Clear Sky Science · pl
Wizualne, sterowane wskazówkami generowanie kolorowych obrazów AI przy użyciu ulepszonego GAN
Dlaczego mądrzejsze maszyny artystyczne mają znaczenie
Narzędzia cyfrowe potrafią dziś namalować portrety, pejzaże i sceny abstrakcyjne w kilka sekund, jednak wiele z tych prac nadal wygląda nie do końca naturalnie — kolory się gryzą, faktury wydają się płaskie, a „styl” nie do końca odpowiada temu, co ludzie sobie wyobrażają. W artykule przedstawiono nowy sposób uczenia komputerów tworzenia kolorowych dzieł, które są bogatsze, bardziej spójne i bliższe prawdziwym obrazom, przy jednoczesnym umożliwieniu użytkownikom wpływania na rezultat za pomocą prostych wizualnych wskazówek, takich jak szkice czy wybór kolorów. Celem jest uczynienie AI bardziej niezawodnym partnerem twórczym dla artystów, projektantów i zwykłych użytkowników, którzy chcą spersonalizowanej sztuki bez potrzeby wieloletniego szkolenia.
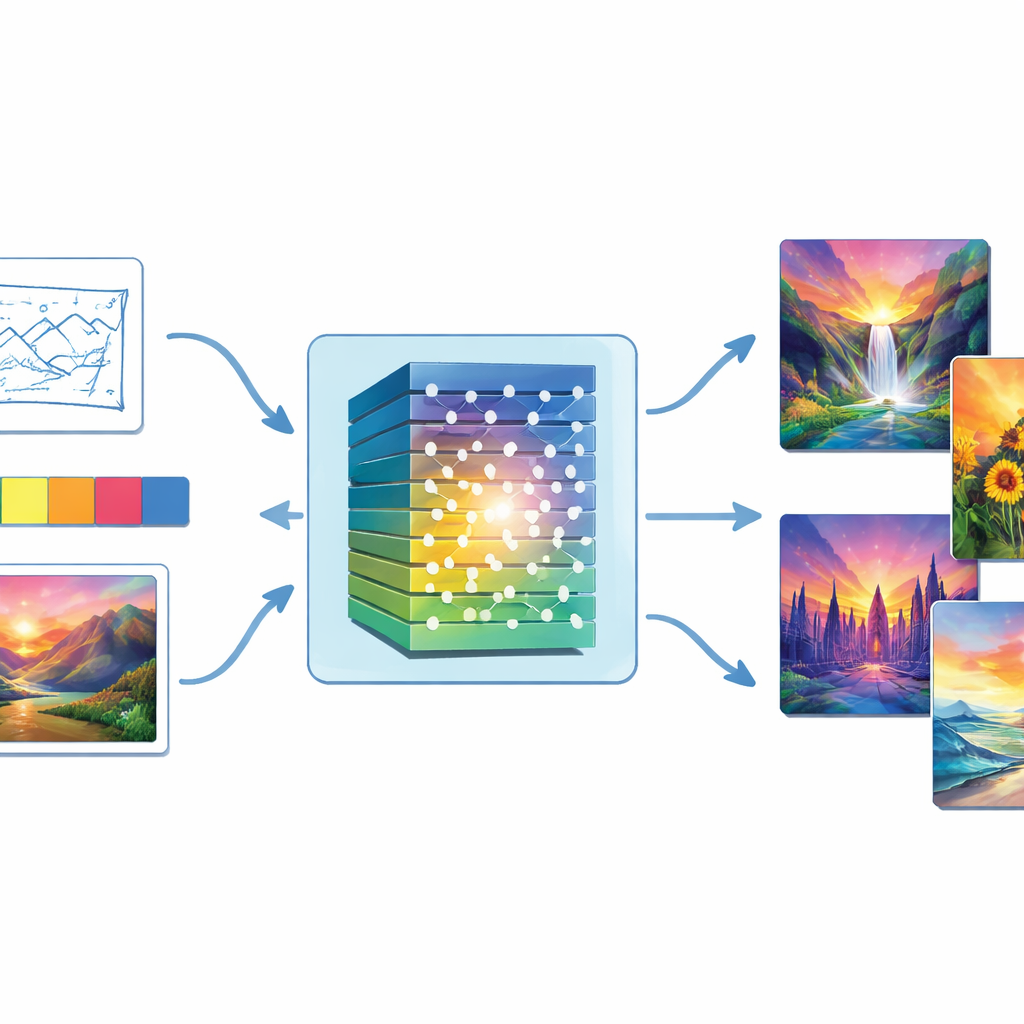
Od losowego szumu do skończonych obrazów
W centrum badania znajduje się typ AI zwany Generative Adversarial Network, czyli GAN. GAN składa się z dwóch przeciwnych elementów: „generatora”, który próbuje tworzyć przekonujące obrazy z losowego szumu, oraz „dyskryminatora”, który ocenia, czy obraz wygląda na prawdziwy czy fałszywy. Poprzez wielokrotne rundy treningu generator staje się lepszy w oszukiwaniu dyskryminatora, a obrazy stopniowo stają się bardziej realistyczne. Autorzy wzmacniają tę podstawową ideę, wstawiając głęboką strukturę przetwarzania obrazu — zwaną splotową siecią neuronową — zarówno do generatora, jak i dyskryminatora, dzięki czemu system lepiej uchwyci wszystko, od ogólnych kształtów po drobne, pociągnięciom pędzla podobne detale.
Nauczanie systemu, gdzie patrzeć
Chociaż standardowe GAN-y potrafią generować ostre obrazy, często gubią szerszy kontekst: mogą przeceniać drobne detale i tracić globalną strukturę albo nie utrzymywać spójnego stylu artystycznego. Aby temu zaradzić, zespół dodał adaptacyjny mechanizm uwagi. Moduł ten analizuje wewnętrzne mapy cech generatora i uczy się podczas treningu, które regiony obrazu są w danym momencie najważniejsze. Następnie wzmacnia te kluczowe obszary — takie jak krawędzie, tekstury i obiekty będące punktem centralnym — jednocześnie łagodząc mniej istotne strefy tła. Specjalne miary straty monitorują, jak dobrze wygenerowany obraz dopasowuje się do stylu i tekstury obrazu docelowego, zmuszając model do równoważenia rozpoznawalnej zawartości z spójnym artystycznym wyglądem.
Sterowanie maszyną za pomocą wskazówek wizualnych
W przeciwieństwie do systemów opartych jedynie na tekście, to podejście pozwala użytkownikom kierować dziełem poprzez bezpośrednie wskazówki wizualne. Użytkownicy mogą dostarczyć szkic określający kompozycję, paletę kolorów nadającą nastrój, obraz referencyjny do naśladowania lub proste tagi sceny. Te dane trafiają do generatora obok losowego szumu. Model oblicza właściwości kolorów, takie jak odcień, nasycenie i jasność, i dopasowuje swoje wyjście tak, aby finalny obraz respektował zarówno intencje kolorystyczne użytkownika, jak i styl referencji. Cel dopasowania kolorów dodatkowo wzmacnia powiązanie między tym, co wskazuje użytkownik, a tym, co system produkuje — dzięki temu chłodny niebieski pejzaż morski nie zamienia się niespodziewanie w ciepły zachód słońca, na przykład.
Nauka poprzez próbę i błąd
System idzie o krok dalej, wykorzystując głębokie uczenie ze wzmocnieniem, technikę inspirowaną uczeniem przez próbę i błąd. Tutaj oddzielny moduł decyzyjny traktuje różnicę między bieżącym wyjściem a docelowym wskazaniem jako swój „stan” i proponuje drobne poprawki elementów, takich jak siła szkicu czy wagi palety, jako swoje „akcje”. Po każdej zmianie system mierzy, o ile poprawiły się istotne wskaźniki jakości obrazu — takie jak szczytowy stosunek sygnału do szumu, strukturalne podobieństwo i strata stylu — i wykorzystuje to jako sygnał nagrody. Z czasem ta pętla uczy się polityki, która automatycznie dopracowuje wskazówki, kierując generator ku obrazom zarówno wiernym wizualnie, jak i spójnych artystycznie.
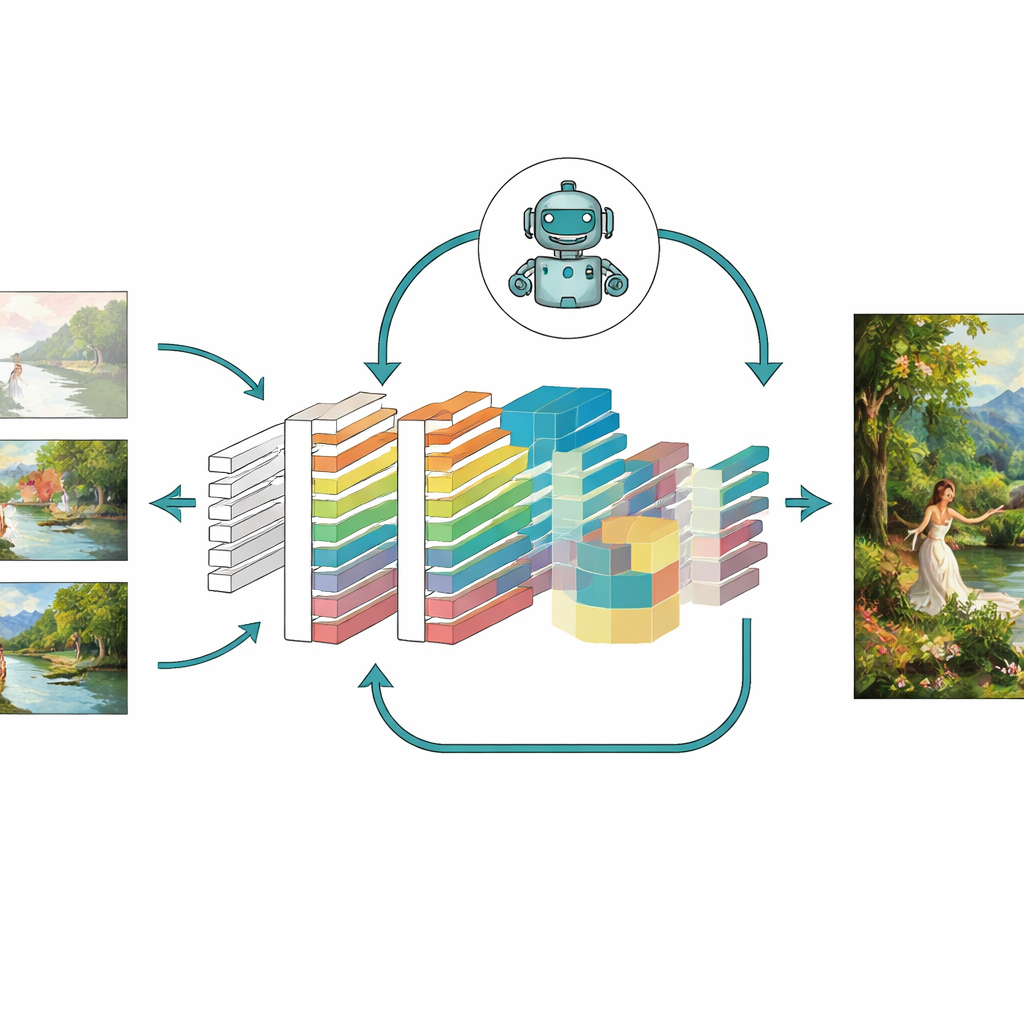
Próba modelu w praktyce
Aby ocenić, czy te pomysły rzeczywiście pomagają, autorzy przetestowali swój ulepszony model — nazwany CNN-GAN — na dużej kolekcji obrazów z Uniwersytetu Oksfordzkiego oraz na niestandardowym zbiorze ponad 5 000 kolorowych dzieł w stylach takich jak portrety, pejzaże i sceny abstrakcyjne. Porównali wyniki z kilkoma znanymi systemami, w tym klasycznymi wariantami GAN, autoenkoderami, a nawet nowoczesnymi generatorami opartymi na dyfuzji. W wielu miarach nowy model wygenerował ostrzejsze obrazy z mniejszą ilością artefaktów, lepszym dopasowaniem strukturalnym do prawdziwych dzieł, mniejszą odległością percepcyjną od obrazów docelowych oraz większą różnorodnością typów scen, które potrafił wygenerować. Badania ablacjne, polegające na usuwaniu kolejnych modułów, wykazały, że uwaga, uczenie ze wzmocnieniem i skomponowany projekt funkcji straty każdy z osobna wnosiły istotne ulepszenia, a razem dawały najsilniejsze rezultaty.
Co to oznacza dla przyszłych narzędzi twórczych
Mówiąc prosto, artykuł opisuje maszynę malarską, która nie tylko uczy się na podstawie tysięcy dzieł, lecz także zwraca szczególną uwagę na istotne obszary, słucha wizualnych wskazówek użytkowników i stopniowo uczy się, jak dostosowywać te wskazówki dla lepszych efektów. Efektem jest AI, które potrafi generować obrazy wysokiej jakości, stylistycznie spójne i bardziej niezawodne niż wcześniejsze metody, pozostawiając jednocześnie pole do kierunku ze strony człowieka. Choć system nadal ma trudności z niezwykle złożonymi fakturami i opiera się na dużych zbiorach treningowych, autorzy sugerują przyszłe rozszerzenia — takie jak moduły wieloskalowe i lżejsze sieci — by uczynić go bardziej wydajnym i powszechnie użytecznym. Razem te postępy wskazują drogę ku narzędziom AI do tworzenia sztuki, które są szybsze, wierniejsze intencjom użytkownika i lepiej oddają subtelny charakter ręcznie wykonanych obrazów.
Cytowanie: Wu, Z. Visual guided AI color art image generation using enhanced GAN. Sci Rep 16, 9345 (2026). https://doi.org/10.1038/s41598-026-35625-z
Słowa kluczowe: generowanie sztuki AI, transfer stylu obrazu, generatywne sieci antagonistyczne, sztuczna kreatywność, neuronalna synteza obrazu