Clear Sky Science · pl
Hybrydowy model prognozowania stężenia PM2.5 oparty na wysokoczęstotliwościowych i niskoczęstotliwościowych IMF po dekompozycji EMD
Dlaczego dokładniejsze prognozy jakości powietrza mają znaczenie w codziennym życiu
Drobne cząstki w powietrzu, znane jako PM2.5, są na tyle małe, że mogą docierać głęboko do płuc, a nawet przenikać do krwiobiegu. W północnych Chinach, gdzie skoncentrowane są ciężki przemysł i ogrzewanie zimowe, te cząstki często osiągają poziomy wywołujące ostrzeżenia zdrowotne, zakłócające ruch i czasem powodujące zamknięcie fabryk oraz szkół. Badanie stawia praktyczne pytanie: czy można dokładniej przewidywać godzina po godzinie poziomy PM2.5, tak aby miasta i mieszkańcy otrzymywali wcześniejsze i bardziej wiarygodne ostrzeżenia zanim powietrze stanie się niebezpieczne?
Przyjrzenie się zanieczyszczonemu powietrzu w północnych Chinach
Naukowcy skupili się na sześciu głównych miastach w północnych Chinach: Pekinie, Tianjinie, Shijiazhuangu, Taiyuanie, Jinan i Zhengzhou. Miasta te reprezentują gęsto zaludnione, uprzemysłowione obszary, gdzie epizody zanieczyszczeń są częste, zwłaszcza zimą. Korzystając z oficjalnych danych pomiarowych, zespół zebrał godzinne odczyty PM2.5 za cały rok 2021, uzyskując po 8 760 punktów danych dla każdego miasta. Stwierdzono, że poziomy zanieczyszczeń znacznie różniły się między miastami; na przykład Taiyuan miał najwyższe średnie stężenie PM2.5, podczas gdy Pekin najniższe. Ekstremalne zdarzenia były uderzające: w Taiyuanie stężenia wzrosły do 652 mikrogramów na metr sześcienny podczas marcowego epizodu pyłowego i zanieczyszczeniowego, doprowadzając indeks jakości powietrza do maksymalnego poziomu — wyraźny znak silnego zanieczyszczenia powietrza.
Dlaczego przewidywanie PM2.5 jest tak trudne
Poziomy PM2.5 są kształtowane przez wiele sił jednocześnie — lokalne emisje z ruchu i zakładów, regionalny transport pyłu i dymu, prędkość wiatru, wilgotność i inne czynniki. W rezultacie zapis zanieczyszczeń zachowuje się mniej jak gładka krzywa, a bardziej jak poszarpane, niestabilne tętno. Tradycyjne narzędzia statystyczne czy nawet nowoczesne sieci neuronowe mogą mieć trudności z takimi danymi: mogą uchwycić ogólny trend, ale przegapić nagłe skoki, albo działać dobrze w jednym mieście, a zawodzić w innym. Wcześniejsze badania próbowały poprawić prognozy albo przez dodanie bardziej fizycznych szczegółów (takich jak modele transportu chemicznego), albo opierając się wyłącznie na zaawansowanych metodach uczenia maszynowego. Niniejszy artykuł łączy kilka podejść, z których każde dobrano do obsługi innego „rytmu” zawartego w danych.
Rozdzielenie sygnału na szybkie i wolne rytmy
Kluczowym krokiem jest technika zwana empiryczną dekompozycją modów (EMD), która rozbija oryginalny szereg czasowy PM2.5 na kilka prostszych składowych. Niektóre z tych składowych falują szybko i wychwytują krótkoterminowe skoki oraz szum; inne zmieniają się wolniej i odzwierciedlają podstawowy trend. Autorzy sklasyfikowali pierwsze pięć składowych jako części „wysokoczęstotliwościowe”, a pozostałe wraz z resztą trendu jako „niskoczęstotliwościowe”. Składniki wysokoczęstotliwościowe, które są bardziej nieregularne i wysoce nieliniowe, podawane są do sieci typu long short‑term memory (LSTM) — rodzaju modelu głębokiego uczenia dobrze nadającego się do uczenia zależności w czasie. Gładsze, niskoczęstotliwościowe komponenty są przekazywane do klasycznej metody szeregów czasowych znanej jako ARIMA, skutecznej gdy dane zachowują się w bardziej regularny, niemal liniowy sposób.
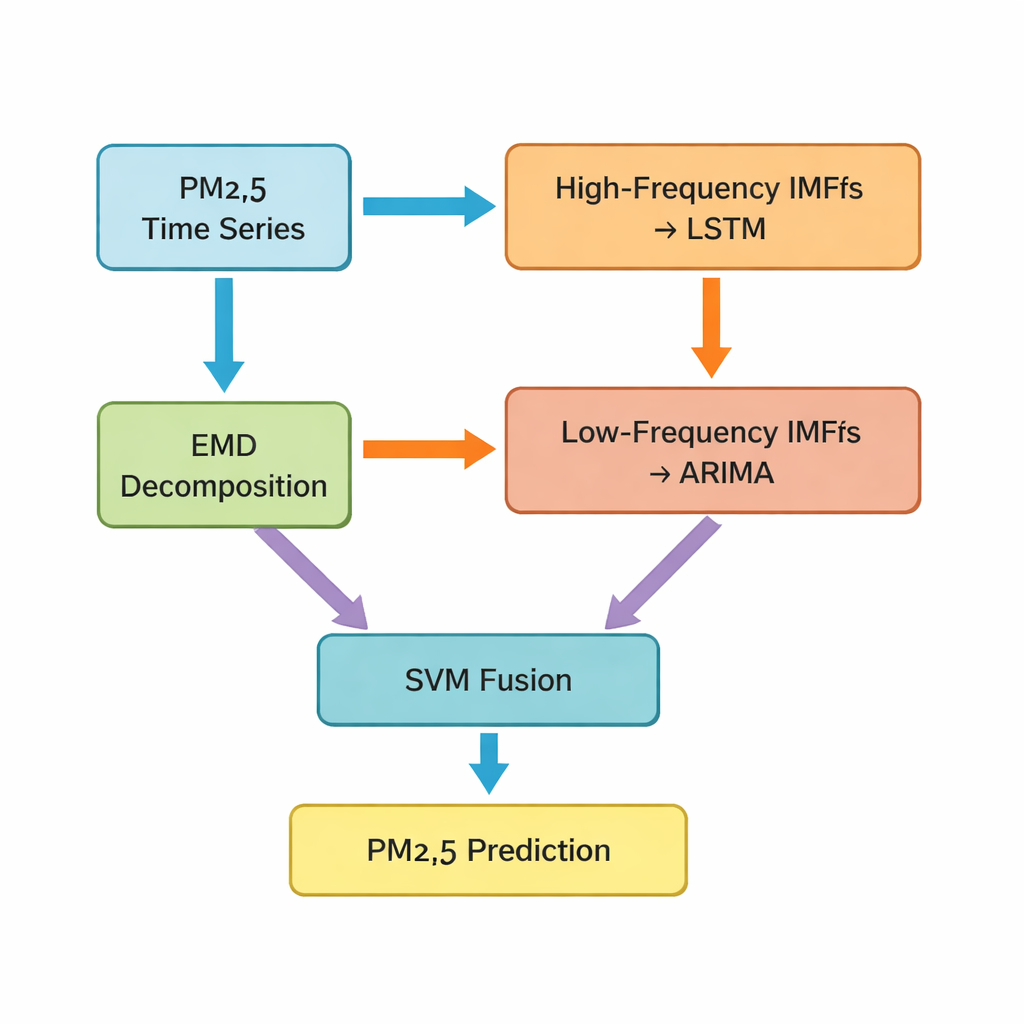
Łączenie różnych modeli w jedną inteligentniejszą prognozę
Gdy modele LSTM i ARIMA wygenerują swoje częściowe prognozy, pojawia się wyzwanie: jak połączyć te oddzielne przewidywania w jedną końcową, najlepszą ocenę stężenia PM2.5 na kolejną godzinę. Do tego autorzy używają maszyny wektorów nośnych (SVM), kolejnej metody uczenia maszynowego, która uczy się, jak ważone są i łączone dwa wejścia. W istocie SVM działa jak sędzia, decydując, kiedy bardziej liczy się „szybkie” spojrzenie na świat (wzorce wysokoczęstotliwościowe), a kiedy dominować powinien „wolny” obraz (długoterminowe trendy). Połączony system, który autorzy nazywają Hybrid‑EMDHL, jest następnie oceniany przy użyciu kilku wskaźników wydajności, w tym średniego błędu, jak blisko prognozy odpowiadają obserwowanym wartościom oraz jak dobrze model przewiduje kierunek zmiany — czy poziomy rosną czy maleją.
Bardziej czytelne ostrzeżenia i lepsze planowanie
Model hybrydowy przewyższa każdy ze swoich głównych komponentów stosowanych osobno we wszystkich sześciu miastach. Nie tylko zmniejsza średnie i kwadratowe błędy, ale też znacząco poprawia zdolność do poprawnego przewidywania, czy PM2.5 wzrośnie czy spadnie w następnej godzinie — kluczowa cecha dla wydawania terminowych ostrzeżeń zdrowotnych. W wielu przypadkach podejście hybrydowe redukuje miary błędu o ponad połowę w porównaniu z pojedynczym modelem sieci neuronowej, a jego „dokładność kierunku” przekracza 0,69, co oznacza, że w zdecydowanej większości testów poprawnie przewiduje trend. Dla przeciętnego odbiorcy oznacza to prognozy jakości powietrza w stylu pogodowym, które są ostrzejsze i bardziej wiarygodne. Dla planistów miejskich i władz zdrowotnych oferuje praktyczne narzędzie wspierające ukierunkowane, wczesne działania — takie jak dostosowanie działalności przemysłowej czy kontroli ruchu — zanim epizod zanieczyszczenia osiągnie szczyt, pomagając zmniejszyć narażenie i chronić codzienne życie w niektórych z najbardziej zanieczyszczonych regionów miejskich Chin.
Cytowanie: Wang, P., Wu, Q. & Zhang, G. A hybrid prediction model for PM2.5 concentration based on high-frequency and low-frequency IMFs with EMD decomposition. Sci Rep 16, 4969 (2026). https://doi.org/10.1038/s41598-026-35386-9
Słowa kluczowe: prognozowanie PM2.5, zanieczyszczenie powietrza, Północne Chiny, uczenie maszynowe, dekompozycja szeregów czasowych