Clear Sky Science · pl
Śledzenie międzypodobne z dwutorową architekturą wspomaganą transformatorem, z regresją świadomą pewności i adaptacyjną aktualizacją szablonu
Nauka maszyn śledzenia jednego obiektu w zatłoczonej scenie
Od samochodów autonomicznych po kamery domowego monitoringu i drony — wiele współczesnych urządzeń musi podążać za jednym poruszającym się obiektem w zmiennym, zatłoczonym świecie. Zadanie to, zwane wizualnym śledzeniem obiektów, dla ludzi wydaje się proste, ale dla maszyn bywa zaskakująco trudne: osoby przechodzą przed kamerą, zmienia się oświetlenie, obiekt oddala się lub jest chwilowo zasłonięty. W artykule wprowadzono TSDTrack, nowy system śledzenia, który wykorzystuje najnowsze osiągnięcia w głębokim uczeniu i transformatorach, by bardziej niezawodnie utrzymywać cel w warunkach zbliżonych do rzeczywistych.
Dlaczego śledzenie jednego obiektu jest tak trudne
Tracker zwykle widzi obiekt wyraźnie tylko w pierwszej klatce wideo, a potem musi go odnajdywać w miarę zmiany sceny. Tradycyjne metody opierały się albo na ręcznie konstruowanych cechach obrazu, albo na sieci neuronowej porównującej pierwszą klatkę (tzw. „szablon”) z każdą kolejną. Te starsze systemy miały trzy poważne słabości. Po pierwsze, często utrzymywały pierwotny szablon niezmieniony, więc gdy obiekt się obrócił, częściowo zasłonił lub zmienił rozmiar, tracker miał problemy. Po drugie, skupiały się zwykle na jednym poziomie szczegółowości obrazu, pomijając kombinację drobnych krawędzi i szerszego kontekstu, która pomaga ludziom rozpoznawać obiekty. Po trzecie, nie wiedziały, kiedy powinny wątpić — generowały prostokąt wokół rzekomego obiektu bez jasnego wskaźnika wiarygodności tej prognozy, co prowadziło do dryfowania na tło.
Łączenie kontekstu globalnego z drobnymi detalami
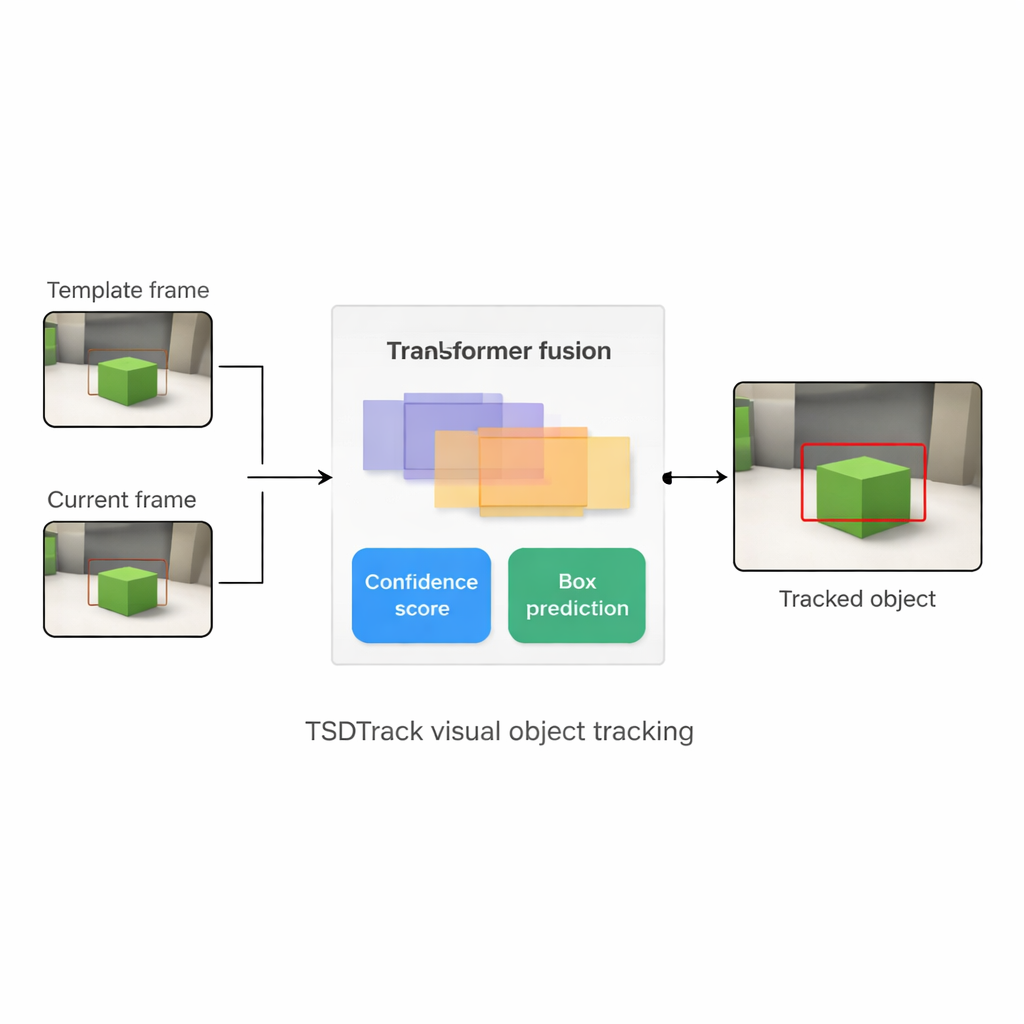
TSDTrack rozwiązuje te problemy, łącząc klasyczną konfigurację śledzenia „syjamskiego” z transformatorem — tym samym modelem opartym na uwadze, który zrewolucjonizował zadania językowe i wizualne. System używa głębokiej sieci do ekstrakcji cech z dwóch wejść: małego fragmentu określającego cel oraz większego fragmentu obejmującego aktualny obszar poszukiwań. Zamiast polegać na jednej skali cech, czerpie informacje z wielu warstw sieci, które reprezentują krawędzie, kształty i wzorce na poziomie obiektów. Moduł fuzji oparty na transformatorze uczy się, jak mieszać te warstwy, tak by tracker rozumiał zarówno pozycję elementów na obrazie, jak i ich relacje z szerszą sceną. Pomaga to odróżnić cel od podobnych obiektów i zagracenia, nawet gdy widok jest zaszumiony lub częściowo zasłonięty.
Świadomość własnej pewności
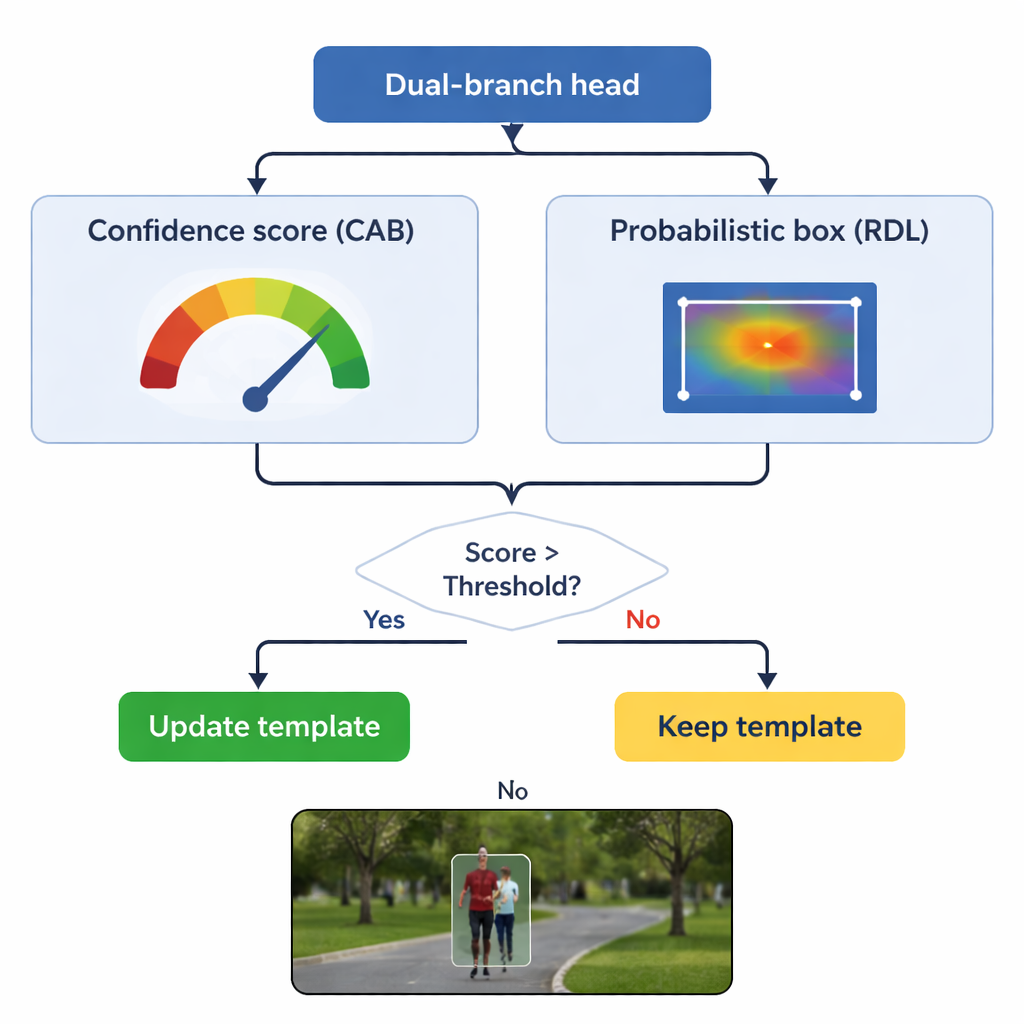
Rdzeniem TSDTrack jest dwutorowa głowica predykcyjna, która dzieli zadanie na dwa powiązane pytania: „Gdzie jest obiekt?” i „Na ile można ufać tej odpowiedzi?”. Jeden tor szacuje współczynnik pewności, który odzwierciedla nie tylko podobieństwo do szablonu, lecz także, jak dobrze przewidywany prostokąt pokrywa się z prawdopodobnymi regionami obiektu. Drugi tor traktuje współrzędne prostokąta nie jako pojedyncze zgadnięcie, lecz jako rozkład prawdopodobieństwa pośród wielu możliwych pozycji, pozwalając modelowi reprezentować niepewność. Gdy obraz jest wyraźny, rozkład staje się ostry, a prostokąt precyzyjny; gdy obiekt jest rozmazany lub częściowo ukryty, rozkład się rozszerza. Takie probabilistyczne podejście daje gładsze, bardziej stabilne umieszczanie ramki w porównaniu ze starszymi trackerami, które dawały sztywną, pojedynczą prognozę.
Aktualizacja pamięci bez zapominania oryginału
Jednym z głównych zagrożeń w śledzeniu jest „dryf szablonu”: jeśli model ciągle aktualizuje wyobrażenie o obiekcie na podstawie złych klatek, może stopniowo nauczyć się tła. TSDTrack przeciwdziała temu, pozwalając gałęzi pewności pełnić funkcję strażnika. System aktualizuje wewnętrzny szablon tylko wtedy, gdy współczynnik pewności przekracza ustalony próg, a nawet wtedy miesza nowe informacje delikatnie z widokiem oryginalnym zamiast go całkowicie zastępować. Tak selektywna aktualizacja pozwala trackerowi dopasować się do rzeczywistych zmian, np. gdy osoba się odwraca lub samochód się obraca, bez bycia zwiedzionym przez chwilowe zasłonięcia czy rozproszenia. Oryginalny szablon jest też przechowywany jako stabilny punkt odniesienia na wypadek, gdyby późniejsze aktualizacje okazały się mylące.
Co wyniki oznaczają w praktyce
Autorzy przetestowali TSDTrack na kilku powszechnie używanych zestawach benchmarkowych do śledzenia, obejmujących długie wideo, szybki ruch, nagrania z powietrza z dronów i sceny o dużym zagraceniu. W tych testach nowa metoda konsekwentnie przewyższała wiele wiodących trackerów zarówno pod względem dokładności (jak blisko ramka jest prawdziwego obiektu), jak i odporności (jak rzadko traci obiekt całkowicie), a jednocześnie działała wystarczająco szybko, by być użyteczna w czasie rzeczywistym na nowoczesnym sprzęcie. Dla osoby nietechnicznej wniosek jest taki, że TSDTrack potrafi bardziej niezawodnie utrzymać wybrany cel w trudnych, rzeczywistych warunkach kamer. Poprzez łączenie wieloskalowego rozumowania z transformatorem, samooceny pewności i ostrożnej aktualizacji szablonu, oferuje bardziej godny zaufania element budulcowy dla zastosowań takich jak autonomiczne prowadzenie, inteligentny nadzór czy robotyka.
Cytowanie: Sachin Sakthi, K.S., Jeong, J.H. & Choi, W.Y. Transformer-augmented dual-branch siamese tracker with confidence-aware regression and adaptive template updating. Sci Rep 16, 5170 (2026). https://doi.org/10.1038/s41598-026-35692-2
Słowa kluczowe: śledzenie obiektów w obrazie, śledzenie oparte na transformatorach, sieci syjamskie, widzenie komputerowe, systemy autonomiczne