Clear Sky Science · pl
Integracja wiedzy dla fizycznie poinformowanej regresji symbolicznej z wykorzystaniem uprzednio wytrenowanych dużych modeli językowych
Nauczanie komputerów zgadywania wzorów natury
Wiele wielkich idei w nauce zapisuje się jako zgrabne równania: od tego, jak spada piłka, po to, jak fale świetlne rozchodzą się w przestrzeni. Ten artykuł bada nowy sposób, by pomóc komputerom automatycznie odtwarzać takie równania z surowych danych, pozwalając im konsultować się z dużym modelem językowym — tym samym rodzajem sztucznej inteligencji, który zasila nowoczesne chatboty — tak aby ich przypuszczenia były nie tylko dokładne, lecz także zgodne z fizyką.
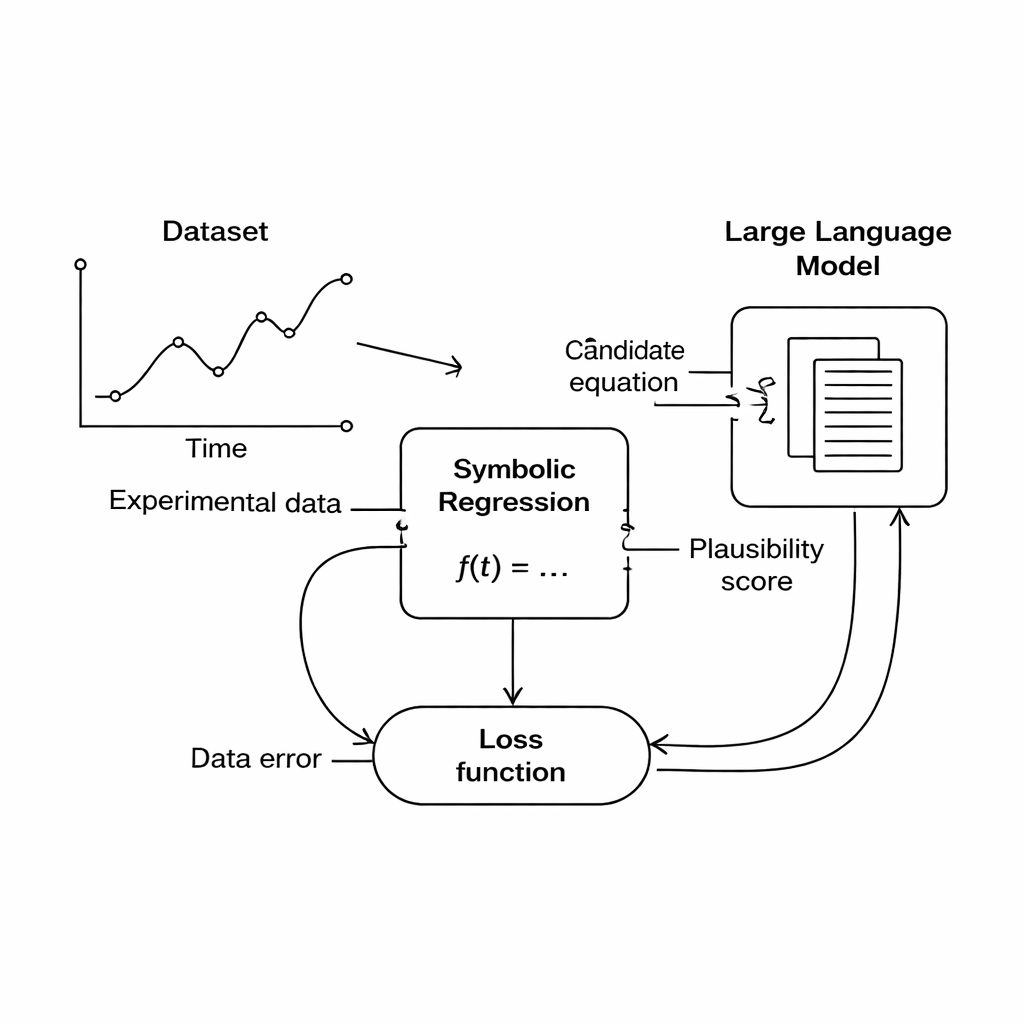
Z surowych danych do czytelnych dla człowieka praw
Autorzy koncentrują się na technice zwanej regresją symboliczną, która poszukuje wzoru matematycznego łączącego zmierzone wejścia i wyjścia. W przeciwieństwie do zwykłego dopasowywania krzywych, regresja symboliczna nie zaczyna od ustalonego kształtu funkcji; zamiast tego buduje i ewoluuje kandydackie równania, aż któreś dobrze dopasuje się do danych. To czyni ją obiecującym narzędziem do odkryć naukowych, ponieważ może potencjalnie ujawnić nowe relacje, których nikt wcześniej nie zapisał. Jest jednak haczyk: równanie idealnie dopasowujące dane wciąż może być nonsensowne z punktu widzenia fizyki — na przykład poprzez dodanie długości do czasu lub wygenerowanie jednostek, które nie odpowiadają żadnej realnej wielkości.
Dlaczego wgląd fizyczny nadal ma znaczenie
Aby uniknąć takich absurdów, badacze opracowali „fizycznie poinformowane” wersje regresji symbolicznej, które wplatają znane reguły natury w proces poszukiwania. Metody te nagradzają równania, które na przykład zachowują energię lub respektują zgodność jednostek. Jednak kodowanie tej wiedzy zwykle wymaga ekspertów tworzących na miarę ograniczenia i specjalne funkcje straty dla każdego nowego problemu. To czyni podejście potężnym, ale trudnym do uogólnienia. Każdy nowy układ fizyczny może wymagać własnej starannej pracy projektowej, ograniczając dostępność tych narzędzi dla osób niebędących specjalistami.
Pozwól modelom językowym oceniać równania
W tym badaniu proponuje się inną drogę: zamiast twardo kodować reguły dziedziny, użyć dużego modelu językowego (LLM) jako elastycznego sędziego wiarygodności naukowej. Podczas przeszukiwania silnik regresji symbolicznej generuje kandydackie równania, które częściowo dopasowują się do danych. Każde równanie tłumaczy się na tekst i wysyła do LLM-a wraz z krótkim podpowiedzią opisującą analizowane wielkości i znane ograniczenia fizyczne. LLM zwraca oceny w trzech aspektach: czy jednostki w równaniu mają sens, jak proste jest równanie oraz czy wydaje się fizycznie realistyczne. Oceny te są włączane do głównej funkcji celu, więc komputer równoważy teraz „dopasowanie do danych” z „wygląda jak dobra fizyka” przy wyborze równań do dalszej optymalizacji.
Przetestowanie metody
Aby sprawdzić skuteczność podejścia, autorzy przeprowadzili obszerne eksperymenty komputerowe na trzech klasycznych problemach: swobodnym spadku piłki w polu grawitacyjnym Ziemi, prostych drganiach harmonicznych masy na sprężynie oraz tłumionej fali elektromagnetycznej. Dla każdego układu zasymulowali tysiące zaszumionych pomiarów w różnych warunkach, a następnie poprosili trzy popularne programy do regresji symbolicznej o odtworzenie równań, z pomocą LLM-a albo bez niej. Wypróbowali trzy zwarte, otwartoźródłowe modele językowe — Mistral, Llama 2 i Falcon — oraz badali, jak różne projekty promptów, od minimalnego kontekstu po pełne opisy, a nawet prawdziwe wzory, wpływają na wskazówki LLM-a. W większości ustawień dodanie oceny z LLM poprawiało zgodność odzyskanych równań z znanymi prawami i zwiększało ich odporność na szum, przy czym kombinacja PySR (biblioteka regresji symbolicznej) i Mistral zwykle wypadała najlepiej.
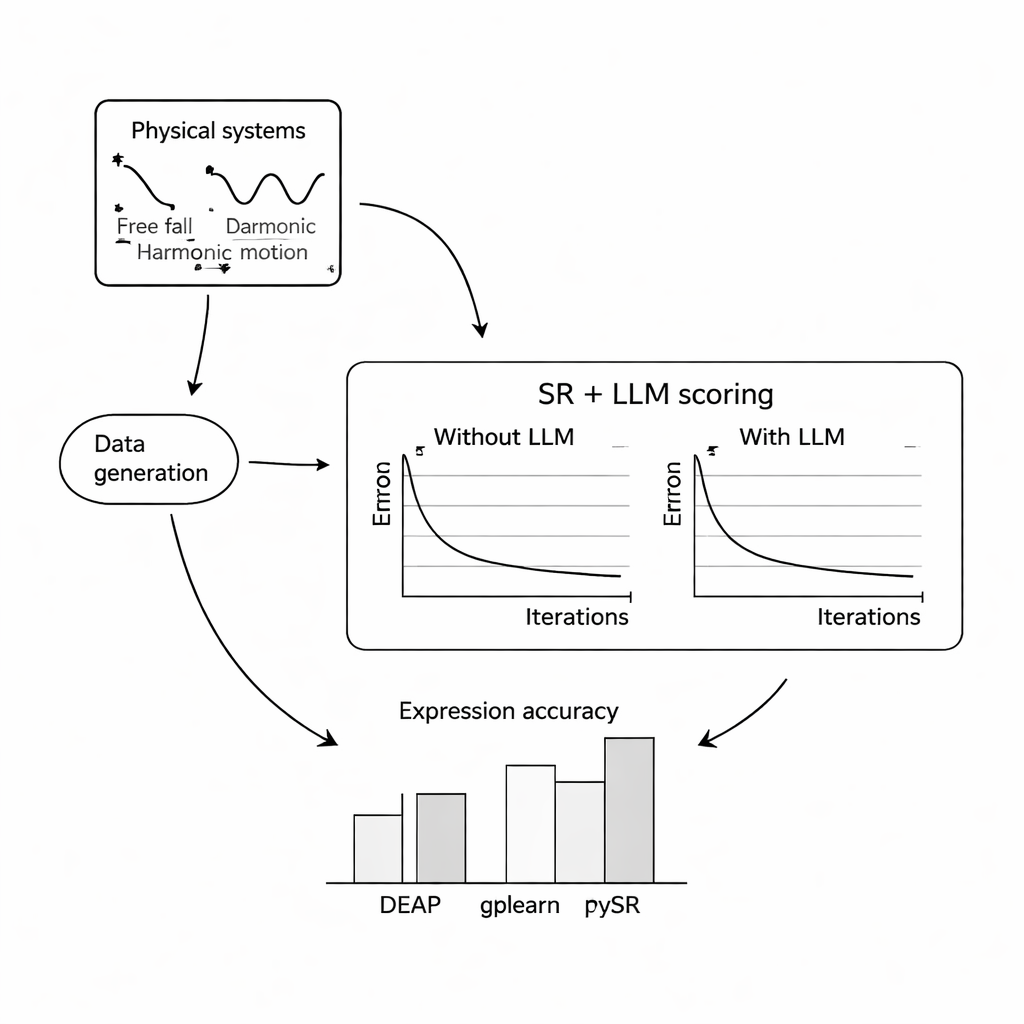
Kiedy słowa kierują matematyką
Kluczowym wnioskiem jest to, że sformułowanie promptu silnie wpływa na wyniki. Gdy prompty zawierały jasne opisy zmiennych, charakter eksperymentu, a czasem dokładny wzór docelowy, przeszukiwanie z pomocą LLM-a bardziej niezawodnie zbiegało do poprawnej struktury. W tych bogatszych przypadkach odkryte równania często były strukturalnie identyczne z prawami weryfikacyjnymi, a nie tylko numerycznie bliskie. Autorzy przetestowali też, jak podejście radzi sobie przy rosnącym poziomie losowego szumu pomiarowego. Chociaż wszystkie metody pogarszały się wraz ze wzrostem szumu i złożoności równań, wersje uzupełnione o LLM zwykle traciły dokładność wolniej niż ich standardowe odpowiedniki, co sugeruje, że wyczucie prawdopodobieństwa LLM-a może działać jako czynnik stabilizujący.
Co to oznacza dla przyszłych odkryć
Dla czytelników ogólnych główny przekaz jest taki, że AI operująca na tekście może robić więcej niż pisać eseje czy odpowiadać na pytania — może także prowadzić inne algorytmy ku równaniom naukowym, które „wyglądają właściwie” zgodnie z naszą obecną wiedzą o naturze. Przedstawiona metoda nie gwarantuje, że każde odkryte równanie jest poprawne i nadal wymaga nadzoru ludzkiego oraz starannie przygotowanych promptów. Pokazuje jednak, że duże modele językowe, wytrenowane na oceanach tekstów naukowych, mogą służyć jako wielokrotnego użytku źródło wiedzy dziedzinowej, pomagając zautomatyzowanym narzędziom przejść od ślepego dopasowywania danych do proponowania praw, które naukowcy mogą interpretować, weryfikować i rozwijać.
Cytowanie: Taskin, B., Xie, W. & Lazebnik, T. Knowledge integration for physics-informed symbolic regression using pre-trained large language models. Sci Rep 16, 1614 (2026). https://doi.org/10.1038/s41598-026-35327-6
Słowa kluczowe: regresja symboliczna, AI uwzględniające fizykę, duże modele językowe, odkrywanie naukowe, uczenie równań