Clear Sky Science · pl
Łączenie fragmentacji parametrów i mieszania grupowego w obronie przed niegodnym zaufania serwerem w uczeniu federacyjnym
Dlaczego ochrona współdzielonych modeli ma znaczenie
Nasze telefony, szpitale i banki coraz częściej działają dzięki sztucznej inteligencji. Często wiele organizacji chciałoby wspólnie wytrenować model, ale prawo i zdrowy rozsądek mówią, że nie można scentralizować surowych danych w jednym miejscu. Uczenie federacyjne powstało, by rozwiązać ten konflikt: każdy uczestnik trenuje na własnym urządzeniu i udostępnia jedynie aktualizacje modelu. Jednak ta praca pokazuje, że nawet takie aktualizacje mogą wyciekać prywatne informacje, jeśli serwer centralny jest ciekawski lub nieuczciwy — i wprowadza nową metodę, która lepiej chroni zarówno nasze dane, jak i tożsamość.
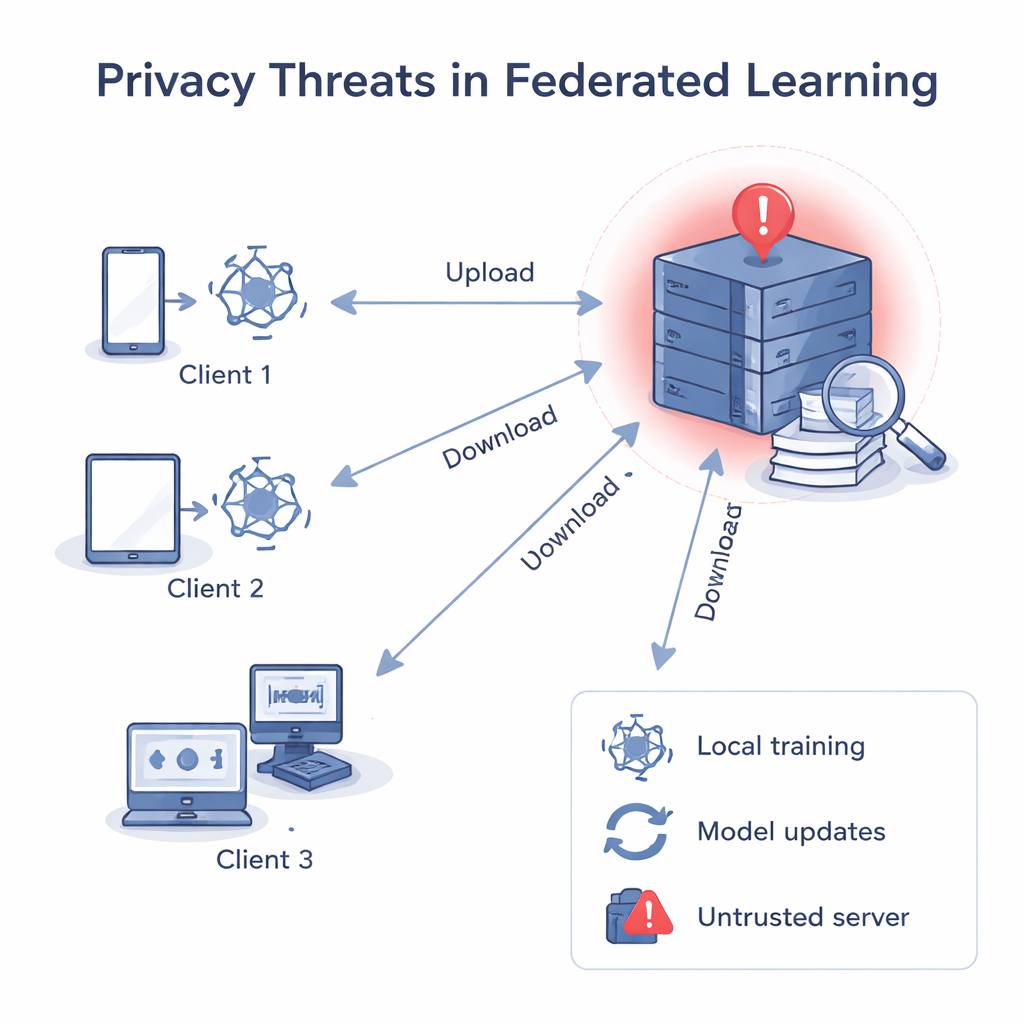
Kiedy serwer nie powinien być zaufany
W klasycznym uczeniu federacyjnym serwer centralny rozsyła wspólny model, każdy klient go ulepsza przy użyciu własnych danych, a następnie odsyła zaktualizowany model. Serwer uśrednia te aktualizacje, tworząc lepszy model globalny. Chociaż surowe dane nigdy nie opuszczają urządzeń, wcześniejsze badania wykazały, że gradienty i wagi — liczby wewnątrz modelu — można „odwrócić”, by zrekonstruować prywatne dane, takie jak obrazy czy tekst, albo ustalić, czy konkretny rekord brał udział w treningu. Jeśli serwer centralny jest niegodny zaufania, może analizować aktualizacje poszczególnych klientów osobno, dowiedzieć się o ich lokalnych danych, a nawet powiązać aktualizację z konkretną osobą lub organizacją.
Rozbijanie aktualizacji na nieszkodliwe kawałki
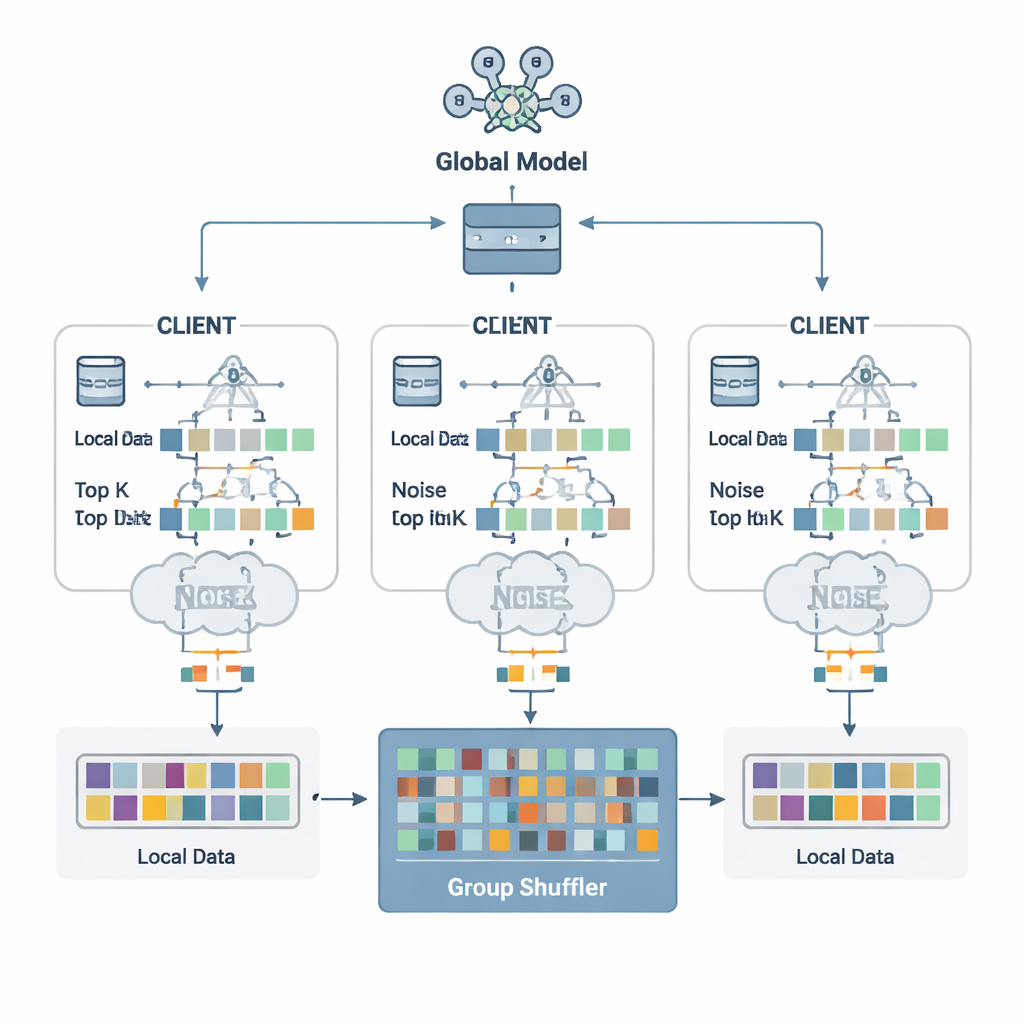
Autorzy proponują schemat obronny nazwany Security Defense based on Parameter Fragmentation Group Shuffling (SDPFGS). Jego pierwsza idea jest prosta, ale skuteczna: nigdy nie wysyłaj kompletnej aktualizacji. Zamiast tego każdy klient dzieli swoją aktualizację modelu na kilka sztucznych „fragmentów”. Większość z nich wypełniona jest losowymi liczbami, a tylko ostatni jest skorygowany tak, aby suma fragmentów równała się prawdziwej aktualizacji. Pojedynczy fragment, a nawet kilka z nich, wygląda jak szum i prawie nic nie ujawnia o danych źródłowych. Ten matematyczny trik przypomina dzielenie sekretu: tylko połączenie wszystkich części pozwala odzyskać całość.
Dodawanie szumu i mieszanie porcji
Wysyłanie wielu fragmentów nadal mogłoby być nieefektywne i, jeśli przeanalizowane razem, mogłoby pozwolić atakującemu na wnioskowanie więcej. Aby temu zapobiec, każdy klient wybiera tylko najważniejsze wartości fragmentów — Top‑K wpisów mających największe znaczenie dla uczenia — i dodaje do nich starannie skalowany losowy szum zgodny z zasadami różnicowej prywatności. Ten szum utrudnia statystyczne ustalenie, czy dane jednej osoby wpłynęły na konkretną wartość. Kolejny kluczowy składnik to mieszanie grupowe. Zamiast wysyłać fragmenty bezpośrednio do serwera, klienci przekazują je zaufanemu „mieszaczowi”, który miesza fragmenty od wielu klientów w grupy przed przesłaniem dalej. Po takim pomieszaniu serwer nie jest już w stanie powiedzieć, który fragment pochodzi od którego klienta, przerywając powiązanie między aktualizacjami a tożsamościami.
Utrzymywanie dokładności przy ograniczaniu wycieków
Zespół przetestował SDPFGS na standardowych benchmarkach obrazowych i tekstowych, w tym na ręcznie pisanych cyfrach (MNIST), zdjęciach odzieży (Fashion‑MNIST) oraz kolorowych obrazach (CIFAR‑10 i CIFAR‑100), a także na zadaniu klasyfikacji wiadomości. Porównali swoją metodę z kilkoma nowoczesnymi technikami prywatności opartymi wyłącznie na szumie, wyłącznie na mieszaniu lub na prostej kompresji gradientów. We wszystkich tych eksperymentach SDPFGS konsekwentnie dorównywał lub przewyższał dokładność metod konkurencyjnych, przy użyciu mniejszej komunikacji i krótszego czasu treningu niż wiele z nich. Co najważniejsze, przy atakach inwersji modelu — gdzie przeciwnik próbuje zrekonstruować przykłady treningowe — SDPFGS osiągnął najniższy wskaźnik powodzenia ataku, co oznacza najmniejsze wycieki informacji o danych.
Co to oznacza dla zwykłych użytkowników
Dla osoby niezwiązanej z tematem kluczowe przesłanie jest takie: «ukrywanie danych» to za mało; musimy też ukryć to, co nasze urządzenia wysyłają podczas treningu. SDPFGS robi to, zamieniając każdą aktualizację modelu w zaszumione, pomeszane fragmenty, które same w sobie są bezużyteczne, a jednocześnie mogą się złożyć w model globalny wysokiej jakości. Efekt to silniejsza ochrona przed ciekawskim lub przejętym serwerem, przy jedynie niewielkich kosztach dla dokładności i efektywności. W miarę jak uczenie federacyjne wkracza do opieki zdrowotnej, finansów i urządzeń smart, techniki takie jak SDPFGS mogą pomóc zapewnić, że ludzie będą korzystać z potężnych modeli współdzielonych, nie oddając przy tym kluczy do swojej prywatności.
Cytowanie: Guo, H., Chen, W., Li, J. et al. Combining parameter fragmentation and group shuffling to defend against the untrustworthy server in federated learning. Sci Rep 16, 5097 (2026). https://doi.org/10.1038/s41598-026-35420-w
Słowa kluczowe: uczenie federacyjne, prywatność danych, różnicowa prywatność, atak odwrotnej inwersji modelu, bezpieczna agregacja