Clear Sky Science · pl
QPSODRL: ulepszona kwantowo‑zainspirowana optymalizacja rojem cząstek i głębokie uczenie ze wzmocnieniem — inteligentny protokół grupowania i trasowania dla bezprzewodowych sieci czujnikowych
Inteligentniejsze sieci czujników dla połączonego świata
Od precyzyjnego rolnictwa po systemy wczesnego ostrzegania przed katastrofami — bezprzewodowe sieci czujnikowe dyskretnie monitorują otoczenie, zbierając dane z setek lub tysięcy maleńkich urządzeń rozmieszczonych na dużych obszarach. Ich największa słabość jest też cechą charakterystyczną: każdy czujnik zasilany jest z małej baterii, którą trudno lub niemożliwe jest wymienić. Artykuł przedstawia nowy sposób organizacji i kierowania przepływem danych w takich sieciach, tak aby baterie działały dłużej, informacje trafiały bardziej niezawodnie, a sieć adaptowała się, gdy zmieniają się warunki.
Dlaczego małe urządzenia potrzebują dużej inteligencji
W bezprzewodowej sieci czujnikowej każdy węzeł może mierzyć, przetwarzać i komunikować, ale energia jest cenna. Jeśli niektóre węzły wykonują zbyt dużo pracy, szybko się wyczerpują, tworząc „martwe strefy”, w których nie można zbierać danych. Aby temu zapobiec, projektanci zwykle grupują węzły w klastry. W obrębie każdego klastra jeden węzeł staje się jego głową: zbiera odczyty od sąsiadów i przesyła je w kierunku stacji bazowej. Wybór głów klastra i sposobu, w jaki dane przeskakują przez sieć, to złożona układanka, która zmienia się wraz z zużyciem baterii. Tradycyjne regułowe rozwiązania lub metody oparte na jednym algorytmie często zbyt szybko przyjmują suboptymalne wzorce albo zawodzą, gdy kształt sieci i poziomy energii ewoluują w czasie.
Połączenie roju inspirowanego kwantowo z maszynami uczącymi
W badaniu wprowadzono QPSODRL — protokół łączący dwie potężne idee: metodę roju inspirowaną mechaniką kwantową do formowania klastrów oraz silnik głębokiego uczenia ze wzmocnieniem do trasowania. W pierwszym etapie wirtualne „cząstki” eksplorują różne sposoby przydzielania głów i członków klastrów. Ich zachowanie kierowane jest miarą równomierności rozkładu energii w sieci, zwaną entropią. Gdy zużycie energii jest nierównomierne, algorytm zachęca do szerokiej eksploracji nowych układów klastrów; gdy sytuacja stabilizuje się, dopracowuje obiecujące rozkłady. Specjalny etap „elitarnego zaburzenia” okazjonalnie popycha najlepsze kandydatury w nowe kierunki, pomagając uciec od lokalnych pułapek i uniknąć nadmiernego wykorzystywania tych samych węzłów o wysokim poziomie energii. 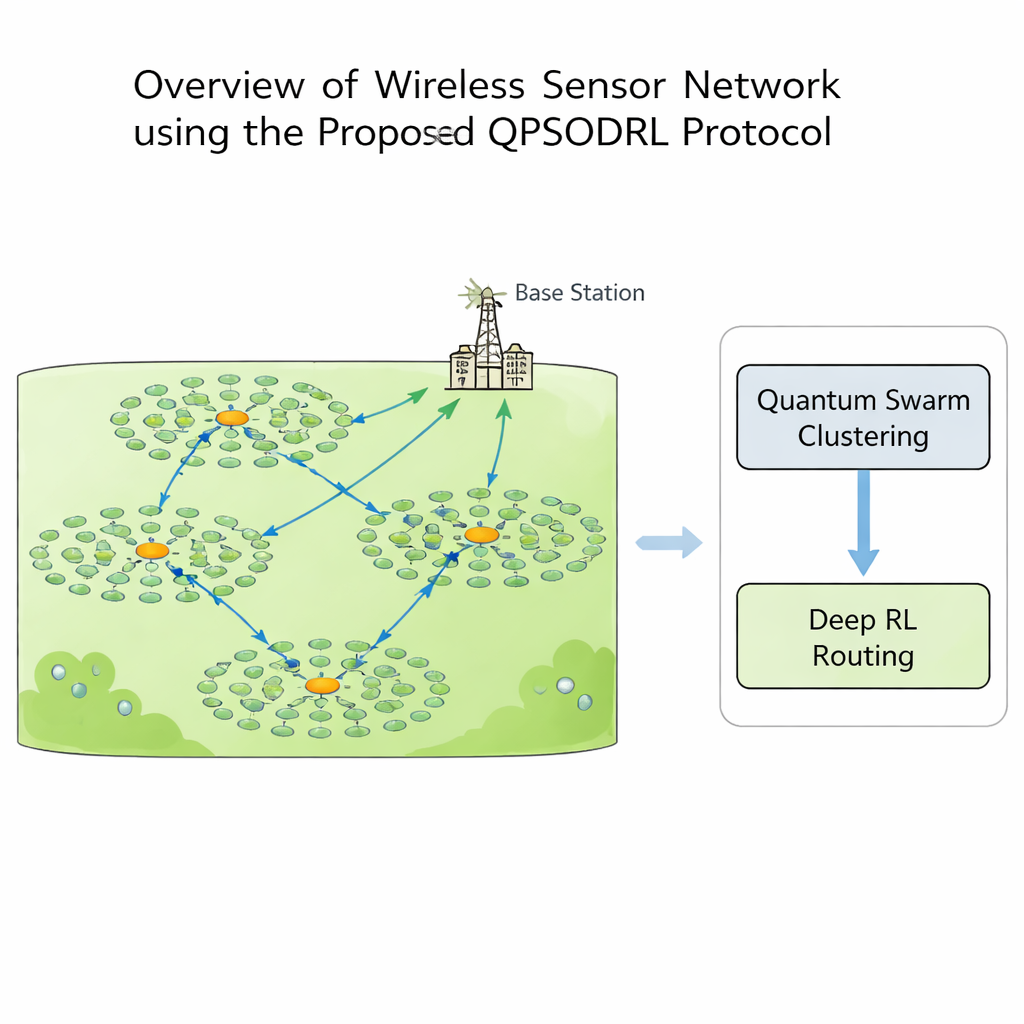
Nauczanie sieci lepszego wyboru tras
Gdy klastry są utworzone, drugi etap decyduje, jak każda głowa klastra powinna wysyłać swoje dane do stacji bazowej. Zamiast trzymać się stałych tras, QPSODRL traktuje każdą głowę klastra jako agenta w procesie uczącym. W każdym kroku agent obserwuje swoją pozostałą energię, energię i odległość sąsiednich głów oraz oszacowane opóźnienia, a następnie wybiera kolejny skok. Specjalna forma głębokiego uczenia Q, zwana Dueling Double Deep Q‑Network, ocenia, jak dobre są poszczególne wybory w dłuższej perspektywie. Autorzy dodają człon „entropii”, by zniechęcić system do zbyt szybkiego nadmiernego przekonania, co pomaga utrzymać eksplorację alternatywnych tras. Zaprojektowano też ulepszony mechanizm odtwarzania doświadczeń (experience replay), który celowo koncentruje naukę na najbardziej informatywnych sytuacjach — np. gdy energia jest niska lub opóźnienia gwałtownie rosną — dzięki czemu model szybciej poprawia się w najważniejszych scenariuszach. 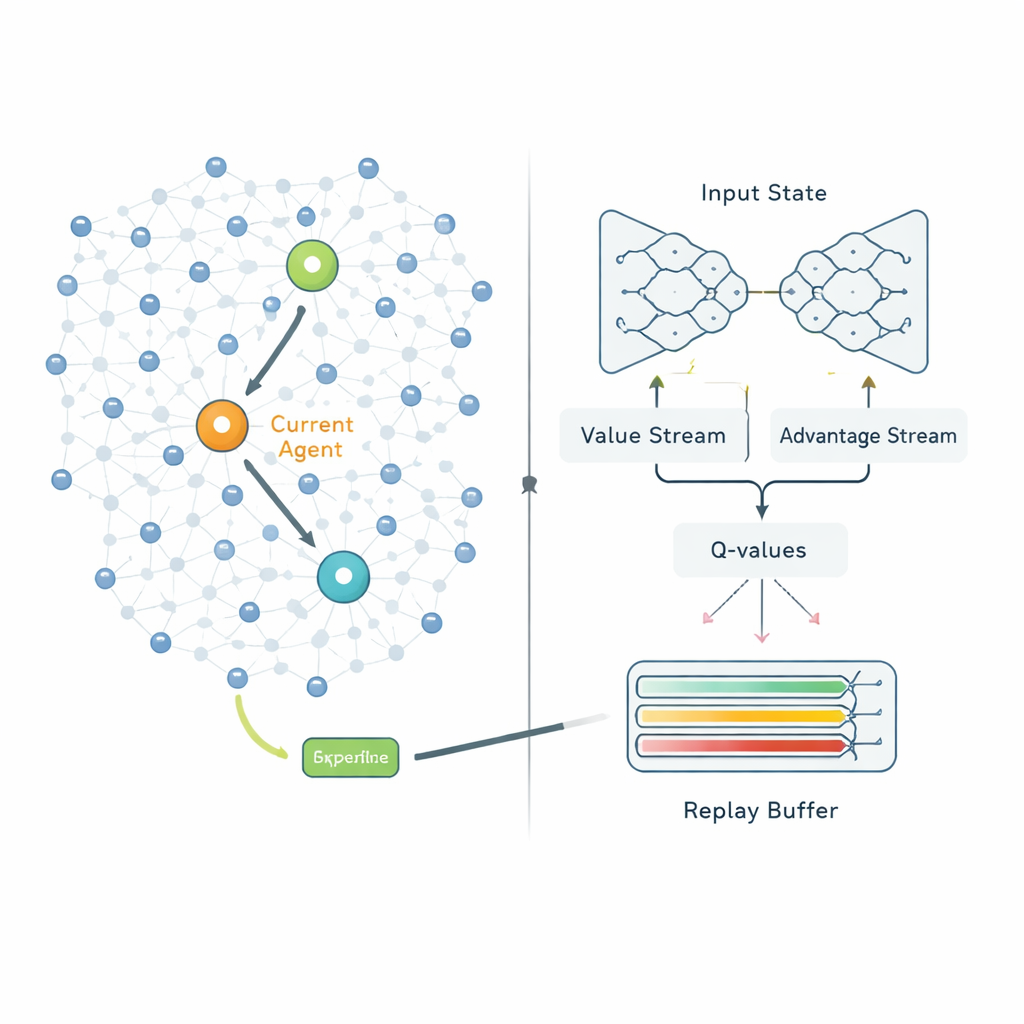
Próba w warunkach symulowanych
Aby ocenić działanie QPSODRL, autor przeprowadza szczegółowe symulacje komputerowe sieci z 100 i 200 węzłami rozmieszczonymi na obszarach o różnych rozmiarach i z różnym odsetkiem węzłów pełniących rolę głów klastrów. Nowy protokół porównano z czterema nowoczesnymi konkurentami wykorzystującymi m.in. roje cząstek, optymalizację wielorybów, logikę rozmytą oraz inne hybrydowe i oparte na uczeniu schematy. We wszystkich testowanych konfiguracjach QPSODRL utrzymuje sieć przy życiu przez więcej rund komunikacyjnych, dostarcza więcej pakietów do stacji bazowej i zużywa mniej całkowitej energii. Również bardziej równomiernie rozkłada obciążenie między głowami klastrów, co widoczne jest jako mniejsza zmienność ruchu obsługiwanego przez poszczególne głowy. Zyski te są szczególnie widoczne w trudniejszych układach, gdy stacja bazowa znajduje się na krawędzi pola, zmuszając niektóre węzły do dłuższych skoków.
Co to oznacza dla systemów w świecie realnym
Dla osób niebędących specjalistami kluczowy przekaz jest taki: wyposażenie sieci czujnikowych w możliwości zarówno globalnej optymalizacji ich struktury, jak i lokalnego uczenia na podstawie doświadczeń może znacząco wydłużyć ich użyteczność. Kwantowo‑zainspirowane grupowanie QPSODRL utrzymuje zrównoważone użycie energii, podczas gdy trasowanie oparte na głębokim uczeniu adaptuje się do zmieniających się warunków bez stałej ręcznej regulacji. Chociaż wyniki oparto na symulacjach z nieruchomymi, stałymi węzłami, sugerują one, że przyszłe instalacje czujników — od inteligentnych miast po obserwatoria środowiskowe — mogłyby działać dłużej, rzadziej zawodzić i lepiej wykorzystywać ograniczoną energię bateryjną, przyjmując podobne inteligentne strategie sterowania.
Cytowanie: Guangjie, L. QPSODRL: an improved quantum particle swarm optimization and deep reinforcement learning based intelligent clustering and routing protocol for wireless sensor networks. Sci Rep 16, 5526 (2026). https://doi.org/10.1038/s41598-026-35365-0
Słowa kluczowe: bezprzewodowe sieci czujnikowe, energooszczędne trasowanie, głębokie uczenie ze wzmocnieniem, optymalizacja rojem, grupowanie sieci