Clear Sky Science · pl
Predykcja współczynnika bezpieczeństwa dla wysokich nasypów drogowych przy użyciu mieszanego lasu losowego i optymalizacji rojem pszczół
Dlaczego stabilność nasypów drogowych ma znaczenie
Gdy jedziesz autostradą położoną na usypanym kopcu ziemnym, zakładasz, że ta sztuczna skarpa nie runie nagle. Bezpieczeństwo takich wysokich nasypów ocenia się liczbowo za pomocą tzw. „współczynnika bezpieczeństwa”, który porównuje siły utrzymujące grunt na miejscu z siłami dążącymi do jego zsuwu. Tradycyjnie inżynierowie polegali na ręcznych obliczeniach lub rozbudowanych symulacjach komputerowych, by oszacować ten współczynnik. Badanie pokazuje, jak nowoczesne metody uczenia maszynowego mogą przyspieszyć i uczynić te przewidywania bardziej niezawodnymi, co potencjalnie zmniejsza ryzyko katastrofalnych osuwisk zagrażających ludziom, mieniu i sieciom transportowym.
Budowanie tysięcy wirtualnych nasypów
Aby wytrenować i przetestować modele, badacze najpierw stworzyli dużą, realistyczną bazę danych przy użyciu zaawansowanych symulacji numerycznych, zamiast polegać wyłącznie na kilku studiach przypadków z terenu. Modelowali nasypy drogowe o wysokości od 6 do 30 metrów z wieloma różnymi kształtami skarp, w tym z konstrukcjami tarasowymi wykorzystującymi poziome półki zwane bermami poprawiającymi stabilność. Zmieniali kluczowe właściwości gruntu — takie jak gęstość, zawartość wody, sztywność, odporność na poślizg oraz spójność — wraz z nośnością podłoża pod nasypem. Dla każdego z 1 176 scenariuszy program elementów skończonych obliczał współczynnik bezpieczeństwa i wyszukiwał najbardziej prawdopodobną powierzchnię poślizgu, dostarczając zaufaną „wartość odniesienia”, względem której można było oceniać predykcje uczenia maszynowego.
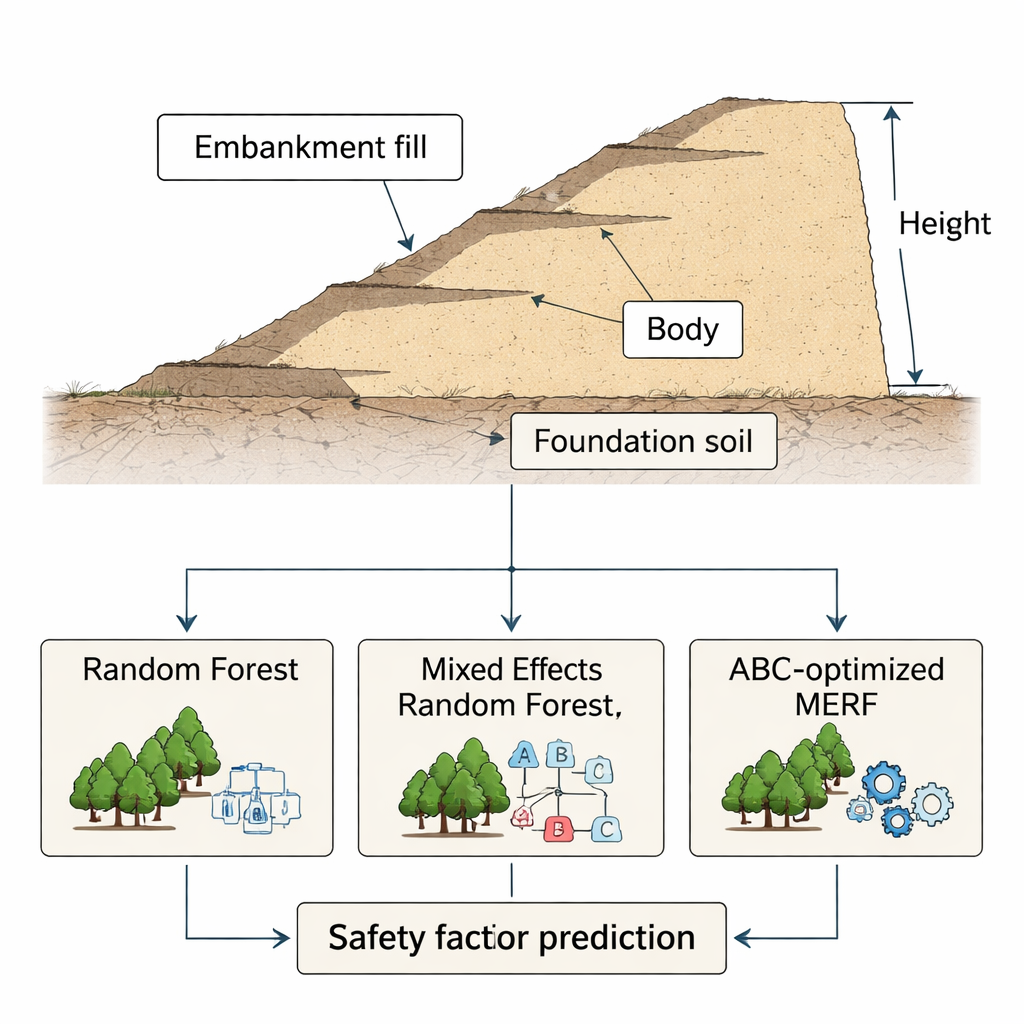
Od klasycznych modeli do inteligentniejszych lasów
Zespół porównał następnie trzy rodzaje modeli opartych na danych. Pierwszym był dobrze znany Random Forest, łączący wiele drzew decyzyjnych w celu uzyskania odpornych przewidywań. Drugim, zwanym Mixed Effects Random Forest, rozszerzono to podejście poprzez uwzględnienie zgrupowanych lub „sklastrowanych” danych — typowej sytuacji w pracach geotechnicznych, gdzie zestawy pomiarów mogą pochodzić z tego samego miejsca, typu gruntu lub etapu budowy. Wreszcie wprowadzono hybrydowe rozwiązanie: Mixed Effects Random Forest zoptymalizowany algorytmem Artificial Bee Colony (ABC‑MERF). Tutaj algorytm optymalizacyjny inspirowany rojami, wzorowany na sposobie, w jaki pszczoły poszukują pożywienia, automatycznie dostraja liczne parametry lasu mieszanego, aby uzyskać lepsze wyniki bez żmudnego ręcznego strojenia przez inżyniera.
Oczyszczanie danych i testowanie przewidywań
Przed trenowaniem modeli badacze starannie przygotowali dane. Zidentyfikowali skrajne wartości odstające przy użyciu standardowej metody wykresu pudełkowego i ograniczyli je do rozsądnych granic, aby rzadkie odchylenia nie zaburzały procesu uczenia. Wszystkie wejścia zostały następnie przeskalowane do przedziału 0–1, co odpowiada optymalizatorowi inspirowanemu pszczołami i utrzymuje zmienne w porównywalnej skali. Dane podzielono na zbiory treningowe i testowe, a ścisły protokół oceny wykorzystał kilka miar błędu, w tym zbieżność przewidywań z symulowanymi współczynnikami bezpieczeństwa oraz odsetek wyjaśnionej wariancji. Dodatkowe sprawdzenia, takie jak wykresy reszt i testy statystyczne, potwierdziły, że modele nie zapamiętują jedynie danych treningowych, lecz rzeczywiście uczą się leżących u podstaw wzorców.
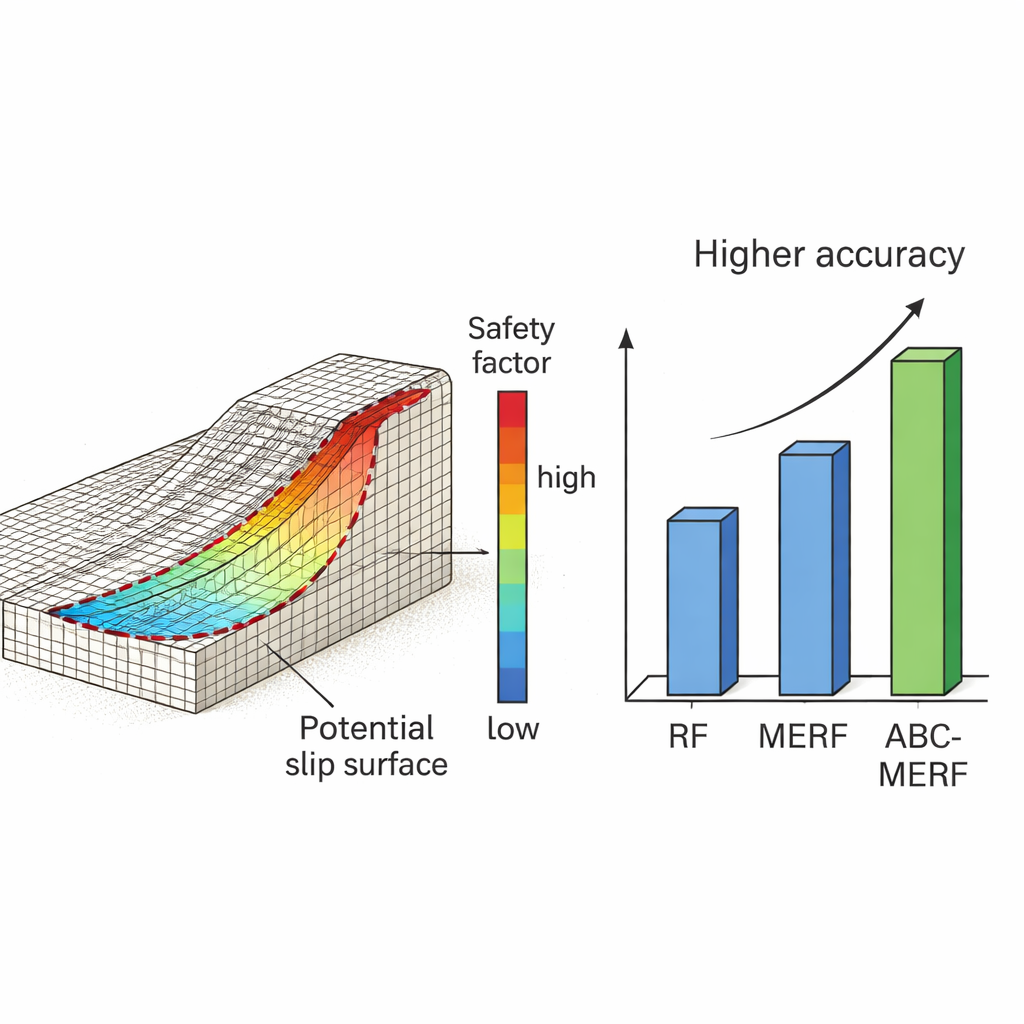
Co modele nauczyły się o gruncie i skarpach
Wszystkie trzy podejścia wypadały imponująco, jednak model ABC‑MERF okazał się najlepszy. Wyjaśnił ponad 99 procent zmienności współczynnika bezpieczeństwa i utrzymywał typowe błędy predykcji na poziomie około dwóch procent zakresu bezpieczeństwa. Równie istotne, zachowanie modelu miało sens fizyczny. Analizy ważności cech i krzywych odpowiedzi wykazały, że największy wpływ miały kąt tarcia wewnętrznego gruntu nasypu i wysokość nasypu, następnie nachylenie skarpy, spójność oraz stosowanie berm. Wyższe kąty tarcia i większa spójność zwiększały stabilność, podczas gdy wyższe nasypy i strome skarpy ją zmniejszały — dokładnie zgodnie z przewidywaniami podstawowej mechaniki gruntów. To zgodność wyników opartych na danych z teorią inżynierską jest kluczowa, jeśli praktycy mają zaufać narzędziom uczenia maszynowego w projektach o krytycznym znaczeniu dla bezpieczeństwa.
Od narzędzia badawczego do asystenta inżyniera
Badanie konkluduje, że starannie zaprojektowana hybryda mieszanego lasu losowego i optymalizacji inspirowanej pszczołami może dostarczać wysoce dokładnych, fizycznie sensownych prognoz współczynnika bezpieczeństwa dla wysokich nasypów drogowych. Dla czytelnika niebędącego specjalistą kluczowy wniosek jest taki, że inżynierowie mogą teraz łączyć szczegółowe testy wirtualne z zaawansowanym uczeniem maszynowym, by szybko przesiać wiele wariantów projektowych i wskazać ryzykowne konfiguracje zanim zostaną zbudowane. Chociaż takie modele nie zastąpią eksperckiej oceny ani badań terenowych — zwłaszcza w warunkach trzęsień ziemi czy intensywnych opadów — oferują potężne narzędzie wsparcia decyzji, które może pomóc utrzymać nasypy pod naszymi drogami stabilne i bezpieczne przez długi okres eksploatacji.
Cytowanie: Boufarh, R., Boursas, F., Bakri, M. et al. Factor of safety prediction for high road embankments using mixed effects random forest and bee colony optimization. Sci Rep 16, 6003 (2026). https://doi.org/10.1038/s41598-026-35431-7
Słowa kluczowe: stabilność skarp, nasypy drogowe, współczynnik bezpieczeństwa, uczenie maszynowe, inżynieria geotechniczna