Clear Sky Science · pl
Sieć fuzji ulepszeń wielofunkcyjnych do semantycznej segmentacji obrazów teledetekcyjnych
Bardziej wyraźne mapy z nieba
Codziennie satelity i drony wykonują szczegółowe zdjęcia naszych miast i pól uprawnych. Przekształcenie tych surowych obrazów w czytelne, piksel po pikselu mapy dróg, dachów, drzew i upraw jest niezbędne do zadań takich jak monitorowanie zdrowia roślin czy planowanie nowych osiedli. W artykule przedstawiono nową metodę poprawiającą dokładność takich map, zwłaszcza w trudnych miejscach, gdzie granice między budynkami, polami i roślinnością się zacierają.
Dlaczego obrazy lotnicze są trudne do analizy
Obrazy teledetekcyjne różnią się od zwykłych fotografii. Są wykonywane z dużej wysokości, często pod ostrym kątem i przy zmiennym oświetleniu. Różne obiekty mogą wyglądać bardzo podobnie z góry: betonowy parking i płaski dach mogą mieć niemal ten sam kolor; różne uprawy mogą tworzyć myląco podobne wzory. Jednocześnie ten sam typ obiektu może wyglądać zupełnie inaczej w zależności od cieni, wilgotności czy ustawień kamery. Tradycyjne programy komputerowe, a nawet wiele współczesnych systemów uczenia głębokiego, ma trudności z utrzymaniem ostrych granic w takich warunkach. Często rozmywają krawędzie między kategoriami lub pomijają drobne detale, takie jak zaparkowane samochody czy wąskie kanały irygacyjne.
Widzieć zarówno ogólny obraz, jak i drobne linie
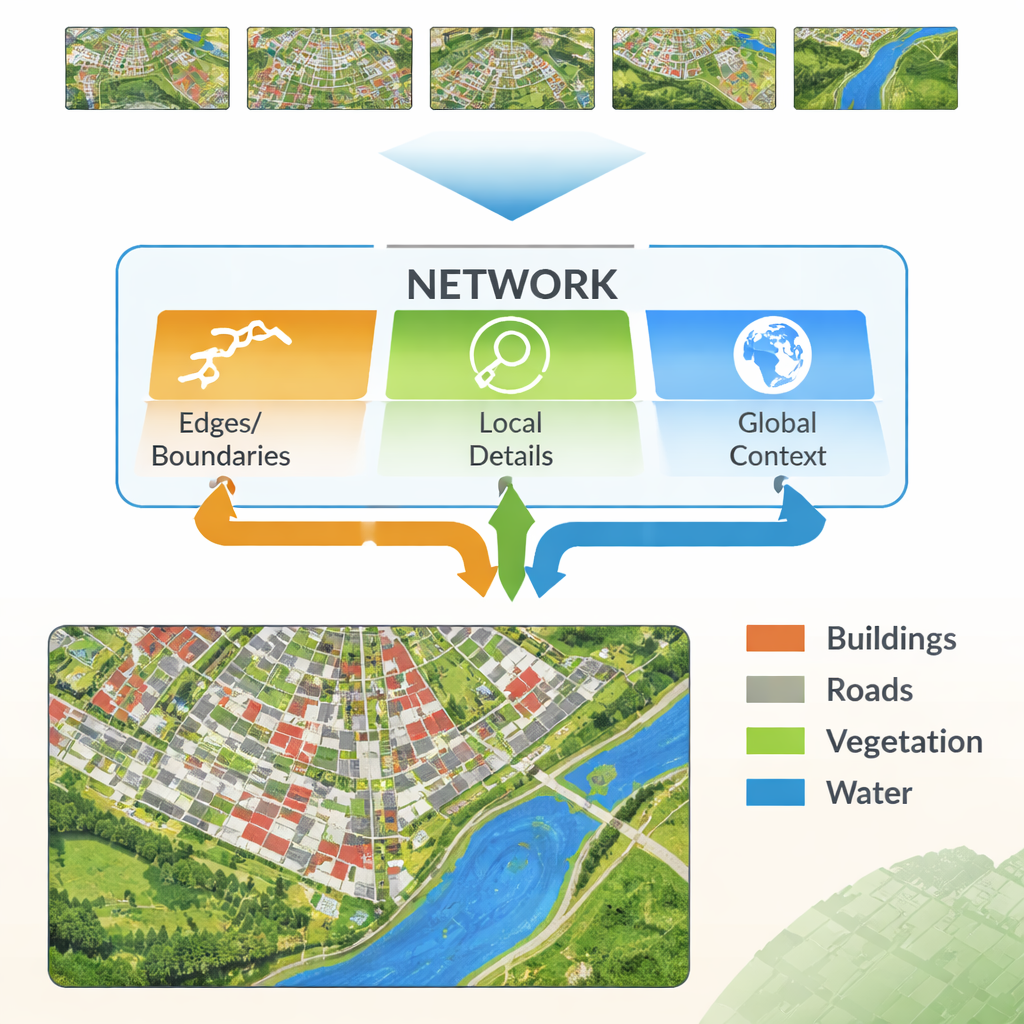
Nowoczesne sieci neuronowe uczą się przez przepuszczanie obrazu przez wiele warstw. Wczesne warstwy wychwytują drobne szczegóły, takie jak linie i tekstury, podczas gdy głębsze warstwy uczą się szerokich wzorców, na przykład „ten obszar to prawdopodobnie zabudowa”. Wyzwaniem jest to, że połączenie tych dwóch rodzajów informacji nie jest trywialne. Niskopoziomowe detale mogą być zaszumione i zbyteczne, a wysokopoziomowe wzorce mogą rozmywać krawędzie, tworząc nieostre kontury. Autorzy proponują nową architekturę, nazwaną Multi‑Feature Enhancement Fusion Network (MFEF‑UNet), zaprojektowaną w celu zrównoważenia lokalnych detali z globalnym zrozumieniem. Robi to, traktując krawędzie, lokalne wzorce i szeroki kontekst jako oddzielne, lecz współdziałające źródła informacji.
Wyróżnianie krawędzi i łączenie cech
Kluczowym pomysłem w nowej metodzie jest wykorzystanie prostych, klasycznych narzędzi wykrywania krawędzi i wplecenie ich w nowoczesny pipeline uczenia głębokiego. Moduł Wzmacniania Krawędzi pobiera najwcześniejsze cechy z sieci i przepuszcza je przez operatory bardzo skuteczne w odnajdywaniu granic — podobnie jak podstawowe programy do edycji obrazów potrafią wykrywać kontury. Uzyskane mapy krawędzi są tworzone na kilku skalach, dzięki czemu sieć widzi zarówno drobne, jak i grube granice. Moduł Fuzji Wielofunkcyjnej łączy następnie trzy strumienie: ewoluującą, wysokopoziomową informację „co to za obszar?”, rekonstrukcję detali z dekodera oraz mapy krawędzi. Zamiast jedynie je łączyć, moduł wykorzystuje mechanizm przypominający uwagę, dzięki czemu cechy semantyczne mogą „pytać” strumienie krawędzi i detali, gdzie naprawdę znajdują się granice i drobne struktury, i odpowiednio dostosować końcową reprezentację.
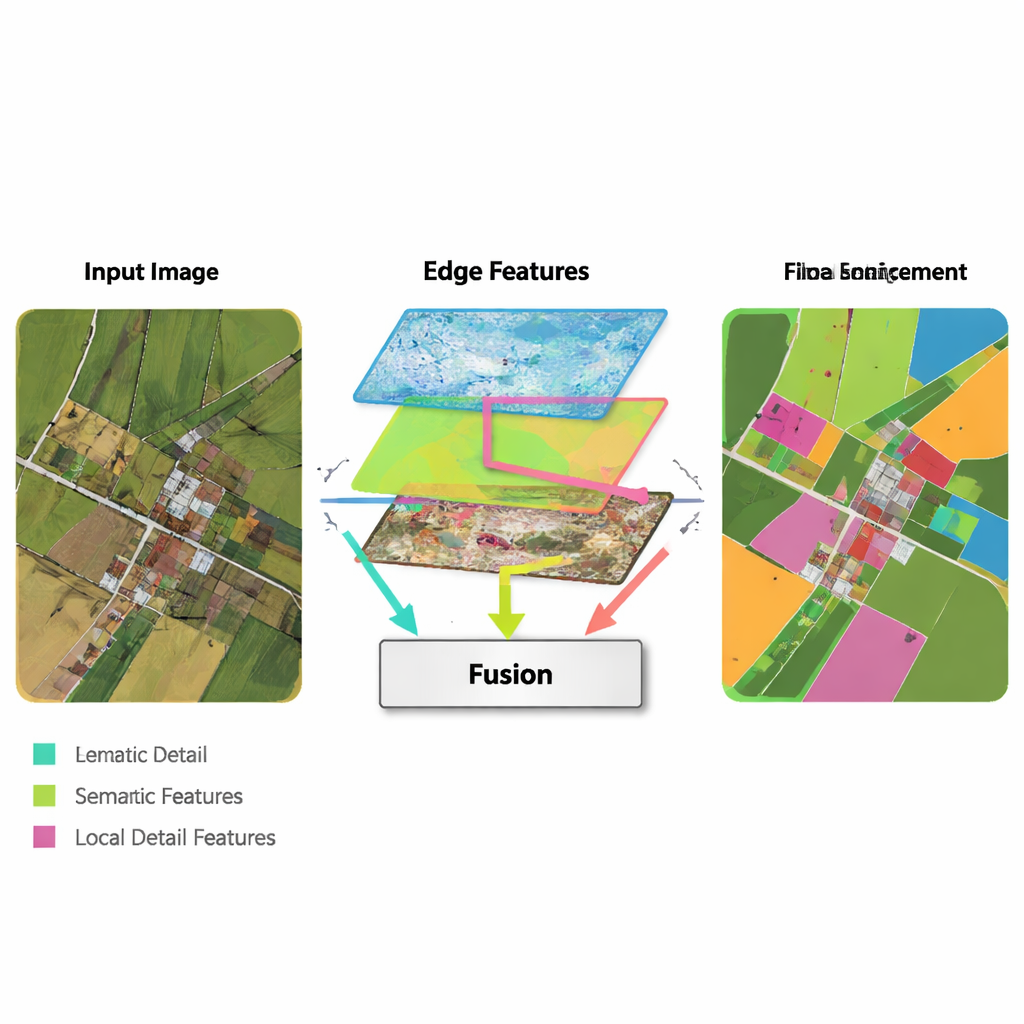
Równoważenie lokalnych detali z kontekstem globalnym
Innym elementem MFEF‑UNet jest Moduł Wzmacniania Cech Lokalnych‑Globalnych. Dla laika można to opisać jako część sieci, która dba o to, by nie zgubić obrazu lasu skupiając się na drzewach — albo miasta, dopracowując każdy budynek. Obraz jest dzielony na poręczne podokna, aby sąsiednie piksele mogły być modelowane razem, zachowując kształty i tekstury. Po tym lokalnym modelowaniu okna są zszywane z powrotem w pełny obraz, a druga faza pozwala na przepływ informacji między odległymi regionami. Ten dwustopniowy proces pomaga modelowi uwzględniać zarówno małe struktury, takie jak samochody i wąskie granice pól, jak i wzory na dużą skalę, takie jak zespoły zabudowy czy rozległe zbiorniki wodne.
Weryfikacja metody na miastach i terenach rolnych
Naukowcy przetestowali swoje podejście na trzech publicznie dostępnych zbiorach danych: dwóch obejmujących europejskie miasteczka i miasta oraz jednym dużym zbiorze obrazów pól rolnych ze Stanów Zjednoczonych. Zbiory te zawierają mieszankę dachów, dróg, roślinności, wód i subtelnych wzorów upraw. We wszystkich trzech benchmarkach MFEF‑UNet konsekwentnie generował dokładniejsze mapy niż szereg wiodących metod, w tym klasyczne sieci splotowe, architektury oparte na Transformerach oraz nowsze modele „stan‑przestrzeń”. Jego przewaga była najbardziej widoczna wokół skomplikowanych konturów budynków, skupisk małych obiektów, takich jak pojazdy, oraz długich, cienkich struktur, takich jak kanały odwodnieniowe czy rzędy upraw — miejsc, gdzie inne metody mają tendencję do fragmentacji lub rozmycia segmentacji.
Co to oznacza w praktyce
W praktyce proponowana sieć przekształca obrazy lotnicze w czystsze, bardziej niezawodne mapy pokrycia terenu. Planiści miejscy mogą z większą pewnością mierzyć obszary zabudowane, inżynierowie lepiej odwzorowywać drogi i dachy, a agronomowie precyzyjniej wyznaczać pola, cieki wodne i strefy stresu roślin. Choć dodanie modułów krawędzi i fuzji wprowadza pewne dodatkowe obciążenie obliczeniowe, ogólny projekt pozostaje stosunkowo wydajny, zapewniając wyraźne zyski w dokładności i odporności. Dla osób niebędących specjalistami kluczowy wniosek jest taki, że przez świadome uwypuklanie krawędzi i staranne łączenie różnych rodzajów wskazówek wizualnych komputery potrafią czytać obrazy satelitarne i dronowe z ostrzejszym „wzrokiem” — przybliżając nas do aktualnych, wysokoprecyzyjnych map świata.
Cytowanie: Zhang, W., Yang, W., Yin, Y. et al. Multi-feature enhancement fusion network for remote sensing image semantic segmentation. Sci Rep 16, 5023 (2026). https://doi.org/10.1038/s41598-026-35723-y
Słowa kluczowe: teledetekcja, segmentacja semantyczna, obrazowanie satelitarne, uczenie głębokie, mapowanie pokrycia terenu