Clear Sky Science · pl
Podejście głębokiego uczenia ze wzmocnieniem do analizy ruchu tanecznego
Nauczanie komputerów oglądania tańca tak jak my
Od baletu po hip-hop, taniec pełen jest subtelnych zmian rytmu i pozy, które ludzkie oko wychwytuje natychmiast — ale komputery mają z tym trudność. W tym badaniu wprowadzono nowy sposób, dzięki któremu sztuczna inteligencja może „oglądać” filmy taneczne bardziej jak ekspert, przeskakując rutynowe sekwencje, aby skupić się na krótkich, wymownych momentach definiujących dany styl. Efekt to system rozpoznający gatunki tańca dokładniej, oglądając przy tym znacznie mniej materiału wideo — potencjalny impuls dla cyfrowych archiwów, technologii sportowej i rozrywkowej.
Dlaczego filmy taneczne są trudne dla maszyn
Pozornie wyszkolenie komputera do rozpoznawania stylów tanecznych wydaje się proste: wprowadź filmy i pozwól głębokiemu uczeniu znaleźć wzorce. W rzeczywistości większość istniejących systemów marnuje wysiłek. Standardowe modele wideo albo przetwarzają każdą klatkę, albo pobierają próbki w stałych odstępach, zakładając, że wszystkie momenty są jednakowo istotne. Tymczasem style taneczne często różnią się w drobnych szczegółach — jak skręt stopy, moment obrotu partnera czy timing piruetu — a nie w ciągłym ruchu. Oznacza to, że wiele klatek jest powtarzalnych lub nieinformacyjnych, a kluczowe pozy mogą wypaść pomiędzy stałymi punktami próbkowania, co prowadzi do pomyłek, na przykład między walcem a foxtrotem.
Sprytniejszy sposób przeglądania wideo
Naukowcy proponują ramy nazwane Reinforcement-based Attentive Temporal Sampling, w skrócie RATS, które traktują analizę wideo jako aktywne poszukiwanie zamiast biernego oglądania. Zamiast iść klatka po klatce, system dzieli film taneczny na krótkie klipy i najpierw zamienia każdy klip w zwięzły opis ruchu przy użyciu wyspecjalizowanej trójwymiarowej sieci konwolucyjnej. Te streszczenia ruchu są następnie przechowywane w pamięci. Na tej bazie agent podejmujący decyzje przechodzi przez sekwencję klipów, wybierając, czy przesunąć się małym skokiem, większym przeskokiem, czy zatrzymać się i wydać przewidywanie stylu. W efekcie system uczy się, jak przeglądać w czasie, zatrzymując się na wymownych wzorcach i przeskakując mniej przydatne fragmenty.
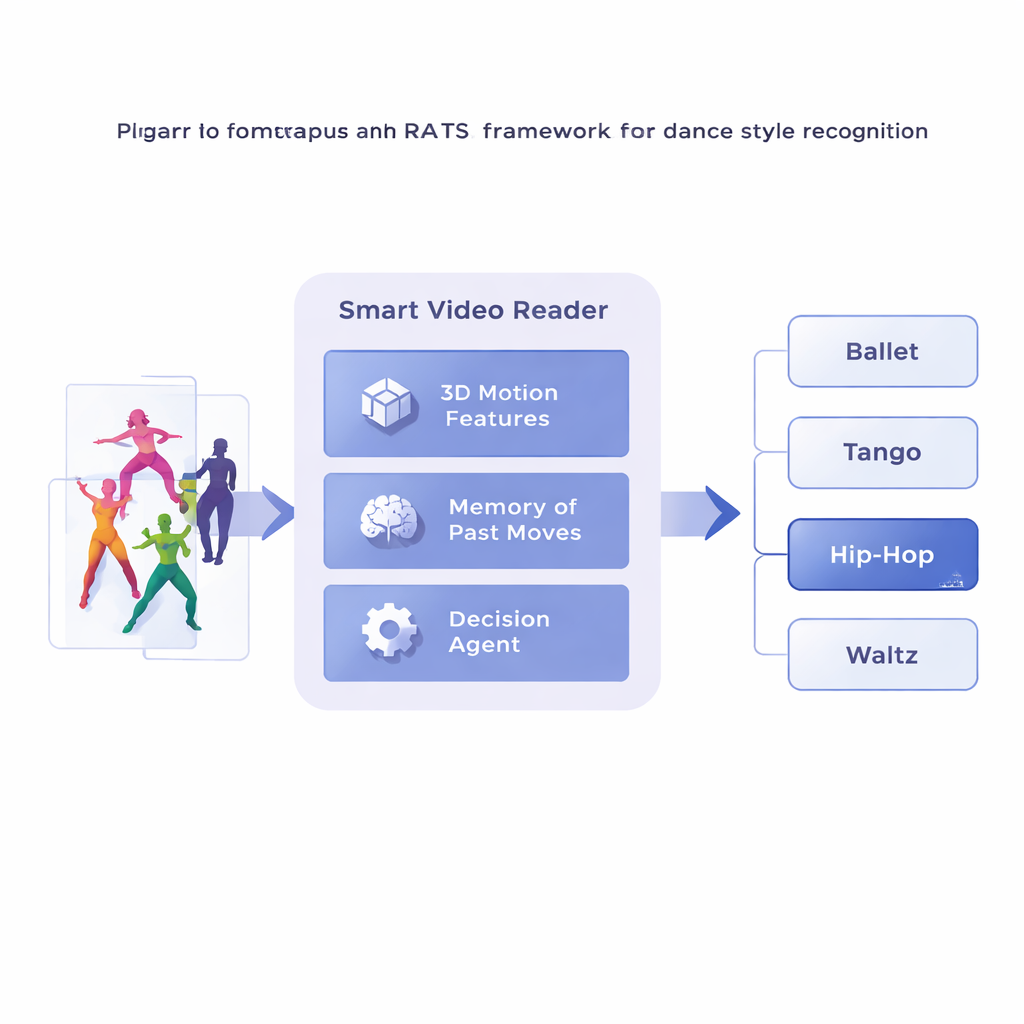
Nauka kiedy patrzeć, a kiedy zdecydować
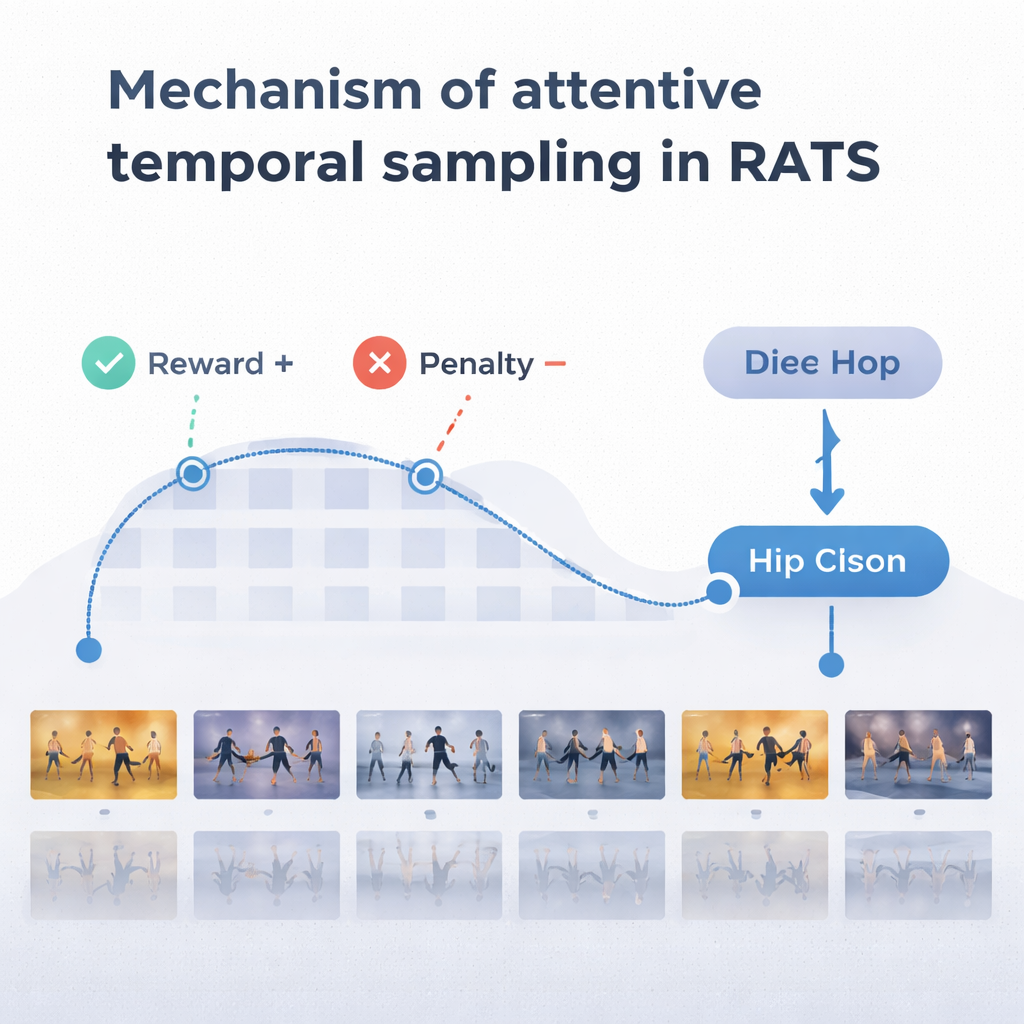
Aby podejmować sensowne wybory, agent polega na formie pamięci inspirowanej tym, jak przypominamy sobie zarówno przeszły, jak i pojawiający się ruch. Dwukierunkowa sieć rekurencyjna śledzi, co system już „zobaczył” i jak bieżące klipy odnoszą się do tej historii. Na każdym kroku agent waży trzy opcje: wykonać krótki skok, by zbadać szczegóły takie jak praca stóp, wykonać dłuższy przeskok ponad powtarzalnym ruchem, albo zatrzymać się i sklasyfikować taniec. System jest trenowany z wykorzystaniem nagród i kar: otrzymuje dużą dodatnią punktację za poprawną decyzję, dużą ujemną za błędną oraz niewielką karę za każdy przeskok do przodu. Taka równowaga zachęca agenta do bycia zarówno dokładnym, jak i efektywnym — czekania, aż zbierze wystarczające dowody, ale nie włóczęgi przez cały film.
Przewyższając konwencjonalne klasyfikatory tańca
Zespół przetestował RATS na zbiorze Let's Dance, wymagającej kolekcji 1000 filmów obejmujących dziesięć stylów, od flamenco i tanga po swing i tańce kwadratowe. W porównaniu z kilkoma istniejącymi metodami, w tym standardowymi sieciami głębokimi i innymi modelami skoncentrowanymi na tańcu, RATS osiągnął najwyższą dokładność — około 92% — oraz najlepszą ogólną równowagę precyzji i czułości. Okazał się też statystycznie lepszy od silnych konkurentów, a nie tylko nieznacznie różny przypadkowo. Co ważne, system osiągnął te wyniki analizując średnio tylko około 38% klatek wideo. Jednolite próbkowanie co kilka klatek było szybsze, ale pomijało kluczowe momenty i obniżało wydajność; przetwarzanie każdej klatki było wolniejsze i nadal mniej dokładne niż podejście ukierunkowane.
Co to znaczy poza parkietem
Dla laika główny przekaz jest prosty: komputery radzą sobie lepiej, gdy uczą się być wybiórczymi widzami. Ucząc AI koncentrowania się na "złotych momentach" w czasie, praca ta pokazuje, że maszyny mogą rozpoznawać złożone ruchy ludzkie dokładniej, wykorzystując przy tym mniej zasobów. Chociaż badanie koncentruje się na tańcu, ta sama idea może pomóc systemom wyłapywać kluczowe elementy w rutynach sportowych, materiałach z monitoringu czy dowolnych długich nagraniach, gdzie ważne zdarzenia są krótkie i rozproszone. Innymi słowy, sprytniejsze oglądanie — nie więcej oglądania — może być przyszłością rozumienia wideo.
Cytowanie: Yin, P., Li, X. A deep reinforcement learning approach to dance movement analysis. Sci Rep 16, 5541 (2026). https://doi.org/10.1038/s41598-026-35311-0
Słowa kluczowe: rozpoznawanie tańca, analiza wideo, głębokie uczenie, uczenie przez wzmacnianie, ruch człowieka