Clear Sky Science · pl
Precyzyjne generowanie wypisów ze szpitala przy użyciu dostrojonych dużych modeli językowych z mechanizmem samooceny
Dlaczego papierkowa robota w szpitalu naprawdę ma znaczenie
Gdy pacjent opuszcza szpital, historia jego choroby nie kończy się na drzwiach wyjściowych. Lekarze w innych placówkach, lekarze rodzinni oraz sami pacjenci polegają na kluczowym dokumencie zwanym wypisem, aby zrozumieć, co wydarzyło się w szpitalu i co robić dalej. Tymczasem pisanie tych wypisów to powolna, powtarzalna praca, która może zabrać zajętym klinicystom pół godziny lub więcej na pacjenta. W badaniu tym zbadano, jak nowoczesne narzędzia językowe AI mogą pomóc szybciej i dokładniej sporządzać wypisy, przy jednoczesnym zachowaniu prywatności danych pacjenta i kontroli szpitala.
Przekształcanie rozrzuconych zapisów w przejrzystą opowieść
Informacje szpitalne są rozproszone po wielu systemach elektronicznych: wyniki badań laboratoryjnych w jednej tabeli, notatki pooperacyjne w innej, obserwacje pielęgniarskie w kolejnej itd. Pobyt każdego pacjenta generuje tysiące drobnych fragmentów tekstu. Badacze najpierw zbudowali pipeline, który przekształca te rozproszone, nieuporządkowane informacje w czyste dane wejściowe zrozumiałe dla modelu AI. Stosując metody scalania i usuwania duplikatów nakładających się zapisów, filtrowania danych identyfikujących takich jak imiona i numery, poprawiania pisowni oraz ujednolicania terminologii medycznej, stworzyli ustrukturyzowane dane wejściowe dla każdego pobytu szpitalnego. Ten proces zastosowano do danych ponad 6 000 pacjentów po operacji tarczycy w dużym chińskim szpitalu, tworząc sparowane przykłady rzeczywistych wypisów i surowych danych, z których zostały napisane. 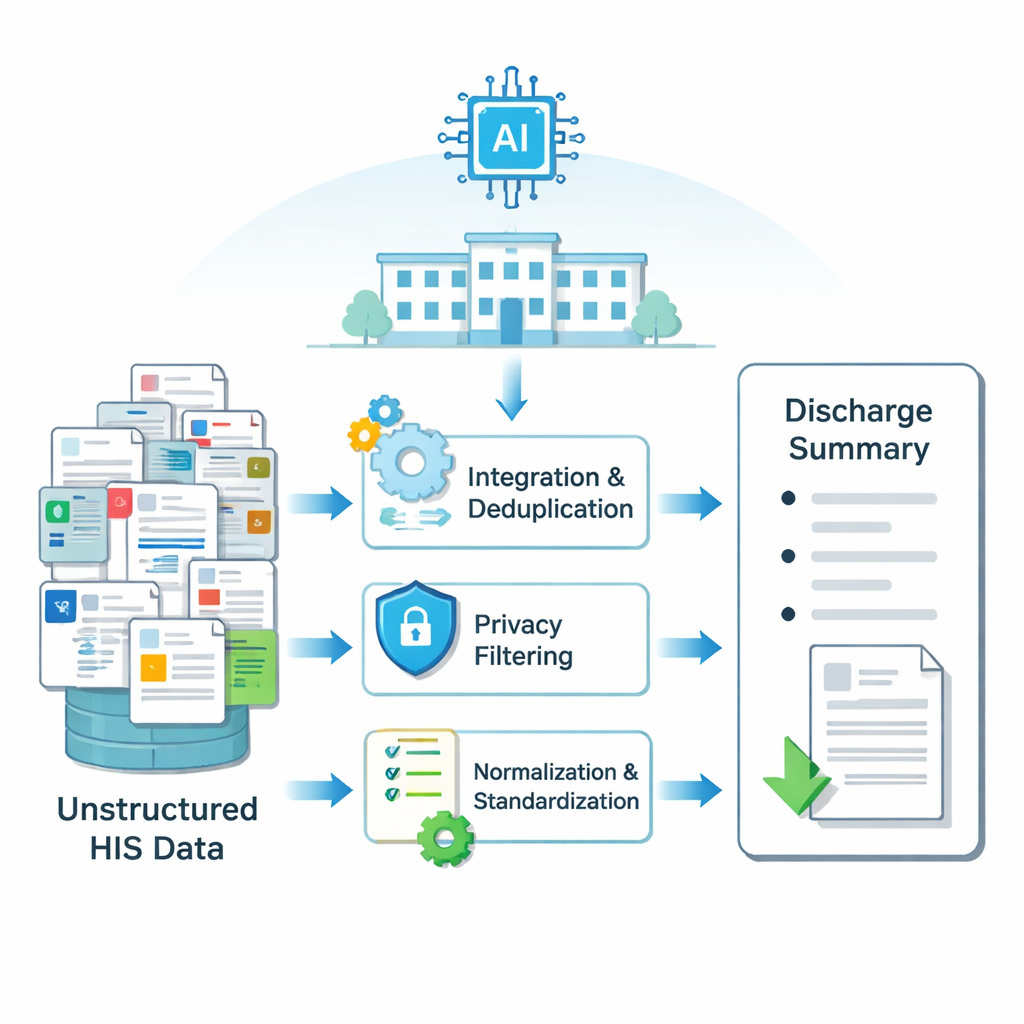
Dostrajanie AI, by mówiła językiem medycyny
Gotowe modele dużych języków są trenowane na ogólnym tekście z internetu i książek, dlatego często mają trudności ze specjalistycznym językiem medycznym i lokalnymi stylami dokumentacji. Zespół porównał kilka sposobów „dostrajania” istniejących modeli, aby lepiej rozumiały chińskie zapisy medyczne. Nowa metoda nazwana dekompozycją wag i adaptacją niskiego rzędu, czyli DoRA, koryguje wewnętrzne wagi modelu w bardziej ukierunkowany sposób niż starsze techniki, takie jak LoRA i QLoRA. We wszystkich porównywanych modelach, w tym Qwen2, Mistral i Llama 3, DoRA konsekwentnie generowała wypisy bardziej płynne, bliższe znaczeniowo wypisom pisanym przez ludzi i mniej zdezorientowane (mierzone standardową miarą zwaną perplexity). W istocie DoRA pomogła AI opanować medyczne frazeologizmy i terminologię bez potrzeby pełnego retreningu na ogromnym sprzęcie.
Nauczanie AI, by sprawdzała własną pracę
Nawet dobrze wytrenowany model może zapomnieć ważne szczegóły lub wprowadzić drobne błędy, gdy tworzy długi wypis jednym przebiegiem. Zainspirowani psychologicznymi koncepcjami szybkiego „Systemu 1” versus wolniejszego, bardziej uważnego „Systemu 2”, autorzy zaprojektowali pętlę samooceny. Najpierw model tworzy wstępny wypis na podstawie przetworzonych danych szpitalnych. Następnie oryginalne dane dzielone są na segmenty — takie jak wyniki patologiczne, zlecenia lekarzy czy panele laboratoryjne — i każdy segment jest ponownie parowany z roboczym wypisem. Model jest, w praktyce, pytany: „Czy wszystko z tego segmentu jest odzwierciedlone w wypisie?” Jeśli nie, poprawia tekst, aby dodać brakujące lub niespójne informacje. Cykl ten powtarza się do trzech razy lub do momentu, gdy model uzna wypis za kompletny, tworząc dopracowaną wersję, która wierniej odpowiada dokumentacji pacjenta. 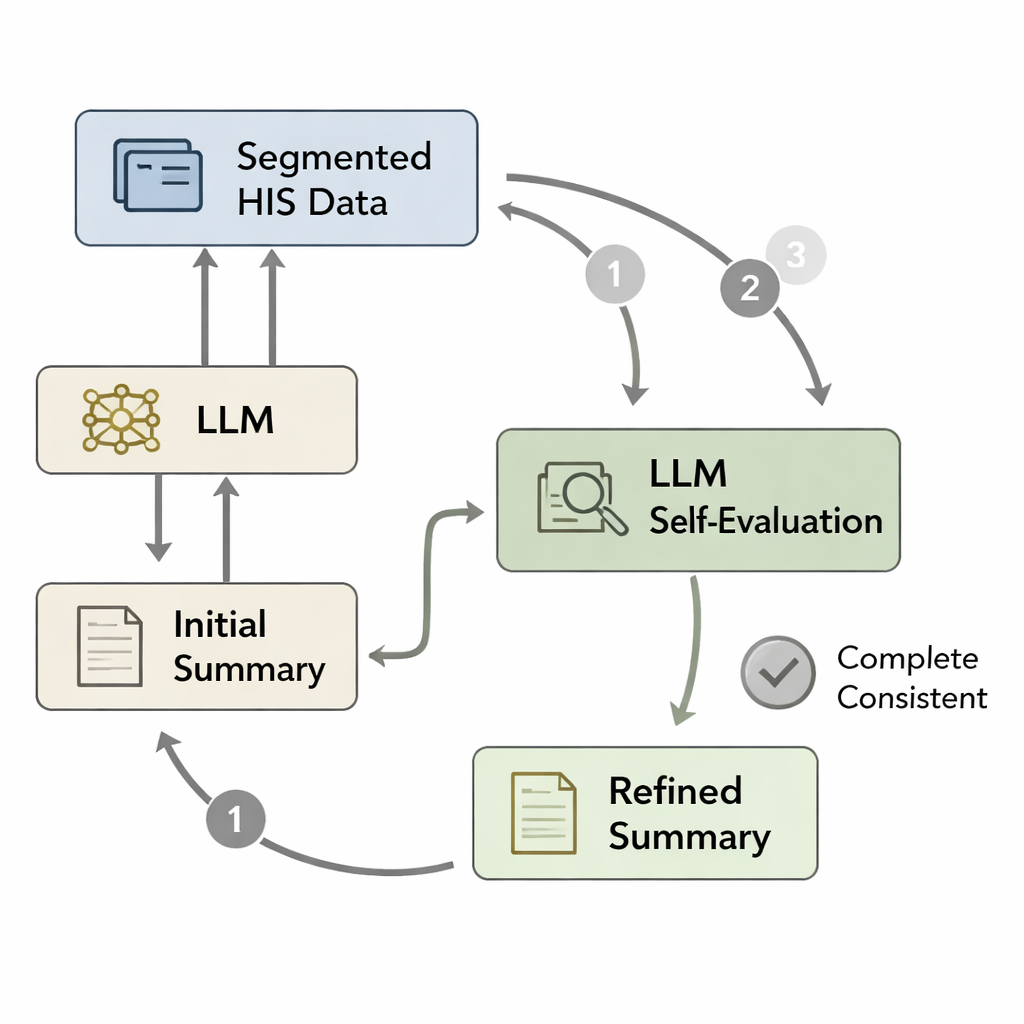
Jak AI wypadła w porównaniu z ludźmi?
Aby ocenić jakość, zespół zastosował zarówno automatyczne miary, jak i recenzentów ludzkich. Lekarze i badacze medyczni oceniali wypisy pod kątem dokładności, kompletności, czytelności, spójności i przydatności dla dalszej opieki. Najlepszy system — łączący dostrajanie DoRA z pętlą samooceny — był najbliższy wypisom napisanym przez ludzi we wszystkich ocenianych wymiarach. Szczególnie poprawiła się kompletność, czyli mniej pominiętych rozpoznań, terapii czy kluczowych wartości laboratoryjnych. W szczegółowym przykładzie AI początkowo zapomniała wspomnieć o małym raku tarczycy i o konkretnej tabletce hormonalnej; po dwóch przejściach samooceny oba szczegóły zostały poprawnie dodane. Średnio system wygenerował wypis w około 80 sekund na serwerze szpitalnym, w porównaniu z 30–50 minutami, które zajmuje klinicyście sporządzenie go od zera, choć weryfikacja ludzka pozostaje niezbędna przed wprowadzeniem tekstu do oficjalnej dokumentacji.
Co to może oznaczać dla pacjentów i klinicystów
Badanie pokazuje, że przy starannym szkoleniu i wbudowanych mechanizmach samokontroli systemy AI mogą wygenerować wypisy na tyle dokładne, by po krótkiej kontroli ludzkiej uznać je za klinicznie akceptowalne. Nie zastępuje to lekarzy, ale może przekształcić ich czas z rutynowego pisania w przeglądanie i podejmowanie decyzji na wyższym poziomie. Przechowując wszystkie obliczenia w sieci szpitalnej i usuwając dane identyfikujące, podejście to szanuje także prywatność pacjentów. Chociaż dotychczasowe wyniki pochodzą z jednego oddziału w jednym szpitalu, ramy te wskazują kierunek, w którym AI może pomagać przekształcać złożone dane medyczne w jasne, wiarygodne narracje w wielu specjalnościach, wspierając bezpieczniejsze przekazy opieki oraz lepsze zrozumienie dla pacjentów i ich rodzin.
Cytowanie: Li, W., Feng, H., Hu, C. et al. Accurate discharge summary generation using fine tuned large language models with self evaluation. Sci Rep 16, 5607 (2026). https://doi.org/10.1038/s41598-026-35552-z
Słowa kluczowe: wypisy ze szpitala, sztuczna inteligencja w medycynie, duże modele językowe, dokumentacja kliniczna, samoocena