Clear Sky Science · pl
Identyfikacja ataków phishingowych w czasie rzeczywistym za pomocą rozszerzeń przeglądarki wzmocnionych uczeniem maszynowym
Dlaczego fałszywe witryny dotyczą nas wszystkich
Codziennie ludzie otrzymują wiadomości wyglądające, jakby pochodziły z ich banku, firmy kurierskiej czy miejsca pracy — jednak niektóre z nich to starannie przygotowane pułapki. Oszustwa phishingowe wykorzystują fałszywie podobne e‑maile i strony internetowe, by wyłudzać hasła, numery kart kredytowych i inne dane osobowe. W miarę jak przestępcy stają się coraz lepsi w naśladowaniu prawdziwych serwisów, proste listy blokad i intuicja nie wystarczają. W artykule opisano nowe rozszerzenie przeglądarki, które dyskretnie monitoruje odwiedzane strony i wykorzystuje uczenie maszynowe do oznaczania niebezpiecznych witryn w czasie rzeczywistym, dążąc do zapewnienia zwykłym użytkownikom silnej ochrony bez konieczności zostawania ekspertami od bezpieczeństwa.
Jak współczesne ataki phishingowe nas oszukują
Phishing rozrósł się do jednego z najpowszechniejszych przestępstw online na świecie, odpowiadając za znaczną część zgłaszanych incydentów cybernetycznych i strat finansowych. Atakujący wysyłają przekonujące e‑maile wzywające do szybkiego działania — „zweryfikuj konto”, „zaktualizuj płatność”, „śledź przesyłkę” — i kierują ofiary na fałszywe witryny przypominające strony bankowe, sklepy czy usługi w chmurze. Wiele z tych stron korzysta dziś z ważnych certyfikatów HTTPS i dopracowanych projektów, więc stare ostrzeżenia typu „brak kłódki” czy „brzydka strona” przestały działać. Badania i raporty kryminalne pokazują, że osoby w wieku 20–40 lat są często celem ataków, a zespoły bezpieczeństwa nadal obawiają się oszustw e‑mailowych, które omijają filtry.
Inteligentniejsze spojrzenie na adresy internetowe i wygląd strony
Naukowcy twierdzą, że najbezpieczniejszym miejscem do zatrzymania phishingu jest sama przeglądarka, w chwili gdy strona się ładuje. Ich rozszerzenie dla Google Chrome (i zgodnych przeglądarek) analizuje dwa główne wskazówki: sam adres URL oraz wygląd strony. Z każdej witryny zbiera „leksykalne” cechy URL‑a, takie jak długość, nietypowe symbole czy podejrzane subdomeny; „strukturalne” i domenowe informacje, takie jak ruch czy dane rejestracyjne; oraz wskazówki „wizualne” — układy bloków, kolory i logotypy. Bezgłowa przeglądarka renderuje każdą stronę w kontrolowany sposób, dzieli ją na prostokątne regiony i rejestruje, gdzie pojawiają się formularze, logotypy i paski nawigacyjne. Następnie porównuje ten wizualny odcisk palca z odciskami zaufanych serwisów, szukając niemalże identycznych kopii, które mogą być oszustwem.
Używanie cyfrowych „wilków” do wyboru najbardziej trafnych cech
Ponieważ system gromadzi dziesiątki pomiarów z każdej witryny, musi zdecydować, które z nich rzeczywiście pomagają odróżnić oszustwa od bezpiecznych stron. W tym celu autorzy zapożyczają algorytm inspirowany sposobem polowania wilków szarych. W „Grey Wolf Optimizer” wiele kandydatów na zestawy cech konkuruje ze sobą, a algorytm stopniowo zbiega do zwartego podzbioru, który daje najlepszą równowagę między wykrywaniem phishingu a unikaniem fałszywych alarmów. Wybrane cechy trafiają następnie do trzech modeli uczenia maszynowego — maszyny wektorów nośnych (SVM), drzewa decyzyjnego i w szczególności Random Forest, który łączy wiele drzew decyzyjnych w silny zespół. Trening wykorzystuje 80 000 stron pobranych z publicznych zbiorów, takich jak PhishTank i archiwa akademickie, z dodatkowymi technikami radzenia sobie z niezrównoważeniem między witrynami legalnymi a złośliwymi.
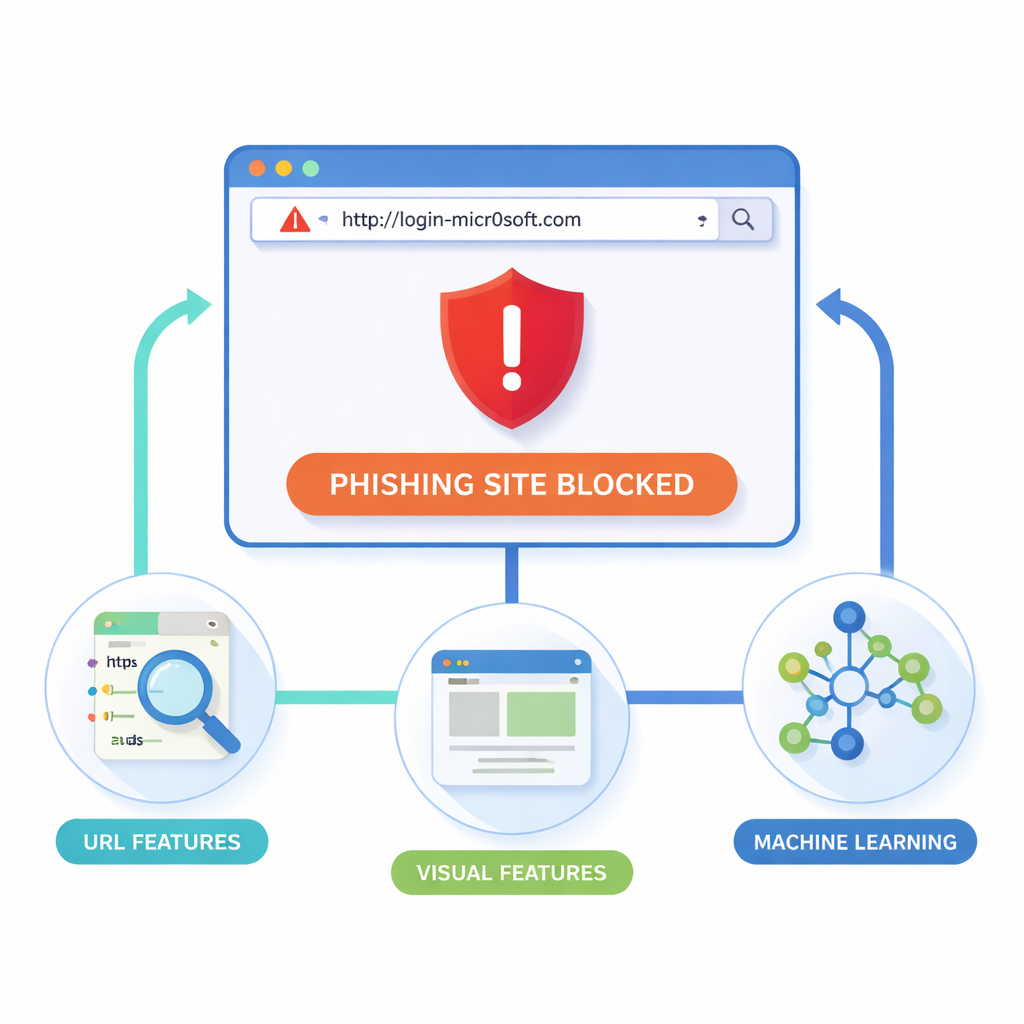
Przekształcanie modeli laboratoryjnych w użyteczne narzędzie przeglądarki
Optymalny model Random Forest osiągnął około 98–99% dokładności oraz współczynnik korelacji Matthewsa bliski 0,96 — surową miarę uwzględniającą zarówno przeoczone ataki, jak i fałszywe alarmy. W testach na żywo z rozszerzeniem do Chrome system skanował każdy URL w około 200 milisekund, na tyle szybko, że użytkownicy nie odczuwali opóźnień. Gdy wykryto ryzykowną stronę, dodatek wyświetlał wyraźne ostrzeżenie i pozwalał użytkownikom wrócić lub kontynuować na własne ryzyko. W porównaniu z popularnymi narzędziami, takimi jak Google Safe Browsing, oraz istniejącymi rozszerzeniami anty‑phishingowymi, nowy system wykazał wyższe wskaźniki wykrywania, mniej błędnych ostrzeżeń i zdolność wykrywania mylących adresów — nawet gdy były skrócone, lekko zniekształcone lub nowo utworzone.
Co to oznacza dla codziennego przeglądania
Dla osób niebędących specjalistami kluczowy wniosek jest taki, że obrona przed phishingiem nie musi już opierać się wyłącznie na domysłach czy ręcznych czarnych listach. Łącząc sposób zapisu linku z wyglądem strony i automatycznie wybierając najbardziej informatywne sygnały, proponowane rozszerzenie może rozpoznawać wiele oszustw już przy pierwszym pojawieniu się, a nie dopiero po zgłoszeniu. Autorzy przyznają, że atakujący będą nadal ewoluować, a modele trzeba będzie ponownie trenować i rozszerzać na telefony oraz inne przeglądarki. Mimo to ich praca pokazuje, że inteligentne, respektujące prywatność rozszerzenie działające na własnym urządzeniu może pełnić rolę niewyczerpanego drugiego zestawu oczu — dyskretnie sprawdzając każdą odwiedzaną stronę i interweniując, gdy coś wyda się nie w porządku, długo zanim pochopne kliknięcie przerodzi się w kosztowny błąd.
Cytowanie: Dandotiya, M., Goyal, N., Khunteta, A. et al. Real time identification of phishing attacks through machine learning enhanced browser extensions. Sci Rep 16, 6612 (2026). https://doi.org/10.1038/s41598-026-35655-7
Słowa kluczowe: wykrywanie phishingu, rozszerzenie przeglądarki, uczenie maszynowe, cyberbezpieczeństwo, fałszywe witryny