceny. Łącząc te tory, system tworzy bogatszy wewnętrzny opis tego, co dzieje się na obrazach.
Nauczenie sieci, na co zwracać uwagę
Samo wydobycie wielu cech nie wystarcza; sieć musi nauczyć się, które z nich są ważne. Moduł „kanał–przestrzeń” pomaga modelowi uwypuklić krytyczne regiony i typy informacji, takie jak piesi czy jasne reflektory, jednocześnie tłumiąc mniej przydatny szum tła. Ponadto bimodalny mechanizm uwagi interaktywnej zachęca strumienie podczerwieni i widzialnego do wzajemnej komunikacji. Uczy się on, jak sygnatury cieplne i tekstury wizualne korelują w całej scenie, wychwytując wyższe poziomy znaczeń, na przykład „ta jasna plama w podczerwieni odpowiada tej osobie na obrazie widzialnym”. To sprzężenie semantyczne pomaga, by obraz po fuzji był spójny logicznie, a nie tylko wizualnie zblendowany.

Sprawdzenie metody w praktyce
Aby zweryfikować, czy obrazy po fuzji są nie tylko atrakcyjne, lecz także realistyczne, autorzy dodają sieć dyskryminatora podobną do tych stosowanych w sieciach przeciwstawnych generatywnych. Dodatkowa sieć uczy się odróżniać prawdziwe obrazy widzialne od obrazów po fuzji, co wymusza na procesie fuzji tworzenie wyników wyglądających naturalnie zarówno dla ludzi, jak i maszyn. Metoda jest trenowana i testowana na trzech wymagających zbiorach par obrazów podczerwieni–widzialnych, obejmujących drogi w dzień i w nocy oraz sceny o charakterze militarnym. W zakresie standardowych miar jakości nowe podejście zwykle przewyższa dziesięć istniejących technik fuzji, generując obrazy z ostrzejszymi krawędziami, lepszym kontrastem i bardziej informacyjną treścią.
Lepsze obrazy dla bezpieczniejszych maszyn
Ponad jakością wizualną autorzy stawiają praktyczne pytanie: czy takie obrazy po fuzji pomagają komputerom podejmować lepsze decyzje? Używając popularnego systemu detekcji obiektów do wykrywania pieszych, pokazują, że obrazy po fuzji poprawiają dokładność wykrywania w porównaniu z obrazami z pojedynczego sensora oraz wcześniejszymi metodami fuzji. Mówiąc prościej, technika tworzy obrazy łatwiejsze do interpretacji zarówno dla ludzi, jak i algorytmów, zwłaszcza w trudnych warunkach, takich jak jazda nocą. Choć system nadal wymaga dostrojenia do zastosowań w czasie rzeczywistym na urządzeniach o ograniczonych zasobach, stanowi obiecujący krok w kierunku bezpieczniejszego i bardziej niezawodnego widzenia w pojazdach autonomicznych, systemach nadzoru i innych technologiach, które muszą widzieć wyraźnie, gdy to najważniejsze.
Cytowanie: Yang, Y., Li, Y., Li, J. et al. Infrared and visible image fusion via visual enhancement and semantic coupling. Sci Rep 16, 5666 (2026). https://doi.org/10.1038/s41598-026-35763-4
Słowa kluczowe: fuzja obrazów, obrazowanie w podczerwieni, widzenie przy słabym oświetleniu, uczenie głębokie, detekcja obiektów