Clear Sky Science · pl
Od danych do decyzji: wykorzystanie wyjaśnialnej sztucznej inteligencji do prognozowania plonów soi w głównych krajach produkujących
Dlaczego lepsze prognozy plonów mają znaczenie
Od cen w supermarketach po handel międzynarodowy — skromna soja odgrywa zaskakująco dużą rolę w życiu codziennym. Rządy, handlowcy i rolnicy muszą znać wielkość zbiorów z wyprzedzeniem liczonym w miesiącach, nim kombajny wyjadą na pola. Dziś potężne narzędzia sztucznej inteligencji potrafią przetwarzać góry danych pogodowych i satelitarnych, by sporządzać takie prognozy — wiele z tych modeli działa jednak jak „czarne skrzynki”, udzielając niewielu wskazówek, dlaczego wydają określone przewidywania. W badaniu tym zbadano nowy rodzaj wyjaśnialnej SI, który nie tylko przewiduje plony soi w głównych krajach producentach, ale też jasno pokazuje, jakie czynniki napędzają te prognozy.
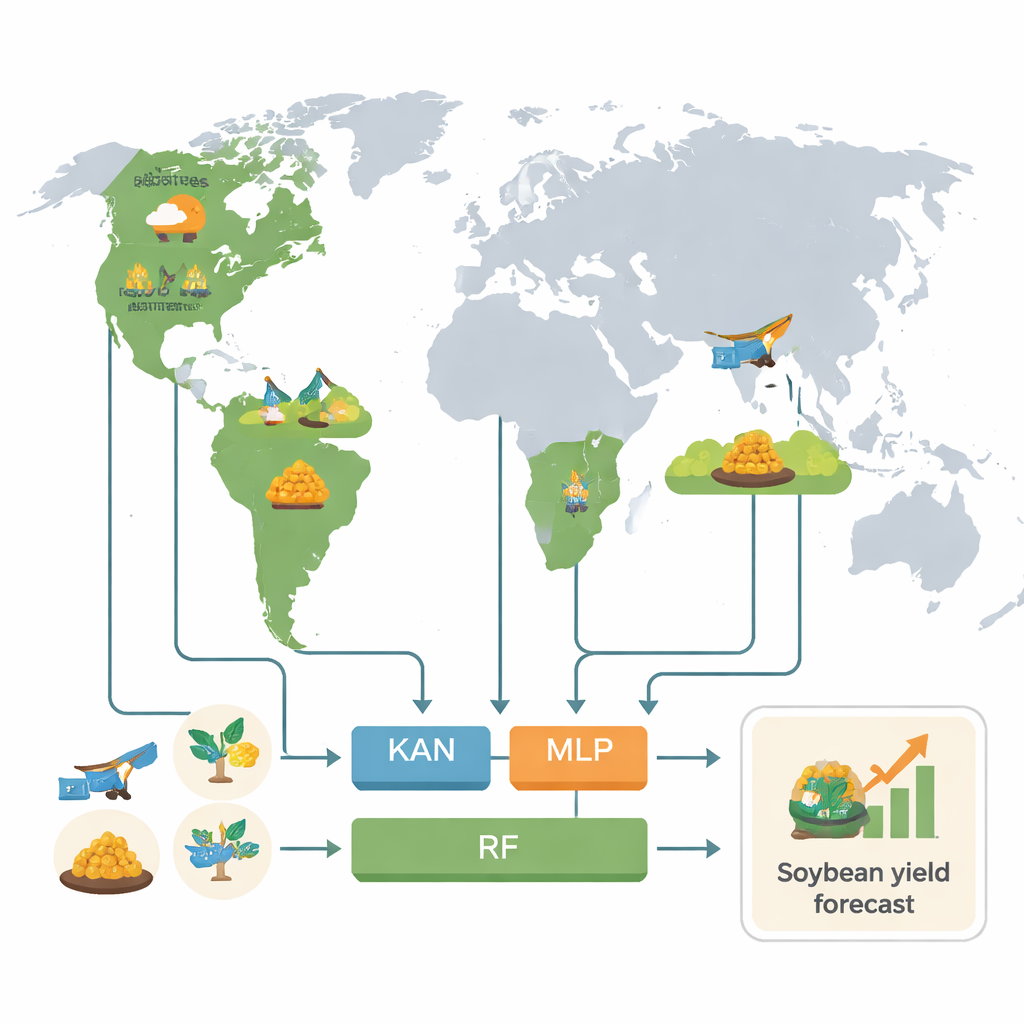
Trzy kraje karmiące świat
Badacze skupili się na trzech krajach dominujących w światowej podaży soi: Stanach Zjednoczonych, Brazylii i Argentynie, które razem produkują ponad 80% światowej soi. Pracowali na szczegółowej skali — hrabstwa w USA oraz odpowiadające im małe regiony w Brazylii i Argentynie — wykorzystując dane z lat 2018–2022. Dla każdego regionu złożyli bogaty obraz warunków wzrostu: szczegółowe zapisy pogodowe, właściwości gleby oraz różne rodzaje danych satelitarnych śledzących wzrost roślin, stan wodny, a nawet słaby sygnał emisji związanej z fotosyntezą, zwany fluorescencją chlorofilu indukowaną światłem (SIF). W sumie wydobyto 154 różnych cech liczbowych opisujących każdy sezon wegetacyjny, zanim dane trafiły do modeli.
Od potoków danych do maszyn uczących się
Aby poradzić sobie z tym napływem informacji, zespół zbudował ustandaryzowany potok przetwarzania. Wyrównał wszystkie zbiory danych w przestrzeni i czasie przy użyciu kalendarzy upraw, wygładził zaszumione sygnały satelitarne i podsumował sezon wegetacyjny za pomocą statystyk, takich jak średnie, wartości skrajne i zmienność. Następnie wytrenowano trzy typy modeli do prognozowania plonów: Random Forest (RF), powszechnie stosowany model uczenia maszynowego; Multilayer Perceptron (MLP), klasyczną sieć neuronową wielowarstwową; oraz Kolmogorov–Arnold Networks (KAN), nowszą architekturę zaprojektowaną od podstaw z myślą o większej interpretowalności. Aby uniknąć zawyżonych wyników, autorzy ostrożnie podzielili dane na bloki przestrzenne, tak by modele testowano na regionach, których nie „widziały” podczas trenowania.
Otwarcie czarnej skrzynki SI
Co wyróżnia tę pracę, to nie tylko dokładność prognoz, lecz także sposób, w jaki modele się wyjaśniają. RF i MLP poddano standardowym narzędziom pokazującym, jak bardzo każda cecha wejściowa wpływa na ich przewidywania. KAN idzie o krok dalej: reprezentuje związki między wejściami a wyjściami jako gładkie, jednowymiarowe krzywe, które można wykreślić i przeanalizować. Pozwala to badaczom dosłownie zobaczyć, jak na przykład zmiana SIF czy wilgotności gleby przesuwa prognozowany plon w górę lub w dół. W przekroju krajów i metod ujawnił się jeden jasny wzorzec — SIF, sygnał satelitarny bezpośrednio związany z fotosyntezą, konsekwentnie plasował się wśród najważniejszych predyktorów plonu soi. Inne kluczowe czynniki różniły się w zależności od regionu: w Stanach Zjednoczonych wyróżniały się sygnały wegetacyjne związane z wodą, podczas gdy w Brazylii i Argentynie silniejszą rolę odgrywały temperatura i wilgotność gleby.
Jak dobrze poradziły sobie modele?
Porównując dokładność modeli, nie wyłoniła się jedna uniwersalna metoda zwyciężająca we wszystkich sytuacjach. W Stanach Zjednoczonych, gdzie plony były względnie stabilne rok do roku, Random Forest wypadł nieco lepiej ogólnie, lecz KAN i MLP były tuż za nim. W Brazylii, z bardziej zmiennymi plonami i większym zbiorem danych, wszystkie trzy modele osiągnęły wysoką dokładność, choć miały pewne trudności z przewidywaniem bardzo wysokich plonów. W Argentynie, gdzie danych było mniej, KAN na ogół przewyższał podstawę opartą na głębokim uczeniu (MLP) i zbliżał się do wyników Random Forest. Wyniki te sugerują, że KAN może dorównać tradycyjnym modelom na trudnych, niewielkich zbiorach rolniczych, oferując przy tym znacznie większą przejrzystość co do sposobu dochodzenia do wniosków.
Co to oznacza dla rolników i bezpieczeństwa żywnościowego
Dla decydentów praktycznych możliwość zaufania modelowi może być równie ważna jak sama dokładność. Badanie pokazuje, że podejścia wyjaśnialnej SI, takie jak KAN, mogą dostarczać konkurencyjne prognozy plonów soi, jednocześnie jasno ujawniając, które sygnały środowiskowe i uprawne są najistotniejsze. Taka przejrzystość pomaga naukowcom diagnozować błędy, włączać ekspercką wiedzę agronomiczną i dostosowywać modele do nowych regionów lub zmieniającego się klimatu. W dłuższej perspektywie takie narzędzia mogłyby zostać wplecione w krajowe systemy monitorowania upraw, dając rolnikom, planistom i rynkom wcześniejsze i bardziej wiarygodne ostrzeżenia o nieurodzaju lub rekordowych zbiorach — wspierając tym samym bardziej odporne i zrównoważone systemy żywnościowe.
Cytowanie: Wang, X., He, Y., Chen, H. et al. From data to decisions: the use of explainable AI to forecast soybean yield in major producing countries. Sci Rep 16, 5103 (2026). https://doi.org/10.1038/s41598-026-35716-x
Słowa kluczowe: prognozowanie plonów soi, wyjaśnialna sztuczna inteligencja, teledetekcja, modelowanie rolnicze, bezpieczeństwo żywnościowe