Clear Sky Science · pl
Klasyfikacja intencji dla usług administracyjnych uniwersytetu z wykorzystaniem dwukierunkowej sieci rekurencyjnej zmodyfikowanej opracowanym algorytmem optymalizacji Keplera
Inteligentniejsza cyfrowa pomoc dla codziennych pytań kampusowych
Studenci uniwersytetów oczekują dziś szybkich i precyzyjnych odpowiedzi o każdej porze — czy to przy ubieganiu się o przyjęcie, rejestracji na zajęcia, czy pytaniach o pomoc finansową. W artykule przedstawiono nowy rodzaj czatbota napędzanego sztuczną inteligencją, zaprojektowanego specjalnie do obsługi spraw administracyjnych uczelni, ze szczególnym uwzględnieniem obsługi języka angielskiego i greckiego. Ucząc jeden system lepszego rozumienia intencji studentów i istotnych szczegółów, autorzy chcą sprawić, by cyfrowe punkty pomocy były szybsze, bardziej niezawodne i łatwiejsze w utrzymaniu.
Dlaczego dzisiejsze czatboty wciąż się mylą
Większość nowoczesnych czatbotów opiera się na dziedzinie zwanej rozumieniem języka naturalnego, która dzieli pytanie studenta na dwie główne części. Pierwsza to intencja: czego student chce dokonać, na przykład „zarejestrować się na kurs” lub „zapytać o termin”. Druga to byty (entities): konkretne informacje zawarte w pytaniu, takie jak kod kursu, semestr czy nazwa programu. Tradycyjne systemy używają oddzielnych modeli do tych dwóch zadań. Taki podział marnuje pamięć i moc obliczeniową oraz może prowadzić do niespójnych odpowiedzi — na przykład poprawnego rozpoznania kodu kursu, ale niepowiązania go z właściwą akcją. Problemy te nasilają się w środowiskach wielojęzycznych, gdzie ta sama idea może być wyrażona na wiele różnych sposobów w różnych językach.
Jeden „mózg” zamiast dwóch
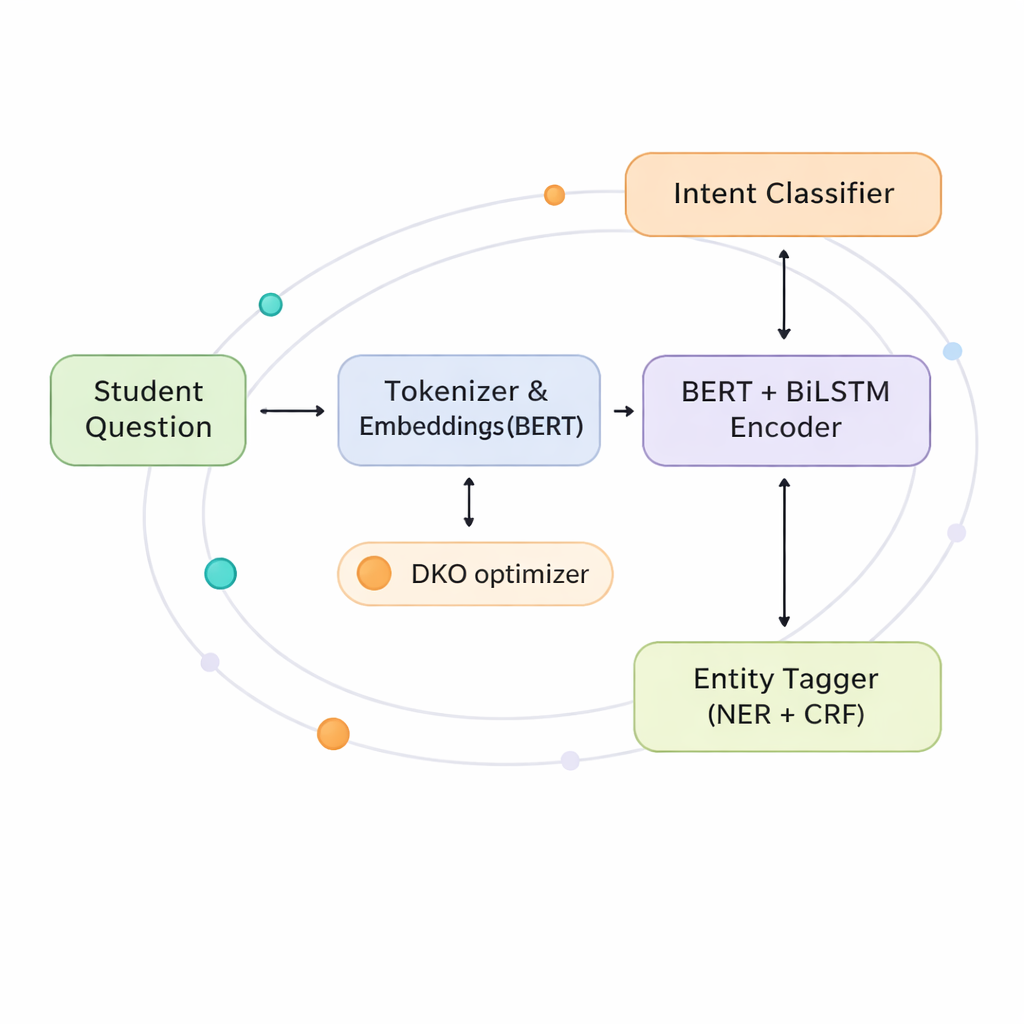
Autorzy proponują model wspólny, który uczy się rozpoznawać zarówno intencje, jak i byty jednocześnie, używając wspólnego „mózgu” zamiast dwóch oddzielnych. W jego rdzeniu znajduje się połączenie dwóch wydajnych technik. Pierwsza, BERT, analizuje całe zdanie naraz, aby uchwycić jego ogólne znaczenie. Druga, dwukierunkowa sieć LSTM, zwraca szczególną uwagę na porządek słów zarówno od lewej do prawej, jak i od prawej do lewej, co pomaga śledzić zależności lokalne, na przykład który kurs odnosi się do którego semestru. Na tej wspólnej reprezentacji system rozgałęzia się na dwie ścieżki: jedna przewiduje intencję studenta, a druga oznacza każde słowo jako byt lub nie-byt.
Pozwalając zadaniom się komunikować
Aby w pełni wykorzystać wspólny „mózg”, model zawiera warstwę „ko-interaktywnego transformera”, która pozwala obu zadaniom wzajemnie się informować w czasie rzeczywistym. Gdy system decyduje o intencji, może spojrzeć na byty, które uważa za obecne; gdy oznacza byty, może oprzeć się na najbardziej prawdopodobnej intencji. Ta wymiana informacji pomaga rozwiązywać niejednoznaczności, takie jak czy „rezygnować” oznacza opuszczenie kursu czy anulowanie zgłoszenia, i jest szczególnie przydatna w języku greckim, gdzie formy słów i szyk zdania są bardziej elastyczne niż w angielskim. Poprzez dzielenie reprezentacji i mechanizmów uwagi model zmniejsza liczbę parametrów o niemal połowę w porównaniu z uruchamianiem dwóch dużych modeli osobno, co czyni go bardziej praktycznym dla działów IT uczelni.
Kosmicznie inspirowany sposób trenowania modelu
Trenowanie tak rozbudowanego modelu jest trudne: standardowe metody optymalizacji mogą być wolne i wrażliwe na drobne ustawienia. Autorzy wprowadzają algorytm Developed Kepler Optimization (DKO), inspirowany ruchem planet wokół słońca. W tej analogii różne wersje modelu są jak planety eksplorujące przestrzeń możliwych ustawień parametrów, przyciągane w stronę najlepiej działającego „słońca”. DKO uruchamia kandydatów w bardziej zróżnicowanym rozkładzie niż zwykle, a następnie ciągle dostosowuje ich „orbity” w oparciu o to, jak dobrze sobie radzą. Podejście to przyspiesza uczenie o około 42 procent w porównaniu z popularną metodą Adam, a także sprawia, że trening jest bardziej stabilny, szczególnie na złożonych, wielojęzycznych danych.
Testy w rzeczywistych warunkach ze studentami
Zespół ocenił swój system na kilku zbiorach danych, w tym UniWay, kolekcji pytań po angielsku i po grecku dotyczących usług uniwersyteckich, oraz xSID, dobrze znanym benchmarku do rozumienia krótkich poleceń. We wszystkich przypadkach model wspólny konsekwentnie przewyższał systemy oparte na regułach, starsze sieci neuronowe, a nawet silne bazowe transformery. W testach terenowych na dwóch uniwersytetach — jednym anglojęzycznym i jednym dwujęzycznym — czatbot poprawnie identyfikował intencje i byty studentów w około dziewięciu przypadkach na dziesięć, a studenci ocenili swoje zadowolenie na około 4,5 na 5. Wyniki pozostawały wysokie nawet przy ograniczonych danych treningowych, co sugeruje, że metoda jest odporna w warunkach niskich zasobów językowych i dziedzinowych.
Co to oznacza dla studentów i uczelni
Dla osoby nietechnicznej kluczowe przesłanie jest takie, że autorzy zaprojektowali wydajniejszy i dokładniejszy „silnik słuchający” dla czatbotów uniwersyteckich. Poprzez unifikację wykrywania intencji i wydobywania szczegółów oraz zastosowanie inspirowanej orbitami metody trenowania, ich system lepiej rozumie pytania studentów przy mniejszym zużyciu pamięci i czasu treningu. Może to przełożyć się na szybsze odpowiedzi, mniej nieporozumień i całodobowe, wielojęzyczne wsparcie bez nadmiernego obciążania personelu. Chociaż wyzwania pozostają — jak dostosowanie do nowych polityk, więcej języków czy długoterminowe wzorce użytkowania — praca ta wskazuje drogę do systemów pomocy na kampusie, które będą bardziej responsywne, sprawiedliwe i skalowalne.
Cytowanie: Yang, Z., Lu, M. & Huang, S. Intent classification for university administrative services using a bidirectional recurrent neural network modified by a developed Kepler optimization algorithm. Sci Rep 16, 6263 (2026). https://doi.org/10.1038/s41598-026-35504-7
Słowa kluczowe: czatboty uniwersyteckie, klasyfikacja intencji, rozpoznawanie nazwanych bytów, wielojęzyczna sztuczna inteligencja, algorytmy optymalizacyjne