Clear Sky Science · pl
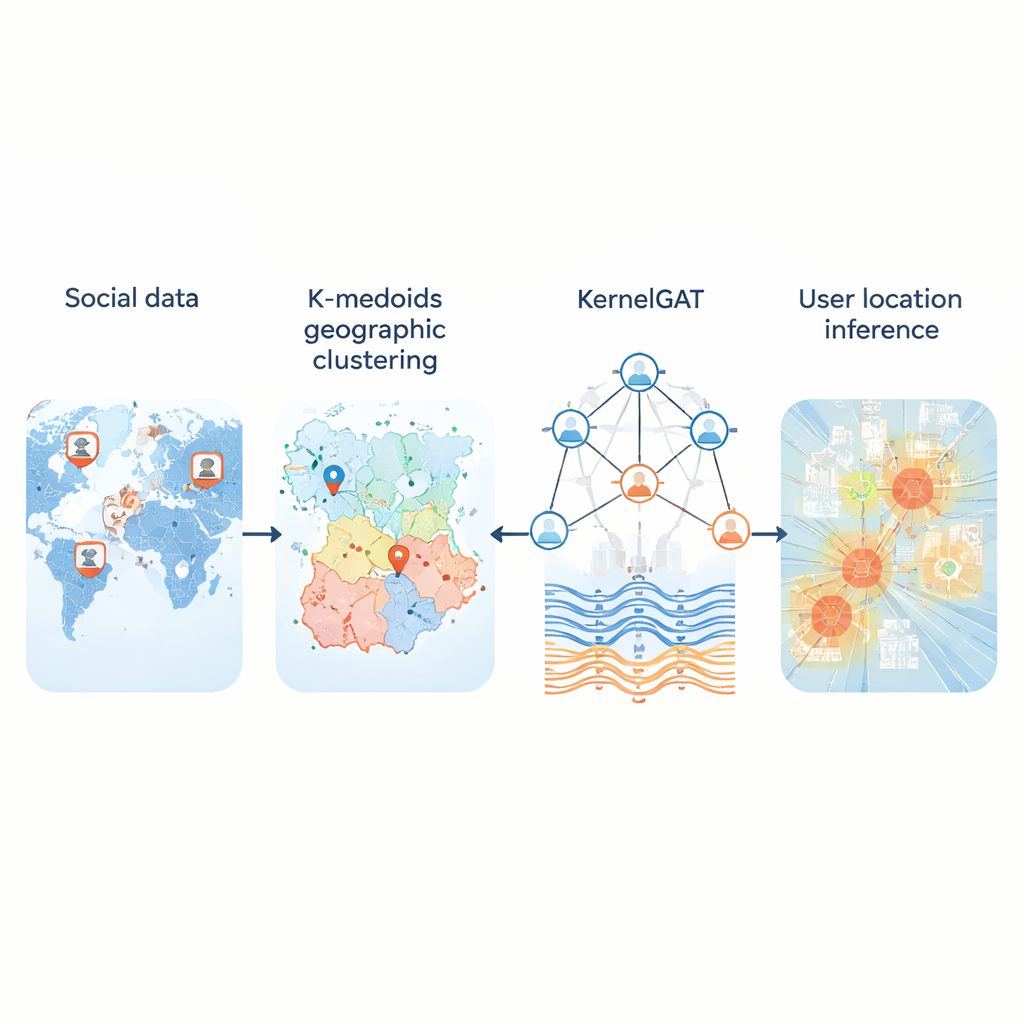
Geolokalizacja użytkowników społecznościowych oparta na K-medoidach i grafowej sieci uwagi z jądrem Gaussowskim
Dlaczego twoje tweety mogą ujawnić, gdzie mieszkasz
Codziennie miliony osób publikują w mediach społecznościowych, nie udostępniając współrzędnych GPS. Mimo to ich wpisy pozostawiają wskazówki dotyczące miejsca zamieszkania, pracy czy podróży. Możliwość wnioskowania o lokalizacji z tego publicznego śladu ma znaczenie dla wielu zastosowań — od reagowania w sytuacjach kryzysowych i monitorowania chorób po rekomendacje lokalne i usługi ukierunkowane geograficznie. W artykule wprowadzono nową metodę o nazwie KMKGAT, która wykorzystuje zarówno treść wypowiedzi, jak i sieć powiązań online, aby oszacować lokalizację z większą dokładnością niż wcześniejsze podejścia.
Z internetowych rozmów do realnych miejsc
Gdy użytkownicy piszą tweety lub mikrobloga, mogą wspominać nazwy miejsc, używać lokalnych zwrotów lub wchodzić w interakcje z pobliskimi znajomymi. Firmy takie jak Twitter (obecnie X) znają adres internetowy użytkownika, ale zewnętrzni badacze i dostawcy usług zwykle nie mają do niego dostępu. Muszą więc polegać na informacjach publicznych: samym tekście, profilach użytkowników i sieci kontaktów. Wcześniejsze metody można podzielić na trzy grupy. Metody oparte wyłącznie na treści wydobywały słowa i hashtagi, by zgadywać lokalizację. Metody oparte tylko na sieci wykorzystywały fakt, że ludzie częściej wchodzą w interakcje z użytkownikami znajdującymi się blisko. Trzecia, silniejsza rodzina łączyła oba podejścia, ale nadal miała słabe punkty — zwłaszcza w przypadku osób z obszarów o niskiej gęstości zaludnienia oraz użytkowników, których związki online rozciągają się na duże odległości.
Sprytniejsze grupowanie geograficzne z prawdziwymi centrami użytkowników
Kluczowym problemem jest przekształcenie ciągłej powierzchni Ziemi w zbiór regionów, które komputer potrafi przewidywać. Wiele systemów dzieli mapę na stałą siatkę. To działa dość dobrze w miastach, lecz zawodzi na obszarach wiejskich, gdzie ogromne komórki obejmują setki kilometrów. Nowa metoda zastępuje sztywne siatki klastrowaniem k-medoidów — sposobem grupowania użytkowników tak, aby każdy region miał centrum oparte na rzeczywistym użytkowniku, a nie sztucznym punkcie. Dzięki temu regiony są zwarte i mniej wrażliwe na wartości odstające, szczególnie tam, gdzie użytkowników jest niewiele. W testach na trzech dużych zbiorach danych z Twittera obejmujących Stany Zjednoczone i świat takie adaptacyjne partycjonowanie zmniejszyło typowe błędy w porównaniu z podejściami siatkowym i zapewniło bardziej realistyczne „regiony domowe” użytkowników.
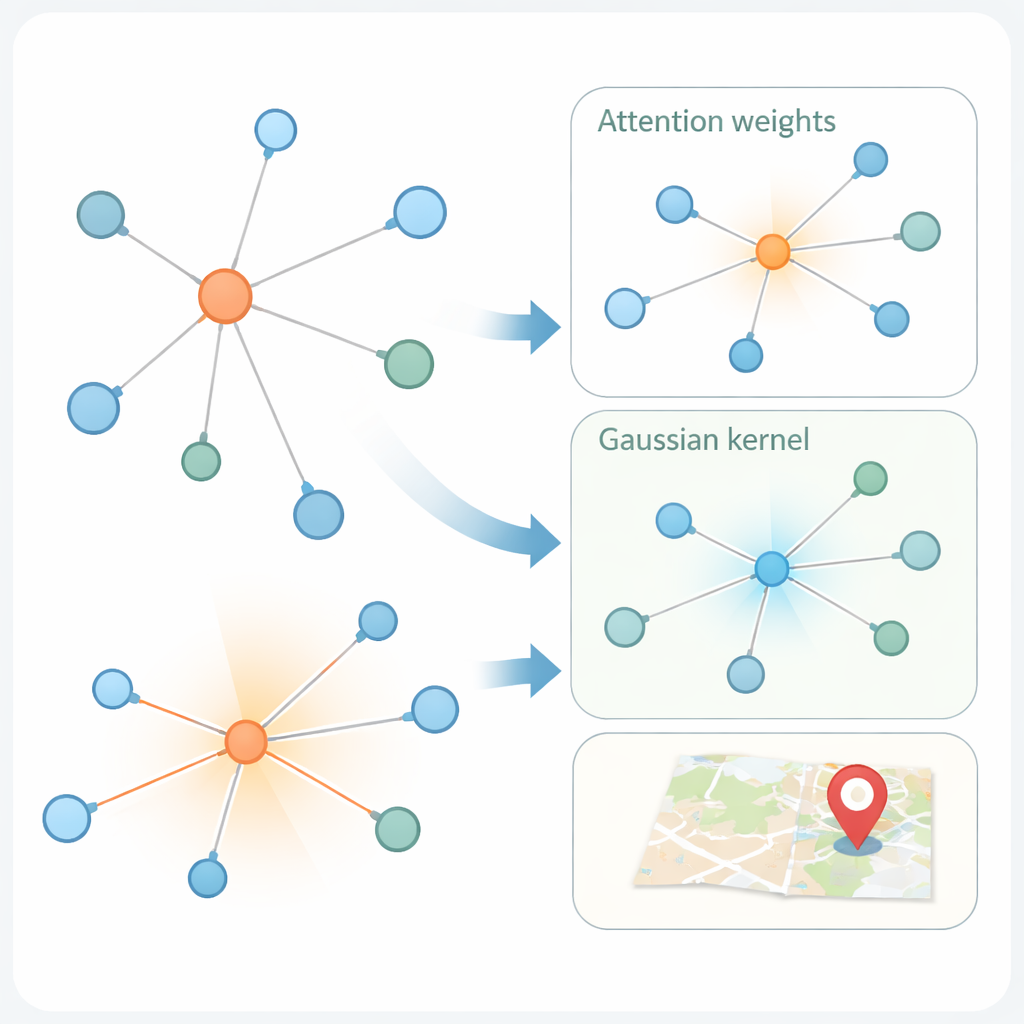
Pozwolenie sieci skupiać się na pobliskich, podobnych użytkownikach
Drugą innowacją jest sposób, w jaki model uczy się z grafu społecznościowego. Nowoczesne „grafowe sieci uwagi” już różnicują wagę sąsiadów użytkownika w zależności od podobieństwa ich reprezentacji cech. Sama miara podobieństwa może jednak wprowadzać w błąd: konto z Nowego Jorku i inne z Londynu mogą używać podobnego języka, a mimo to dzielić je setki kilometrów. KMKGAT wzbogaca mechanizm uwagi o jądro Gaussowskie — filtr matematyczny, który faworyzuje sąsiadów, których wyuczone cechy są bliskie cechom docelowego użytkownika, i tłumi wpływ odległych. Kilka takich jąder, połączonych jak mieszanka soczewek, pozwala modelowi uchwycić lokalność na różnych skalach. To respektuje prostą, lecz silną zasadę, że interakcje online są często najsilniejsze wśród osób znajdujących się fizycznie bliżej siebie.
Lekkie cechy tekstowe, które wciąż niosą wskazówki lokalizacyjne
Zamiast polegać na ciężkich modelach językowych, które mogą mieć trudności z hałaśliwym, pełnym slangu stylem tweetów, autorzy wykorzystują klasyczną technikę TF–IDF do przekształcenia zbioru postów użytkownika w torbę ważonych słów kluczowych. Powszechne słowa takie jak „the” czy „lol” otrzymują niskie wagi, podczas gdy rzadsze, specyficzne dla regionu terminy zyskują na znaczeniu. Te cechy tekstowe są następnie dołączane do każdego użytkownika w grafie społecznym i przepuszczane przez rozszerzoną sieć uwagi. Co ciekawe, najlepsze wyniki osiągano, gdy większość cech tekstowych była losowo pomijana podczas treningu, co sugeruje, że tylko niewielka część słów faktycznie pomaga w lokalizacji, a reszta dodaje głównie szum.
Pokonanie stanu wiedzy w skali
Aby ocenić wydajność, badacze mierzyli, jak daleko w kilometrach środek przewidywanego regionu znajduje się od rzeczywistych współrzędnych użytkownika oraz jaki odsetek użytkowników został umieszczony w promieniu 161 km (100 mil) od ich prawdziwej lokalizacji. Na trzech benchmarkowych zbiorach danych z Twittera KMKGAT konsekwentnie dorównywał lub przewyższał silne istniejące systemy, poprawiając dokładność w obrębie 161 km o kilka punktów procentowych — co jest znaczącym postępem na tym etapie rozwoju. Korzyści były najbardziej widoczne w małych i średnich sieciach, podczas gdy na ogromnym globalnym grafie metoda była ograniczona koniecznością próbkowania wyłącznie bezpośrednich sąsiadów w trakcie treningu.
Co to oznacza w codziennym ujęciu
Dla osób niezwiązanych z tematem kluczowa wiadomość jest taka, że coraz łatwiej jest oszacować, gdzie znajdują się użytkownicy mediów społecznościowych, nawet jeśli nigdy nie udostępniają znacznika lokalizacji. Grupując użytkowników w realistyczne regiony oparte na rzeczywistych kontach i ucząc model, by ufał przede wszystkim pobliskim, podobnym sąsiadom w sieci społecznej, KMKGAT zawęża obszar, z którego ktoś najpewniej pochodzi lub z którego publikuje. Może to pomóc służbom ratunkowym w odnajdywaniu ludzi podczas katastrof, poprawić wyszukiwanie i rekomendacje lokalne oraz wspierać badania nad tym, jak informacje rozprzestrzeniają się między miejscami. Jednocześnie podkreśla to, jak wiele naszych codziennych interakcji online może ujawnić o życiu poza internetem, akcentując znaczenie przemyślanego wykorzystania danych i ochrony prywatności.
Cytowanie: Jiao, A., Qiao, Y., Li, P. et al. Social user geolocation based on K-medoids and Gaussian Kernel graph attention network. Sci Rep 16, 5115 (2026). https://doi.org/10.1038/s41598-026-35532-3
Słowa kluczowe: geolokalizacja w mediach społecznościowych, lokalizacja użytkownika Twittera, grafowe sieci neuronowe, usługi lokalizacyjne, prywatność online