Clear Sky Science · pl
Zautomatyzowana identyfikacja kontekstowo istotnych jednostek biomedycznych za pomocą ugruntowanych LLM
Dlaczego inteligentniejsze tagowanie artykułów medycznych ma znaczenie
Co roku pojawiają się tysiące badań biomedycznych, z których każde zawiera szczegóły dotyczące genów, typów komórek, chorób i terapii. Większość tych informacji pozostaje jednak uwięziona w długich plikach PDF, co utrudnia innym naukowcom znalezienie dokładnych danych, których potrzebują. Artykuł ten opisuje, jak współczesna sztuczna inteligencja — duże modele językowe (LLM) — może automatycznie wyodrębniać kluczowe terminy biomedyczne z prac badawczych, pomagając przekształcić rozproszone publikacje w dobrze zorganizowane, przeszukiwalne zasoby.
Od nieuporządkowanych artykułów do przeszukiwalnych elementów
Ośrodki badawcze zajmujące się biomedycyną, takie jak niemieckie Collaborative Research Centers, polegają na jasnych, ustrukturyzowanych danych, aby uczynić badania ponownie użytecznymi przez wiele lat. Tradycyjnie badacze musieli ręcznie tagować swoje zestawy danych ważnymi jednostkami, takimi jak organizmy, linie komórkowe czy geny — żmudne i czasochłonne zadanie. LLM potrafią czytać całe artykuły i rozumieć kontekst, co czyni je obiecującymi narzędziami do automatyzacji tego tagowania. Istnieje jednak istotny warunek: decyzja, które terminy naprawdę są istotne, zależy od pytania naukowego i sposobu ponownego wykorzystania danych. Autorzy pracują w ramach starannie zaprojektowanego schematu metadanych zorientowanego na nefrologię CRC „NephGen”, który mówi AI, jakiego rodzaju jednostek ma szukać i jak je organizować.
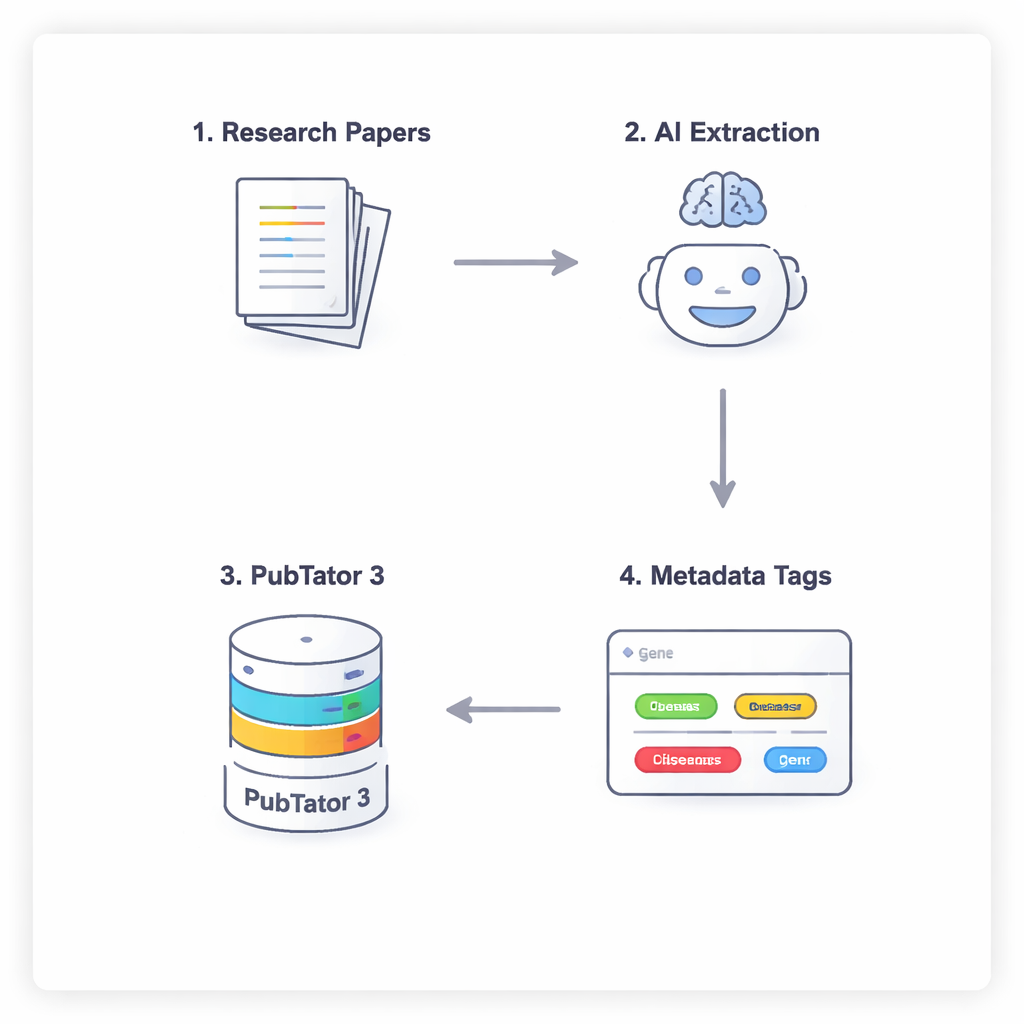
Rozmowa w czterech krokach między AI a bazą biologiczną
Aby zapobiec temu, by AI jedynie zgadywała lub „halucynowała” fakty biomedyczne, badacze stosują proces w czterech krokach, który wymusza staranne rozumowanie i weryfikację. Najpierw model skanuje pełny tekst artykułu (ignorując dyskusję i bibliografię), aby zasugerować potencjalnie istotne jednostki. Po drugie, musi skonsultować się z zewnętrznym narzędziem, PubTator 3 — dużą bazą danych biomedycznych — aby potwierdzić, że każdy sugerowany termin rzeczywiście istnieje i ma rozpoznawalny identyfikator. Po trzecie, AI przypisuje każdą potwierdzoną jednostkę do slotu w schemacie metadanych NephGen, który grupuje jednostki w hierarchiczną, ręcznie zaprojektowaną strukturę. Wreszcie model konsoliduje wszystko w ustrukturyzowanym wyjściu JSON, w praktyce porządnym, maszynowo czytelnym podsumowaniu kluczowych jednostek biomedycznych z artykułu.
Testowanie ośmiu modeli AI na rzeczywistych badaniach nerek
Zespół wdrożył ten workflow z użyciem interfejsów API dla 14 różnych LLM i stwierdził, że tylko osiem potrafiło niezawodnie spełniać rygorystyczne wymagania, takie jak zwracanie poprawnego JSON i prawidłowe używanie narzędzi. Następnie zastosowali te osiem modeli do sześciu artykułów z zakresu nefrologii i poprosili autorów każdego artykułu o ocenę końcowej listy jednostek wygenerowanej przez AI podczas krótkiego, bezpośredniego wywiadu. Ponieważ nie ma jednej „poprawnej” liczby jednostek do wyodrębnienia, autorzy skupili się na precyzji: jaki odsetek sugerowanych jednostek naukowcy uznali za poprawne. Używając statystycznych metod meta-analizy dostosowanych do proporcji bliskich 100%, oszacowali precyzję dla każdego modelu, uwzględniając zmienność między artykułami.
Wysoka dokładność, ale kompromisy w wysiłku, kosztach i szybkości
We wszystkich modelach systemy AI osiągnęły ogólną precyzję na poziomie około 91%, co oznacza, że zdecydowana większość sugerowanych jednostek została uznana za poprawne. GPT-4.1, GPT-4o Mini i Gemini 2.0 Flash osiągnęły najwyższą precyzję — w przybliżeniu 94%–98% — choć różnice między nimi nie były statystycznie istotne. Modele Gemini miały tendencję do proponowania większej liczby jednostek ogółem, co prowadziło do większej liczby poprawnych tagów, ale też więcej pracy do sprawdzenia przez ludzi. Niektóre mniejsze lub tańsze modele, takie jak GPT-4.1 Nano, były szybsze i tańsze, ale zdecydowanie mniej dokładne. Autorzy zobrazowali te napięcia za pomocą krzywych Pareto, identyfikując kombinacje modeli, które równoważą precyzję, liczbę poprawnych jednostek, koszt i czas przetwarzania: na przykład GPT-4o Mini okazał się szczególnie atrakcyjny, gdy priorytetem są zarówno dokładność, jak i niski koszt.
Dlaczego ludzie wciąż powinni być w pętli
Mimo dobrych wyników, badanie wskazuje na istotne ograniczenia. Modele czasem mieszały informacje odnoszące się do opublikowanego artykułu z detalami, które nie były rzeczywiście istotne dla podstawowego zestawu danych, które przyszli użytkownicy mogliby chcieć ponownie wykorzystać. To zamieszanie odzwierciedla szersze wyzwanie w automatycznym wydobywaniu tekstu: artykuły naukowe omawiają znacznie więcej niż to, co trafia do współdzielonego zestawu danych. Dlatego autorzy zalecają, by eksperci-ludzie nadal przeglądali adnotacje generowane przez AI przed ich publikacją. Zauważają też, że ich ocena obejmuje tylko sześć artykułów nefrologicznych, więc potrzebne są szersze testy w różnych dziedzinach. Z czasem rutynowy workflow „człowiek-w-pętli” mógłby stworzyć zestaw referencyjny konsensusu, umożliwiając mierzenie nie tylko precyzji, lecz także tego, ile jednostek AI pominęła.
Co to oznacza dla przyszłego udostępniania danych biomedycznych
Badanie pokazuje, że przy odpowiednim prowadzeniu i ugruntowaniu w zaufanych bazach danych nowoczesne LLM mogą niezawodnie wspierać adnotację artykułów biomedycznych, znacznie zmniejszając ręczne obciążenie badaczy. Najlepsze modele zbliżają się do precyzji na poziomie ekspertów, oferując jednocześnie różne kompromisy między szczegółowością, kosztem i szybkością. Na razie przegląd ludzki pozostaje niezbędny, aby zapewnić, że adnotacje rzeczywiście odpowiadają zestawom danych i kontekstowi badawczemu. Jednak w miarę jak narzędzia i modele open source będą dojrzewać, takie workflowy mogą stać się standardowym trzonem przekształcania dzisiejszego zalewu artykułów medycznych w dobrze zorganizowany, wielokrotnie wykorzystywany wspólny zasób danych.
Cytowanie: Watter, M., Giuliani, C., Benadi, G. et al. Automated identification of contextually relevant biomedical entities with grounded LLMs. Sci Rep 16, 1952 (2026). https://doi.org/10.1038/s41598-026-35492-8
Słowa kluczowe: wydobywanie tekstu biomedycznego, duże modele językowe, adnotacja metadanych, ugruntowana sztuczna inteligencja, badania nefrologiczne