Kiedy rządy, naukowcy czy ankieterzy próbują dowiedzieć się czegoś o całej populacji — na przykład o średnich dochodach, plonach czy poziomach zanieczyszczeń — rzadko udaje się przebadać wszystkich. Zamiast tego losuje się próbę i ekstrapoluje wyniki. To działa dobrze tylko wtedy, gdy dane zachowują się przewidywalnie. W praktyce jednak ankiety i pomiary zawierają błędy i skrajne wartości, które mogą silnie zniekształcić wyniki. Artykuł przedstawia nowy sposób obliczania średnich populacyjnych, który pozostaje wiarygodny nawet gdy dane są „brudne”, dzięki czemu decyzje oparte na badaniach stają się bardziej godne zaufania.
Kiedy proste średnie zawodzą
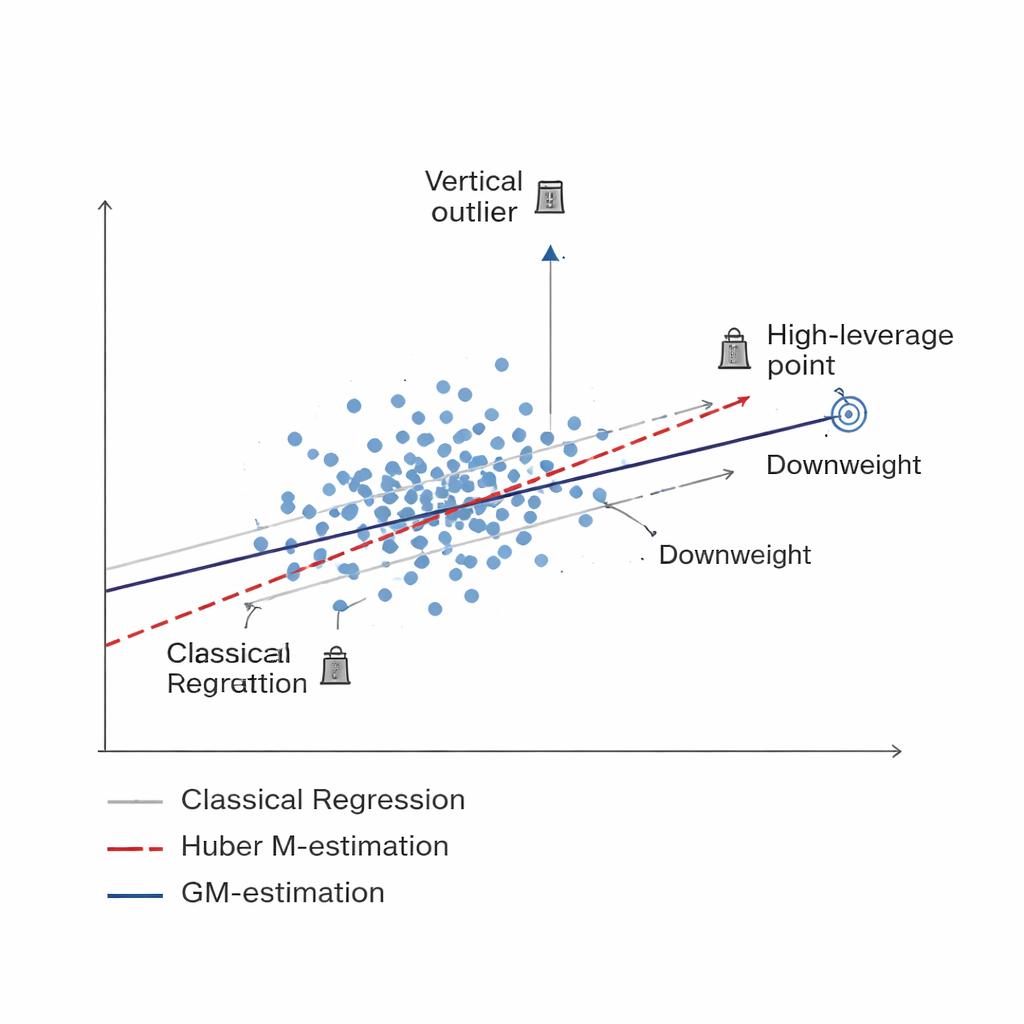
Standardowe narzędzia do estymacji średniej populacji, jak klasyczna średnia z próby czy zwykła regresja, zakładają, że większość obserwacji podąża za gładkimi wzorcami, bez skrajnych odstających wartości czy nietypowych przypadków. W badaniach społecznych i ekonomicznych, monitoringu środowiska czy statystykach rolniczych to założenie często nie jest spełnione. Kilka błędnych odczytów, rzadkie lecz skrajne zdarzenia albo błędnie zgłoszone odpowiedzi mogą odciągnąć estymaty od prawdy, zwiększając zarówno błąd systematyczny, jak i niepewność. Wcześniejsze prace próbowały łagodzić wpływ takich odstających obserwacji przy pomocy tzw. metod odpornych, w tym popularnej estymacji Huberowskiej (M). Choć pomocne, metody te głównie chronią przed skrajnymi wartościami w mierzonej zmiennej i pozostają podatne na nietypowe wzorce w informacjach objaśniających.
Sprytniejszy sposób na stłumienie złych danych Figure 1.
Badanie rozwija nową rodzinę estymatorów opartych na uogólnionej estymacji M (GM-estymacja). Zamiast traktować każdą jednostkę z próby jednakowo, metody GM przypisują adaptacyjne wagi zależne jednocześnie od dwóch czynników: jak ekstremalna jest odpowiedź jednostki (odstający pionowo obserwowany wynik) oraz jak nietypowe są jej skojarzone informacje (punkt o dużym wpływie, tzw. high-leverage). Trzy konkretne wersje — nazwane Mallows-GM, Schweppes-GM i SIS-GM — zostały zaprojektowane dla powszechnych schematów badań, w tym prostego losowania bez zwracania i bardziej złożonych projektów warstwowych, gdzie populację dzieli się na względnie jednorodne grupy. Poprzez jednoczesne kontrolowanie obu rodzajów problematycznych obserwacji, estymatory te mają na celu utrzymanie stabilności końcowej estymaty średniej populacji nawet przy poważnej „zanieczyszczalności” danych.
Testowanie nowych estymatorów
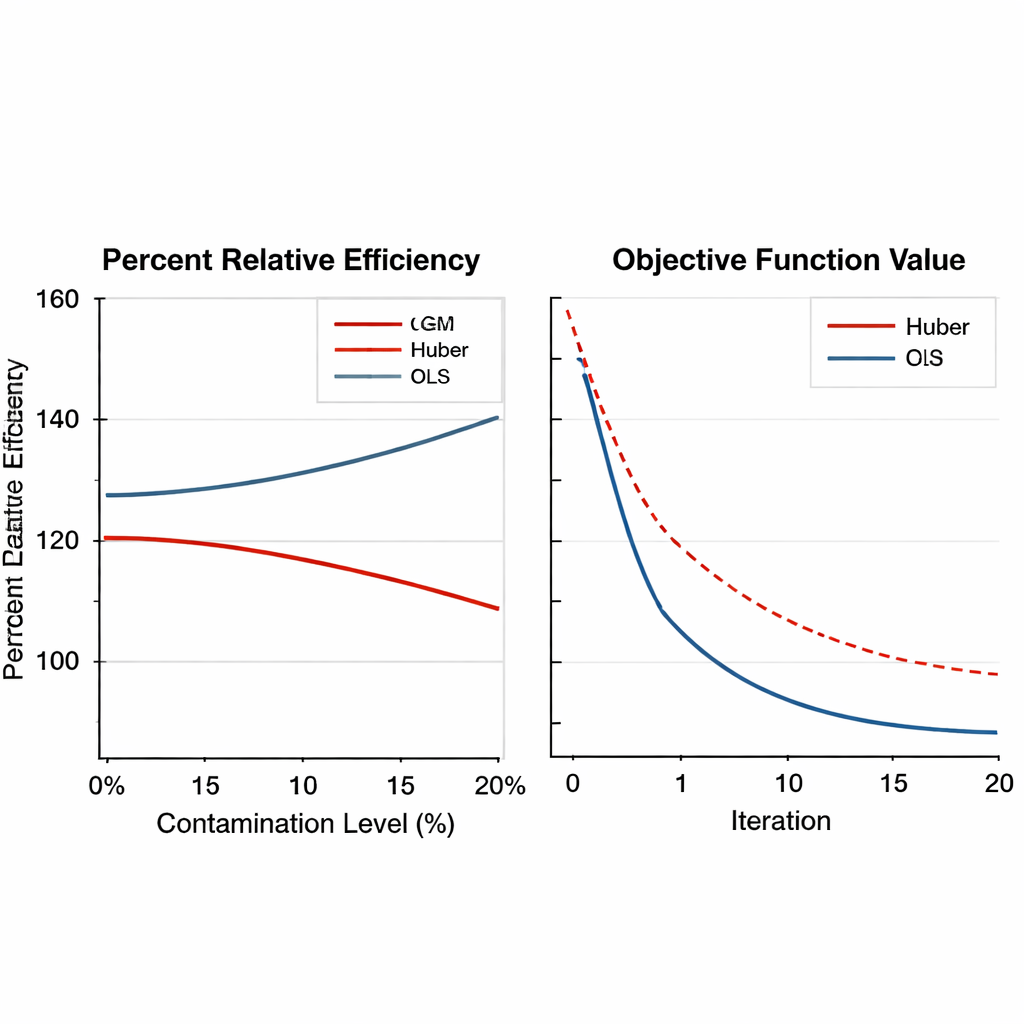
Aby sprawdzić skuteczność estymatorów opartych na GM, autor przeprowadza obszerne eksperymenty numeryczne. Najpierw analizowane są rzeczywiste dane z upraw tytoniu w dwóch wariantach: wersji oczyszczonej oraz celowo zanieczyszczonej, gdzie jedna jednostka została zastąpiona skrajnymi wartościami. Nowe estymatory porównuje się z tradycyjną regresją i odpornymi metodami opartymi na Huberze, używając miary zwanej procentową względną efektywnością, która odzwierciedla, o ile mniejszy jest błąd estymacji. W szerokim zakresie rozmiarów prób estymatory GM konsekwentnie przewyższają starsze metody, szczególnie gdy dane zawierają wartości ekstremalne. W niektórych scenariuszach najlepiej działający estymator GM zmniejsza błąd o ponad 50% w porównaniu z podejściem Huberowskim.
Odporność w różnych projektach, warunkach i ustawieniach strojenia Figure 2.
Artykuł następnie rozszerza testy, wykorzystując duże symulacje komputerowe. Sztuczne populacje generowane są według kilku kształtów rozkładów — normalnego, skośnego i o grubych ogonach — i zanieczyszczane różnymi ułamkami obserwacji odstających, od zera do 20 procent. Rozważane są zarówno proste plany próbkowania, jak i warstwowe, a siła związku między zmienną główną a zmiennikami pomocniczymi jest modulowana od słabej do silnej. Estymatory GM nie tylko utrzymują przewagę przy dużym zanieczyszczeniu, często osiągając zyski efektywności powyżej 150 procent, ale także wykazują płynną i niezawodną zbieżność numeryczną. Co ważne, ich wydajność zmienia się nieznacznie przy regulacji wewnętrznych ustawień strojenia w rozsądnych zakresach, co oznacza, że praktycy nie muszą nadmiernie dopracowywać parametrów dla każdego nowego badania.
Co to oznacza dla badań w praktyce
Mówiąc prosto, artykuł pokazuje, że proponowane estymatory oparte na GM zapewniają bezpieczniejszy sposób przekształcania niedoskonałych prób w estymaty średnich dla całej populacji. W idealnych, „czystych” warunkach danych są one mniej więcej tak samo dokładne jak metody klasyczne. Jednak gdy dane zawierają błędy pomiarowe, błędnie zgłoszone wartości czy rzadkie zdarzenia ekstremalne — jak to często bywa w badaniach krajowych, monitoringu środowiska czy statystykach finansowych — dostarczają one znacznie bardziej wiarygodnych odpowiedzi. Ponieważ są wykonalne obliczeniowo i działają dobrze w różnych projektach i warunkach, estymatory te oferują praktykom badań ulepszenie, które może uczynić decyzje oparte na dowodach bardziej odporne na nieunikniony bałagan w danych rzeczywistych.
Cytowanie: Abuhasel, K.A. A robust methodology for finite population mean estimation based on Generalized M estimation.
Sci Rep16, 5182 (2026). https://doi.org/10.1038/s41598-026-35592-5
Słowa kluczowe: próbkowanie w badaniach, estymacja odporna, wartości odstające, uogólniona estymacja M, średnia populacji skończonej