Clear Sky Science · pl
Rozbieżność między oceną planów leczenia przez ludzi i systemy AI
Dlaczego ma to znaczenie dla codziennej opieki medycznej
W miarę jak narzędzia sztucznej inteligencji (AI) zaczynają pomagać lekarzom w wyborze terapii, pojawia się kluczowe pytanie: czyjej ocenie powinniśmy bardziej ufać — ludzkiej czy maszynowej? Badanie to analizuje prostą, lecz niepokojącą możliwość: lekarze i systemy AI mogą nie tylko nie zgadzać się co do tego, która terapia jest najlepsza, lecz także co uznają za „dobry” plan leczenia. Zrozumienie tej luki jest niezbędne, jeśli chcemy, by AI wspierała, a nie potajemnie zniekształcała decyzje medyczne podejmowane w praktyce.
Test bezpośredniego porównania porad terapeutycznych
Naukowcy skupili się na dermatologii, dziedzinie, w której lekarze zarządzają przewlekłymi schorzeniami skóry, rzadko mając jedną „prawidłową” odpowiedź. Dziesięciu doświadczonych dermatologów oraz dwa duże modele językowe (LLM) — model ogólnego zastosowania i model nastawiony na rozumowanie — zostało poproszonych o opracowanie planów leczenia dla pięciu trudnych, fikcyjnych przypadków, np. ciężkiego wyprysku, łuszczycy z chorobami współistniejącymi i trądziku w ciąży. Dla zachowania uczciwości wszystkie 60 planów zostało zredagowanych do wspólnego formatu: podobnej długości, struktury i tonu. Usunięto wszelkie oczywiste wskazówki sugerujące, czy plan napisał człowiek czy AI, aby późniejsi sędziowie oceniali zawartość, a nie styl.
Jak oceniali ludzie i AI
Następnie plany przeszły dwie rundy ślepego punktowania przy użyciu tej samej rubryki. Najpierw ta sama grupa dziesięciu dermatologów oceniła każdy plan pod względem ogólnej jakości w skali 0–10, biorąc pod uwagę skuteczność, bezpieczeństwo, wykonalność i ukierunkowanie na pacjenta. Potem oddzielny model AI — użyty wyłącznie jako sędzia, nie jako autor planów — oceniał dokładnie te same plany według tych samych instrukcji. Co kluczowe, ani ludzcy recenzenci, ani sędzia-AI nie wiedzieli, kto napisał dany plan. Takie ustawienie pozwoliło autorom wyizolować jeden istotny czynnik: to, czy oceniający jest człowiekiem, czy AI.
Ludzie faworyzują ludzi, AI faworyzuje AI
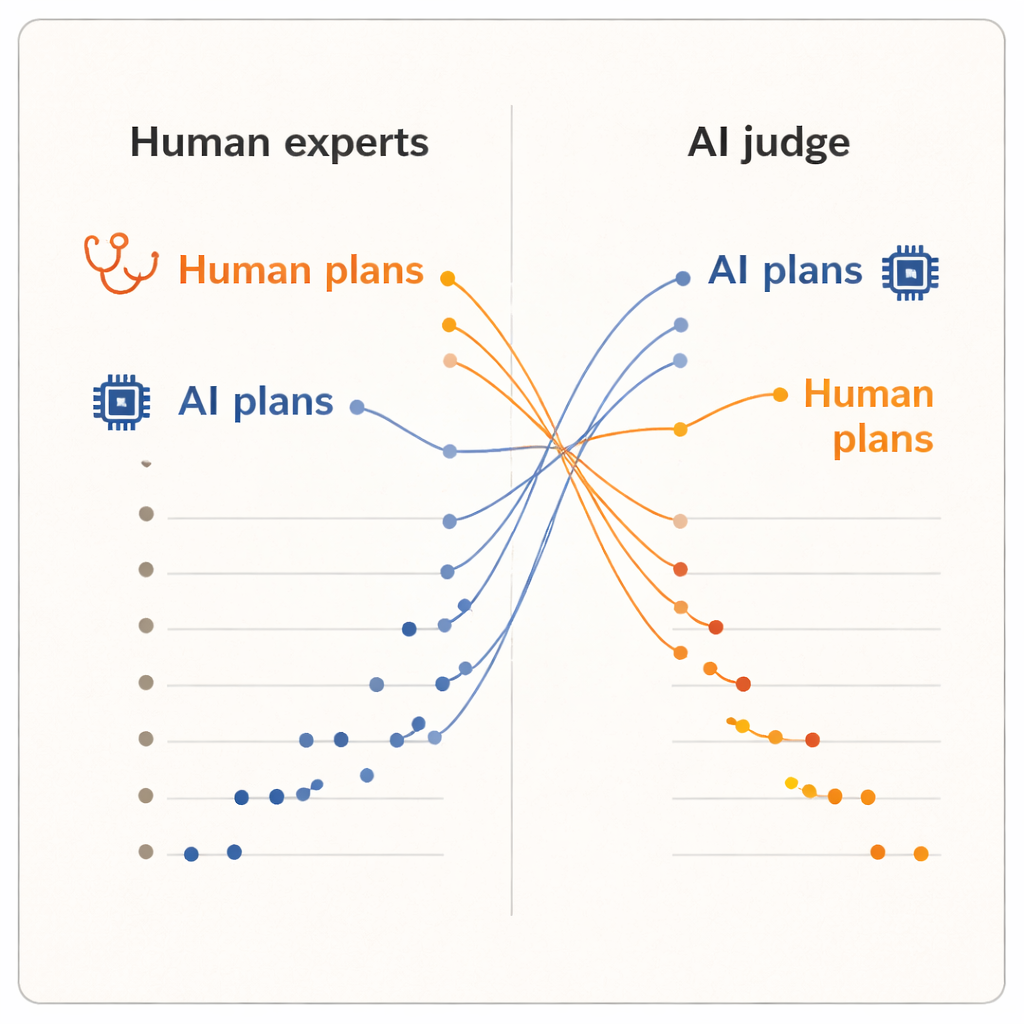
Wyniki wykazały wyraźny „efekt oceniającego”. Gdy plany oceniali ludzie, wyżej punktowali oni te napisane przez kolegów dermatologów niż te przygotowane przez którykolwiek system AI. Plany stworzone przez ludzi miały nieco wyższą średnią ocenę i zajęły pięć najwyższych pozycji w rankingu. Jeden z modeli AI, zaawansowany system rozumujący, znalazł się w dolnych partiach listy. Jednak gdy sędziowanie przejął model AI, obraz odwrócił się. Dwa plany wygenerowane przez AI wskoczyły na szczyt rankingu, a wszystkie plany ludzkich dermatologów znalazły się poniżej nich. Średnio sędzia-AI oceniał plany AI wyżej niż plany ludzkie, mimo że czytał dokładnie te same, wystandaryzowane teksty, które widzieli dermatolodzy.
Różne pojęcia „dobrego” planu
Ponieważ plany zostały znormalizowane pod względem sformułowań, a sędziowie nie znali źródła, autorzy twierdzą, że tego podziału nie da się wyjaśnić powierzchowną poprawnością stylu. Zamiast tego sugeruje on, że ludzie i systemy AI operują różnymi wewnętrznymi miarami oceny. Klinicyści prawdopodobnie opierają się na doświadczeniu z praktyki: co zwykle jest wykonalne w ich warunkach, jak pacjenci reagują i które kompromisy są akceptowalne w praktyce. Natomiast sędzia-AI trenowany na dużych zbiorach tekstów może faworyzować plany zgodne ze wzorcami powszechnymi w literaturze medycznej lub wytycznych, nawet jeśli te wzorce nie oddają w pełni lokalnych ograniczeń czy preferencji pacjentów. Badanie ma skromną skalę — tylko dziesięciu klinicystów, pięć przypadków i jeden sędzia-AI — i mierzy postrzeganą jakość, a nie rzeczywiste wyniki pacjentów. Mimo to odwrócenie preferencji jest na tyle wyraźne, że rodzi głębsze pytania o to, jak oceniamy kliniczne systemy AI.
Ponowne przemyślenie testów i zastosowań klinicznej AI
Z tych wyników autorzy wyciągają dwa szerokie wnioski. Po pierwsze, tradycyjne testy typu „jedyna poprawna odpowiedź” dla medycznej AI pomijają wiele istotnych aspektów opieki rzeczywistej, gdzie plany muszą godzić skuteczność, bezpieczeństwo, koszty, logistykę i życzenia pacjenta. Postulują bogatsze, wielomeryczne ramy oceny, które jawnie punktują te wymiary, wykorzystują wielu sędziów — zarówno ludzkich, jak i AI — oraz analizują, gdzie i dlaczego pojawiają się rozbieżności, zamiast sprowadzać wszystko do jednej oceny. Po drugie, sugerują, że różnice między ocenami ludzkimi i AI mogą być cechą, a nie tylko wadą. Jeśli stosować AI ostrożnie, plany generowane przez systemy mogą służyć jako przemyślana druga opinia, która skłania lekarzy do ponownego rozważenia własnych założeń, podczas gdy lekarze dostarczają kontekst praktyczny i osąd etyczny, którego AI nie ma. Budowanie godnych zaufania, przejrzystych interfejsów ujawniających założenia, pozwalających klinicystom dostosowywać priorytety i zachęcających do krytycznej weryfikacji mogłoby pomóc przekształcić to napięcie między perspektywami człowieka i AI w bezpieczniejsze, bardziej zrównoważone podejmowanie decyzji.
Cytowanie: Sengupta, D., Panda, S. Disagreement between human and AI evaluation of treatment plans. Sci Rep 16, 4798 (2026). https://doi.org/10.1038/s41598-026-35406-8
Słowa kluczowe: wsparcie decyzji klinicznych, sztuczna inteligencja w medycynie, współpraca człowiek-AI, planowanie leczenia, stronniczość oceny