Clear Sky Science · pl
Uczenie maszynowe do szybkiego oszacowania makrosejsmicznej intensywności na podstawie danych sejsmometrycznych we Włoszech
Dlaczego szybkie szacunki trzęsień są istotne
Kiedy ziemia zaczyna drżeć, zespoły ratunkowe mają zaledwie kilka minut, by zdecydować, gdzie skierować ratowników i zasoby. Tymczasem zwykły sposób opisywania, jak silnie odczuwalne jest trzęsienie na powierzchni — intensywność makrosejsmiczna, np. skala Mercallego używana we Włoszech — często pojawia się dopiero po godzinach, dniach, a nawet miesiącach, po wypełnieniu ankiet przez mieszkańców i dokonaniu przez ekspertów oględzin szkód. Artykuł bada, jak współczesne metody uczenia maszynowego mogą przekształcić pierwsze odczyty sejsmometrów w szybkie, stosunkowo dokładne mapy odczuwalności wstrząsów, pomagając władzom reagować szybciej i z większą pewnością.
Od raportów odczuwalności do szybkich estymacji
Tradycyjne szacunki intensywności we Włoszech opierają się na dwóch głównych strumieniach danych. Pierwszy to eksperckie oględziny terenowe rejestrowane w urzędowej bazie danych, które koncentrują się na uszkodzonych miejscach, ale wymagają czasu na organizację. Drugi pochodzi z internetowego systemu „Hai Sentito Il Terremoto”, gdzie obywatele zgłaszają, co czuli i zobaczyli, dostarczając wielu obserwacji o niskiej i umiarkowanej intensywności. Oba źródła mierzą intensywność na skali Mercalli–Cancani–Sieberg, która klasyfikuje drgania od bardzo słabych po destrukcyjne na podstawie reakcji ludzi i budynków. Aby powiązać te dane skoncentrowane na ludziach z odczytami instrumentów, autorzy połączyli oba zbiory wokół każdej stacji sejsmicznej, uśredniając wszystkie zgłoszone intensywności w promieniu 5 km, aby uzyskać jedną reprezentatywną wartość dla tego obszaru i zaokrąglając ją do całkowitej klasy od 1 do 8.
Nauka „lasu” modeli rozpoznawania drgań
Badacze sformułowali estymację intensywności jako problem klasyfikacji: na podstawie wczesnych pomiarów przewidzieć, która z ośmiu klas intensywności będzie obowiązywać w otoczeniu każdej stacji. Zastosowali Random Forest — zespół wielu drzew decyzyjnych, z których każde wykonuje prostą serię podziałów „jeżeli–to” na danych, np. kombinacje magnitudy, głębokości, odległości od źródła oraz bezpośrednich miar ruchu gruntu, takich jak maksymalne przyspieszenie, prędkość i przemieszczenie. Trenowany na 5 466 obserwacjach z 523 trzęsień we Włoszech (2008–2020) model nauczył się złożonych, nieliniowych zależności między tym, co rejestrują sejsmometry, a tym, co zgłaszają ludzie. Aby poradzić sobie z tym, że silne wstrząsy są rzadsze w danych, autorzy dostosowali trening tak, by wszystkie poziomy intensywności liczyły się jednakowo, zapobiegając skupieniu modelu wyłącznie na najczęstszych, słabszych zdarzeniach.
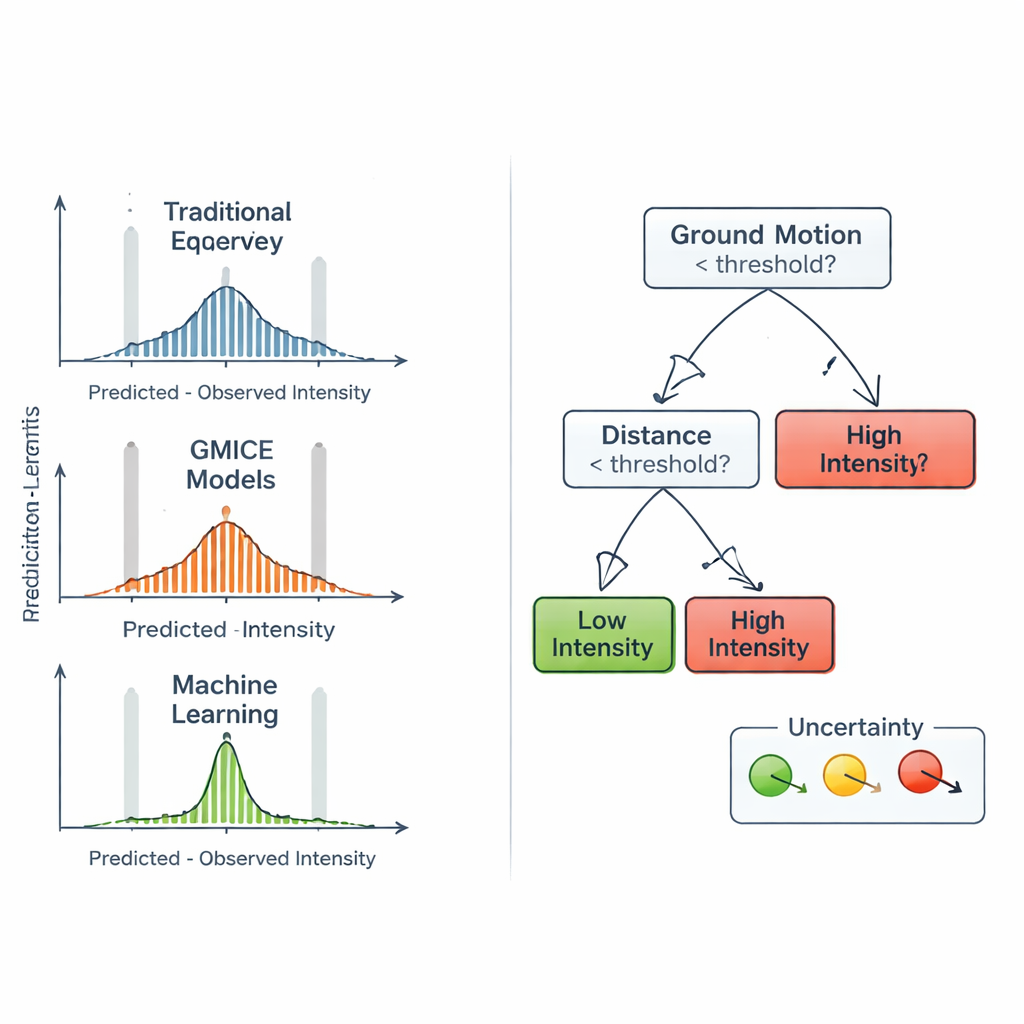
Porównanie z ustalonymi regułami
Aby sprawdzić, czy podejście oparte na uczeniu maszynowym rzeczywiście wnosi wartość, zespół porównał jego prognozy z dwiema powszechnie stosowanymi rodzinami relacji empirycznych. Pierwsza, zwana równaniami przewidywania intensywności (Intensity Prediction Equations), szacuje intensywność głównie na podstawie magnitudy, głębokości i odległości, zakładając, że drgania słabną z odległością w sposób gładki. Druga, równania konwersji ruchu gruntu na intensywność (Ground Motion to Intensity Conversion Equations), przekształcają instrumentalne odczyty szczytowych ruchów w oczekiwane klasy intensywności. Te formuły są zwarte i łatwe w stosowaniu, ale nie potrafią w pełni uchwycić wpływu lokalnej geologii, zasobów budynków czy kierunku fal na odczuwalność drgań. W przeciwieństwie do nich Random Forest naturalnie integruje zarówno parametry źródła, jak i miary ruchu gruntu, i może dopasować się do subtelnych wzorców w włoskim zbiorze danych bez uprzedniego narzucania sztywnej postaci matematycznej.
Zajrzeć do „czarnej skrzynki” i poznać jej ograniczenia
Ponieważ zarządzający sytuacjami kryzysowymi muszą rozumieć podstawy automatycznych decyzji, autorzy zbudowali prostsze „surrogatowe” drzewa decyzyjne, które naśladują zachowanie Random Foresta. Te mniejsze drzewa można przedstawić jako schematy, pokazujące, które progi miar ruchu gruntu rozdzielają niską i wysoką intensywność oraz gdzie dominują zmienne takie jak przyspieszenie i prędkość. Analiza ta ujawniła, że bezpośrednie miary ruchu gruntu, zwłaszcza szczytowe przyspieszenie i prędkość, mają większe znaczenie niż sama magnituda czy głębokość. Autorzy wprowadzili też prosty sposób oznaczania niepewności każdej prognozy drzewa-surrogata, wykorzystując miary stopnia mieszania przykładów treningowych w każdej końcowej gałęzi. Jednocześnie stwierdzili, że bardzo silne intensywności nadal są trudne do przewidzenia, częściowo dlatego, że są naturalnie rzadkie w zapisie historycznym, co prowadzi do okazjonalnego niedoszacowania najwyższych poziomów drgań.
Test w rzeczywistych warunkach podczas niedawnego trzęsienia we Włoszech
Zespół ocenił swój system na przykładzie znaczącego zdarzenia: trzęsienia o magnitudzie 5,5 u wybrzeży Adriatyku w pobliżu Pesaro-Urbino w 2022 roku. W ciągu około 15 minut sejsmolodzy dysponowali niezbędnymi informacjami o źródle i ruchu gruntu, ale zgłoszeń publicznych było tylko około 90, co dawało bardzo niepełny obraz. Używając wyłącznie danych instrumentalnych, Random Forest i jego drzewo-surrogat wygenerowały szczegółowe estymacje intensywności wokół setek stacji w czasie poniżej dwóch sekund na standardowym komputerze. W porównaniu później z dużo gęstszą mapą zbudowaną na podstawie ponad 12 000 raportów obywatelskich zebranych w ciągu dni, mapy uczenia maszynowego dobrze odzwierciedliły zarówno ogólny obszar odczuwalności, jak i rozkład umiarkowanych wstrząsów, i dorównały lub przewyższyły klasyczne równania.
Co to oznacza dla ludzi żyjących w rejonach sejsmicznych
W sumie badanie pokazuje, że starannie wytrenowany system oparty na uczeniu maszynowym może wykorzystać pierwsze minuty danych z sejsmometrów i wygenerować szybkie, stosunkowo przejrzyste mapy wpływu trzęsienia. Mapy te nie zastępują szczegółowych inspekcji ani raportów od tłumu, ale mogą wypełnić niebezpieczną wczesną lukę, gdy władze muszą zdecydować, gdzie wysłać karetki, strażaków i inspektorów budowlanych dysponując bardzo ograniczonymi informacjami. Łącząc zaawansowane algorytmy z interpretowalnymi modelami uproszczonymi i podstawowymi znacznikami niepewności, podejście oferuje praktyczny krok w kierunku szybszej, bardziej świadomej reakcji na trzęsienia we Włoszech i może zostać zaadaptowane do innych regionów narażonych na podobne ryzyko sejsmiczne.
Cytowanie: Patelli, L., Cameletti, M., De Rubeis, V. et al. Machine learning for prompt estimation of macroseismic intensity from seismometric data in Italy. Sci Rep 16, 7265 (2026). https://doi.org/10.1038/s41598-026-35740-x
Słowa kluczowe: intensywność trzęsienia ziemi, uczenie maszynowe, random forest, zagrożenie sejsmiczne, Włochy