Clear Sky Science · pl
Ślepe rozpoznawanie kodów kanałowych oparte na splotowych sieciach neuronowych z podwójnym gałęziowym fuzją cech
Sprytniejsze radia dla zatłoczonego spektrum
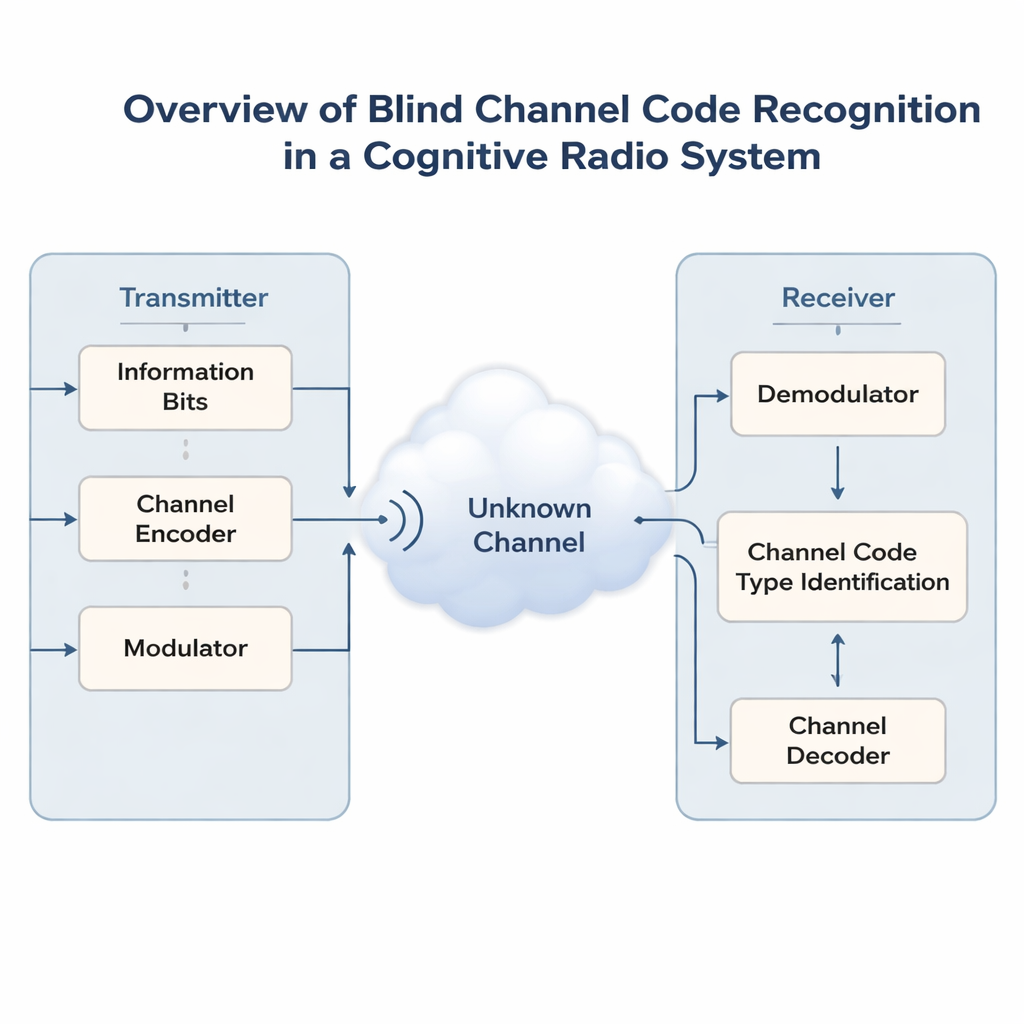
Sieci bezprzewodowe stają się coraz bardziej zatłoczone, gdy telefony, czujniki i pojazdy rywalizują o te same pasma. Aby uniknąć chaosu, przyszłe „radia kognitywne” będą musiały najpierw nasłuchiwać, a następnie inteligentnie współdzielić spektrum należące do innych użytkowników. Kluczowy problem polega na tym, że te odbiorniki często nie wiedzą, jak oryginalny sygnał został zabezpieczony przed błędami przed wysłaniem. W artykule przedstawiono nową metodę sztucznej inteligencji, która potrafi odgadnąć ukryty kod korekcyjny użyty w sygnale — bez żadnych informacji wstępnych — ułatwiając inteligentnym odbiornikom wykrycie i niezawodną komunikację.
Dlaczego ukryte kody korekcyjne są ważne
Nowoczesne łącza bezprzewodowe chronią dane za pomocą kodów korekcyjnych, które dodają starannie ustrukturyzowaną nadmiarowość, tak by odbiorniki mogły naprawiać błędy spowodowane przez szum i zakłócenia. Różne sytuacje wymagają różnych kodów: proste kody Hamminga, mocniejsze kody BCH i Reed–Solomon, elastyczne kody LDPC i Polar, czy ciągłe kody splotowe i Turbo stosowane w transmisjach strumieniowych. W warunkach niekooperacyjnych — jak komunikacja wojskowa, monitorowanie widma czy otwarte, współdzielone pasma — odbiornik nie może zapytać nadajnika, którego kodu użyto. Widziany jest jedynie zaszumiony strumień bitów. Poprawne odgadnięcie schematu kodowania, zwane ślepym rozpoznawaniem kodu, jest niezbędne przed jakimkolwiek sensownym dekodowaniem lub przetwarzaniem wyższego poziomu.
Ograniczenia wcześniejszych metod rozpoznawania
Wcześniejsze badania skupiały się albo na jednej rodzinie kodów jednocześnie, albo polegały na ręcznie zaprojektowanych statystykach, takich jak częstotliwość powtórzeń bitów, stopień losowości sekwencji czy algebraiczne sztuczki dopasowane do konkretnego kodu. Podejścia te mogą powiedzieć „to jakiś kod blokowy”, lecz mają problemy z rozróżnieniem kilku popularnych formatów naraz. Uczenie głębokie poprawiło sytuację, traktując strumienie bitów nieco jak zdania w modelu językowym. Jednak większość sieci neuronowych albo patrzy tylko na surowe sekwencje, albo tylko na ręcznie zaprojektowane cechy, i zazwyczaj radzi sobie z co najwyżej dwoma lub trzema typami kodów jednocześnie. Ich dokładność gwałtownie spada, gdy współczynnik błędów bitowych rośnie — czyli dokładnie wtedy, gdy solidne rozpoznawanie jest najbardziej potrzebne.
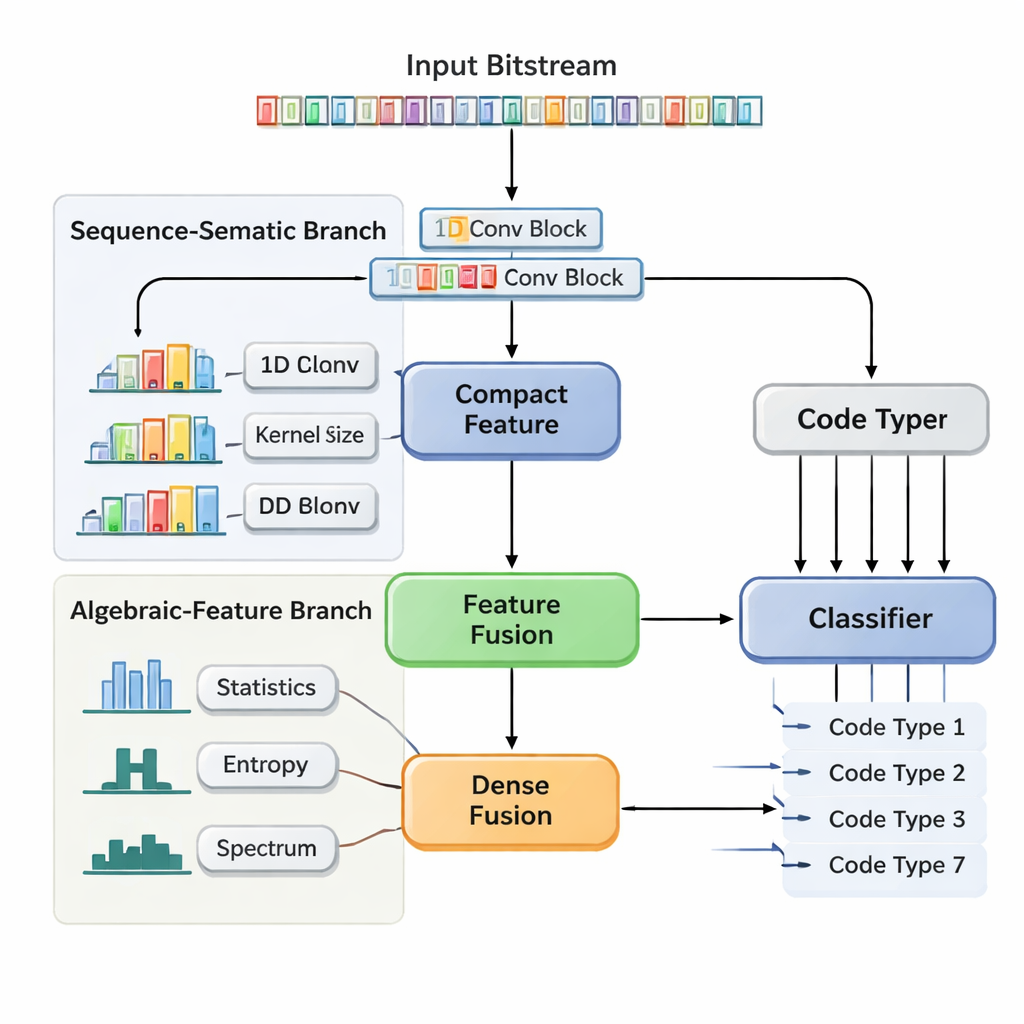
Dwutorowa sieć neuronowa analizująca strukturę i statystyki
Autorzy proponują Dual-Branch Feature Fusion Convolutional Neural Network (DBFCNN), która rozwiązuje ślepe rozpoznawanie siedmiu powszechnie stosowanych kodów za jednym razem: Hamminga, BCH, Reed–Solomon, LDPC, Polar, kodów splotowych i Turbo. Pierwsza gałąź traktuje przychodzące bity jako krótkie „słowa”, grupując je w 8-bitowe kawałki i mapując każdy kawałek na gęsty wektor, podobnie jak osadzanie słów w przetwarzaniu języka naturalnego. Następnie stosuje zestaw splotów jednowymiarowych o różnych rozmiarach okien i współczynnikach dylatacji. Małe filtry chwytają krótkozasięgowe wzorce, takie jak zwarta struktura prostych kodów blokowych, podczas gdy większe i rozszerzone filtry obejmują dłuższe zakresy, wychwytując ślady interleaverów i wzorów parzystości typowych dla kodów Turbo i LDPC. Krok globalnego uśredniania skrapla te informacje do zwartego streszczenia strukturalnego „odcisku palca” sekwencji.
Ręcznie zaprojektowane miary stabilizujące model
Druga gałąź przyjmuje zupełnie inną perspektywę. Zamiast surowych bitów oblicza siedem rodzin opisowych statystyk, które inżynierowie wiedzą, że są wrażliwe na wybór kodu. Obejmują one częstotliwość występowania runów identycznych bitów, złożoność sekwencji, pozorną losowość, siłę korelacji z przesuniętymi kopiami oraz rozkład energii w dziedzinie częstotliwości. Dodatkowe miary analizują, jak „liniowy” wydaje się kod oraz jak zachowują się lokalne bloki bitów. Ponieważ te statystyki zmieniają się wolniej wraz ze wzrostem szumu, dają sieci stabilną, odporną na szum perspektywę. Mała pod-sieć neuronowa przekształca ten wektor cech w kolejną zwartą reprezentację. Na końcu DBFCNN konkatenizuje obie gałęzie, normalizuje i regularizuje połączone cechy oraz podaje je do klasyfikatora, który zwraca prawdopodobieństwa dla siedmiu typów kodów.
Dowodzenie niezawodności w różnych warunkach szumowych
Aby rygorystycznie przetestować DBFCNN, autorzy wygenerowali ponad milion syntetycznych przykładów obejmujących siedem rodzin kodów, wiele ustawień parametrów oraz współczynniki błędów bitowych od niemal bezbłędnych do skrajnie zaszumionych. Model trenowano i testowano przy użyciu starannych procedur Monte Carlo, by uniknąć ukrytych nakładek między danymi treningowymi i testowymi. W całym tym zakresie DBFCNN konsekwentnie przewyższała trzy silne punkty odniesienia, w tym wcześniejszą wieloskalową dylatowaną sieć CNN zaprojektowaną specjalnie do tego zadania. Przy umiarkowanych i niskich poziomach błędów (współczynnik błędów bitowych poniżej 10⁻³) nowa sieć poprawnie identyfikowała typ kodu około 98% czasu, zwiększając absolutną dokładność o około 5–11 punktów procentowych w porównaniu z najsilniejszym wcześniejszym modelem. Nawet gdy poziom szumu był bardzo wysoki, DBFCNN zachowywała wyraźną przewagę i potrafiła nadal rozpoznawać kilka złożonych kodów z wysokim poziomem ufności.
Co to oznacza dla przyszłych inteligentnych radii
Dla laików kluczowy wniosek jest taki, że praca ta pokazuje, jak łączenie wiedzy dziedzinowej z uczeniem głębokim może uczynić radia znacznie bardziej samodzielnymi. DBFCNN uczy się subtelnego „akcentu” różnych kodów korekcyjnych w zaszumionych strumieniach bitów, nasłuchując równocześnie na dwa sposoby: jedna gałąź wyłapuje szczegółowe wzorce lokalne, podczas gdy druga mierzy globalne wskazówki statystyczne. Poprzez fuzję tych perspektyw system zazwyczaj potrafi dokładnie rozpoznać, który schemat kodowania jest używany, bez współpracy nadawcy. Ta zdolność stanowi blok konstrukcyjny dla radii kognitywnych, które mogą dołączać do nieznanych sieci, dostosowywać się do zmieniających się warunków i lepiej wykorzystywać ograniczone spektrum, a jednocześnie utrzymywać niezawodność komunikacji nawet gdy powietrze jest zatłoczone i zaszumione.
Cytowanie: Ma, Y., Lei, Y., Liu, C. et al. Blind recognition of channel codes based on dual-branch feature fusion convolutional neural networks. Sci Rep 16, 5159 (2026). https://doi.org/10.1038/s41598-026-35558-7
Słowa kluczowe: radio kognitywne, kodowanie kanałowe, uczenie głębokie, korekcja błędów, klasyfikacja sygnałów