Clear Sky Science · pl
Satelitarne podejście uczenia maszynowego do szacowania wysokorozdzielczej dziennej średniej temperatury powietrza w megamiasto w Brazylii
Dlaczego miejski upał nie jest jednakowy wszędzie
W upalny dzień w dużym mieście temperatura, którą odczuwasz na ulicy obsadzonej drzewami, może znacznie różnić się od tej doświadczanej na betonowym placu kilka przecznic dalej. Większość badań zdrowotnych i klimatycznych nadal traktuje jednak całe miasto tak, jakby miało jedną temperaturę. Ten artykuł pokazuje, jak naukowcy wykorzystali satelity, modele pogodowe i uczenie maszynowe do mapowania codziennych temperatur w São Paulo w Brazylii z dużą szczegółowością — pomagając ustalić, kto naprawdę jest narażony na niebezpieczne upały i gdzie działania chłodzące są najbardziej potrzebne.
Pomiary temperatury miasta w wysokiej rozdzielczości
Tradycyjne zapisy temperatury opierają się na ograniczonej liczbie stacji meteorologicznych, często skupionych wokół lotnisk lub w zamożniejszych dzielnicach. Utrudnia to obserwację rozkładu ciepła po prawdziwych sąsiedztwach, zwłaszcza w dużych miastach i w krajach o niskich i średnich dochodach, gdzie sieci monitoringu są rzadkie. Badacze skupili się na São Paulo, rozległym i bardzo zróżnicowanym megamiasto liczącym ponad 22 miliony osób. Ich celem było oszacowanie dziennej średniej temperatury powietrza dla każdego pola 500 na 500 metrów na obszarze metropolitalnym przez pięć lat, od 2015 do 2019 roku, tworząc jedne z najbardziej szczegółowych miejskich zestawów danych temperaturowych dostępnych w Ameryce Południowej.
Łączenie satelitów, modeli pogodowych i czujników naziemnych
Aby zbudować ten obraz o wysokiej rozdzielczości, zespół połączył kilka typów ogólnodostępnych danych. Zebrali pomiary z 48 stacji naziemnych, które dają najbardziej bezpośrednie odczyty temperatury powietrza, ale tylko w konkretnych punktach. Następnie wykorzystali obserwacje satelitarne temperatury powierzchni ziemi, kąta padania słońca oraz odbijności gruntu, wraz z informacjami o wilgotności, wietrze i ciśnieniu z globalnego produktu „reanalizy” pogodowej, który rekonstruuje godzinową pogodę na grubej siatce. Składniki te zostały próbkowane ponownie, aby dopasować je do siatki 500 metrów, i oczyszczone w celu wypełnienia luk spowodowanych chmurami lub brakującymi przelotami satelitarnymi. W sumie przetestowali 23 możliwe zmienne predykcyjne, które mogły pomóc wyjaśnić, jak ciepło zmienia się w przestrzeni i czasie.
Uczenie maszyny do odczytywania ciepła
Zamiast stosować prostą liniową zależność, naukowcy sięgnęli po Random Forest, popularną metodę uczenia maszynowego, która buduje wiele drzew decyzyjnych i uśrednia ich wyniki. Podejście to jest dobrze dopasowane do ujawniania złożonych, nieliniowych zależności, takich jak to, jak temperatura reaguje różnie na ciepło powierzchni, wilgotność i wiatr w różnych częściach miasta lub o różnych porach roku. Aby uniknąć przeuczenia na specyfice kilku stacji, zastosowali krokowy proces selekcji cech, który zachowuje tylko te zmienne, które rzeczywiście poprawiają predykcję, i zweryfikowali model na dwa sposoby: przez wielokrotne pomijanie grup stacji podczas treningu oraz przez odłożenie pięciu całych stacji jako surowy test zewnętrzny, sprawdzający, jak model sprawuje się w nowych lokalizacjach.
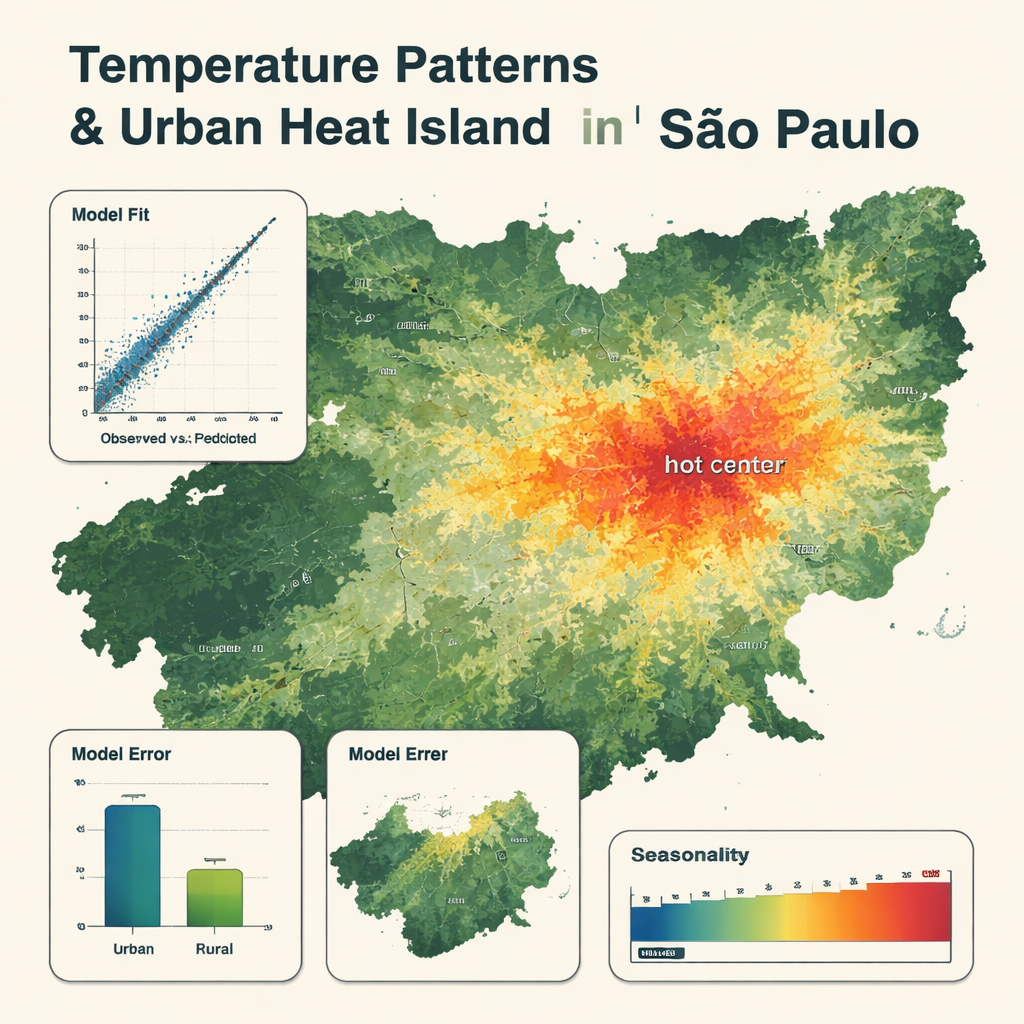
Co ujawniają szczegółowe mapy
Model końcowy używał zaledwie ośmiu kluczowych zmiennych, na czele z temperaturą powietrza z globalnego produktu pogodowego, a także temperaturą powierzchni z satelity i wilgotnością, które odgrywały ważne role. Model bardzo wiernie odtwarzał odczyty stacji, ze średnim błędem około 0,8 °C i bardzo wysoką zgodnością między obserwowanymi a przewidywanymi temperaturami. Mapy pokazują wyraźne wzorce: chłodniejsze strefy nad lasami, górami i dużymi zbiornikami wodnymi oraz gorętsze strefy w zwartej, zabudowanej śródmieściu, gdzie temperatury mogą być do 5 °C wyższe niż w pobliskich obszarach wiejskich. Model uchwycił sezonowe wahania, z najcieplejszym okresem od grudnia do marca i najchłodniejszym od maja do sierpnia. Był nieco mniej dokładny na terenach wiejskich i miał tendencję do wygładzania najskrajniejszych gorących i zimnych dni, ale nadal przewyższał tradycyjny model wieloliniowy korzystający z tych samych danych wejściowych.
Dlaczego te mapy mają znaczenie dla zdrowia ludzi
Przekształcając rozproszone pomiary i satelitarne migawki w codzienne, uliczne oszacowania temperatury, ta praca oferuje potężne nowe narzędzie dla zdrowia publicznego i planowania miejskiego w São Paulo i poza nim. Badacze mogą teraz analizować, jak upał wpływa na różne dzielnice, w tym osiedla nieformalne, które często nie występują w oficjalnych rejestrach, i identyfikować miejsca, gdzie mieszkańcy są najbardziej narażeni podczas fal upałów. Ponieważ metoda opiera się w całości na otwartych danych i standardowym oprogramowaniu, można ją dostosować do innych miast, które mają kilka stacji naziemnych i podobne pokrycie satelitarne. Mówiąc prosto, badanie pokazuje, że teraz potrafimy „widzieć” miejski upał z dużo większą precyzją, co stanowi niezbędną podstawę dla sprawiedliwszej, bardziej ukierunkowanej adaptacji klimatycznej i ochrony najbardziej narażonych społeczności.
Cytowanie: Roca-Barceló, A., Schneider, R., Pirani, M. et al. A satellite based machine learning approach for estimating high resolution daily average air temperature in a megacity in Brazil. Sci Rep 16, 7459 (2026). https://doi.org/10.1038/s41598-026-35689-x
Słowa kluczowe: miejski upał, uczenie maszynowe, dane satelitarne, São Paulo, temperatura powietrza