Clear Sky Science · pl
Model wyodrębniania relacji przestrzennych w języku chińskim przez integrację geograficznych cech semantycznych
Nauczanie komputerów rozumienia, gdzie znajdują się miejsca
Każdego dnia opisujemy lokalizacje prostymi sformułowaniami: miasto leży na południe od rzeki, park jest blisko uniwersytetu, autostrada przebiega przez prowincję. Przekształcenie takiego codziennego języka w precyzyjną wiedzę cyfrową jest kluczowe dla inteligentnych map, aplikacji nawigacyjnych i badań geograficznych. W artykule przedstawiono nową metodę, nazwaną PURE‑CHS‑Attn, która pomaga komputerom czytać teksty chińskie i automatycznie dokładniej określać relacje przestrzenne między miejscami niż dotychczas.
Dlaczego język przestrzenny ma znaczenie
Relacje przestrzenne to słowa i frazy, które mówią nam, jak miejsca są połączone w przestrzeni, na przykład „wewnątrz”, „obok”, „na północ od” lub „30 kilometrów od”. Tworzą one most między rzeczywistością widoczną na mapach a pojęciami, których używamy mentalnie. W systemach informacji geograficznej (GIS) relacje te leżą u podstaw organizacji, wyszukiwania i analizy danych. Są także istotne w innych dziedzinach: na przykład przy łączeniu obrazów satelitarnych, śledzeniu ruchu w wideo, planowaniu układów przemysłowych czy badaniu, jak klimat i rzeźba terenu kształtują bioróżnorodność. Ponieważ wiele z tych informacji jest zapisanych w języku naturalnym, niezawodne narzędzia potrafiące czytać tekst i automatycznie wyodrębniać relacje przestrzenne stają się coraz ważniejsze.
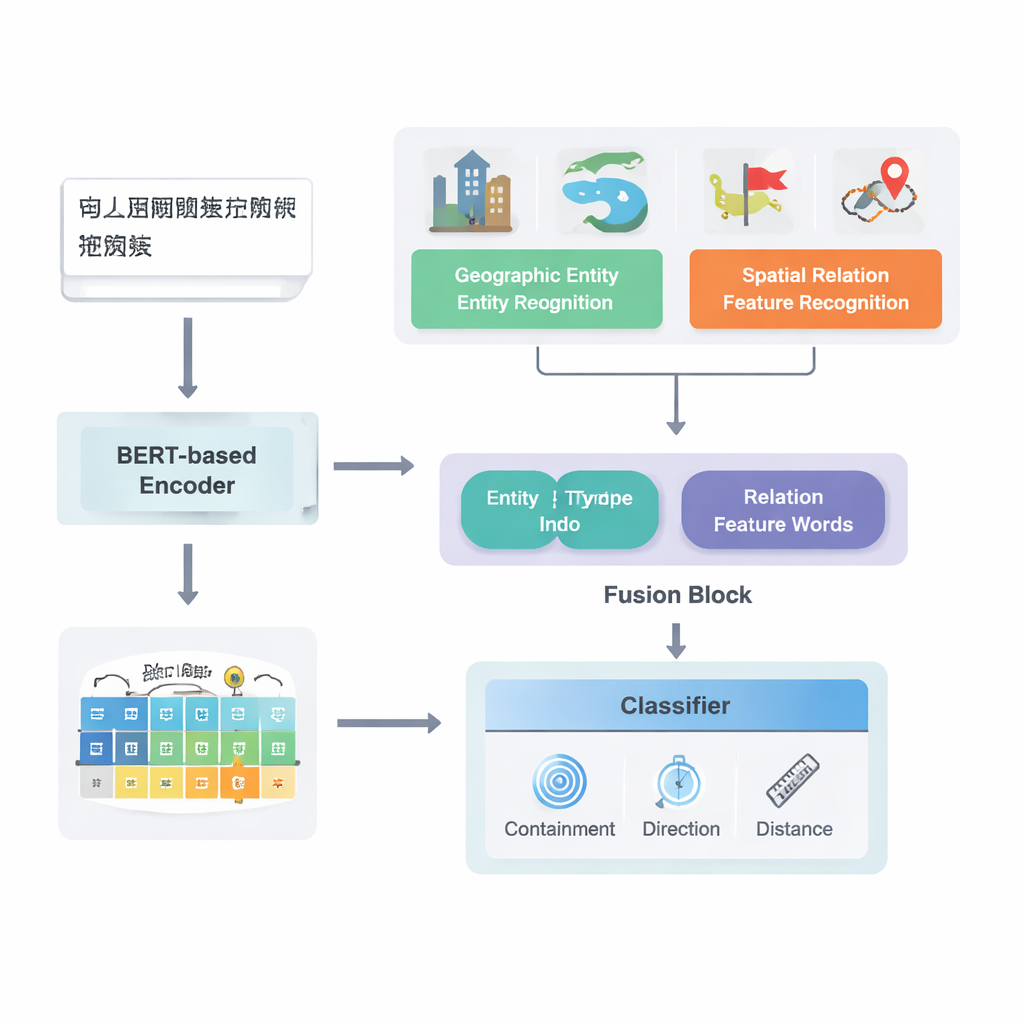
Od surowego tekstu do zmapowanych związków
Autorzy koncentrują się na tekstach chińskich i budują na bazie silnej istniejącej sieci głębokiego uczenia znanej jako PURE. Ich ulepszony model, PURE‑CHS‑Attn, działa w kilku etapach. Najpierw skanuje zdania, aby znaleźć jednostki geograficzne, takie jak góry, rzeki, miasta i jednostki administracyjne, i oznacza każdą z nich typem (na przykład powierzchnia lądu, zbiornik wodny, obiekt publiczny, zabytek historyczny lub jednostka administracyjna). Następnie wykrywa „słowa cech” relacji przestrzennych, takie jak „graniczy”, „przepływa przez”, „na południe od” czy „w pobliżu”, które sygnalizują, jak dwa miejsca są powiązane. Potężny model językowy BERT‑wwm‑ext przekształca znaki w każdym zdaniu w wektory numeryczne, które chwytają ich znaczenie i kontekst. Te wektory zasila się do oddzielnych modułów rozpoznających jednostki i słowa relacji, które następnie przekazują wyniki do modułu fuzji.
Łączenie wiedzy ludzkiej z uczeniem maszynowym
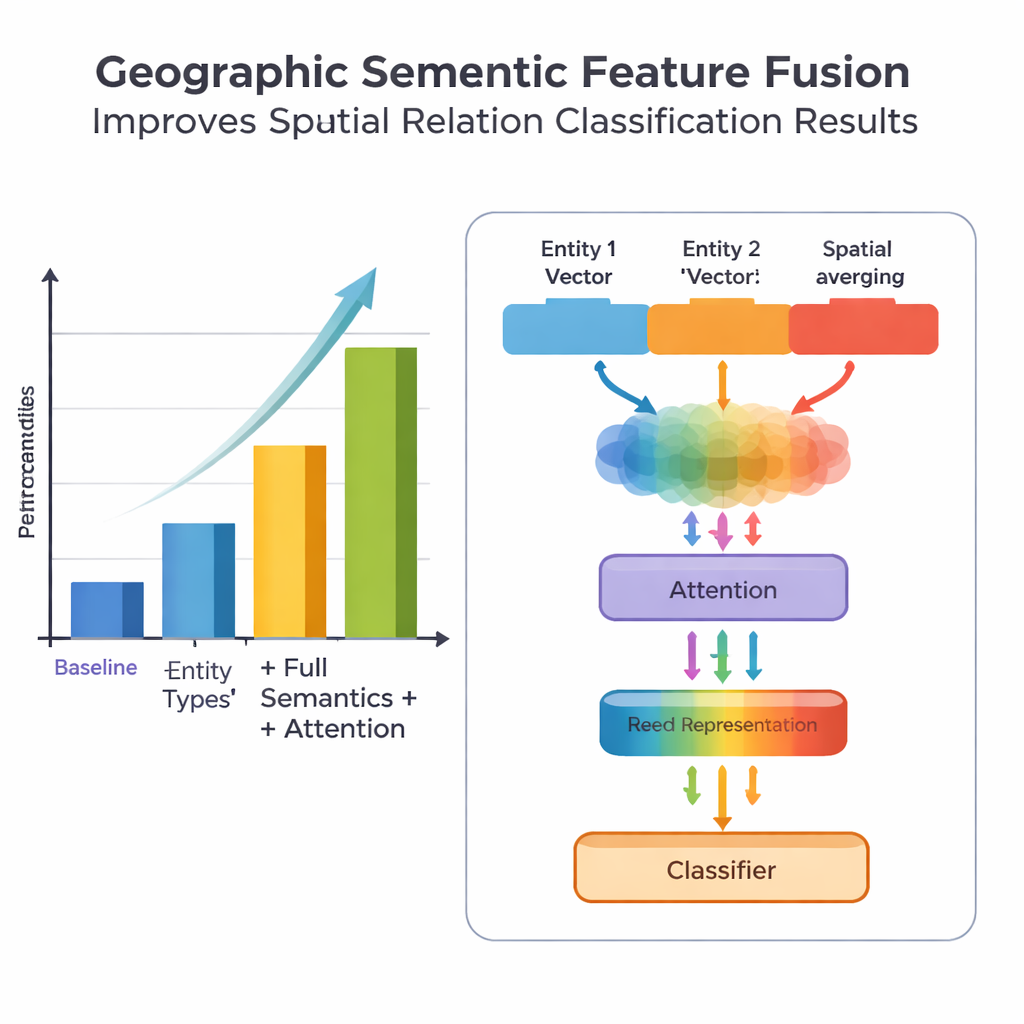
Kluczową nowością pracy jest sposób łączenia wiedzy geograficznej z nauczonymi wzorcami tekstowymi. Zamiast traktować każde słowo jednakowo, model wykorzystuje dwa rodzaje informacji semantycznej, których ludzie naturalnie używają: typ każdej jednostki geograficznej oraz konkretne słowa cech przestrzennych łączące je. Moduł fuzji najpierw łączy wektory dla dwóch jednostek, stosując wagi zależne od tego, jak często różne typy miejsc (na przykład dwie jednostki administracyjne versus rzeka i powiat) występują w różnych typach relacji. Następnie miesza wektory słów cech przestrzennych. Na szczycie tej „podstawowej fuzji” autorzy dodają mechanizm atencji, który pozwala modelowi dynamicznie skupić się na najbardziej informacyjnych częściach kombinacji jednostka–słowo. Końcowa zfuzowana reprezentacja trafia do klasyfikatora, który może przypisać jeden lub więcej typów relacji — topologiczne (jak zawieranie czy sąsiedztwo), kierunkowe (północ, południe itd.) lub oparte na odległości — między każdą parą miejsc w zdaniu.
Postawienie modelu na próbę
Aby ocenić swoje podejście, zespół zgromadził i starannie opatrzył adnotacjami zbiór danych z Encyklopedii Chin: Geografia Chin, zawierający 1381 zdań i 368 par relacji przestrzennych. Porównali kilka wersji modelu: bazową, która używa tylko zgrubnych informacji o lokalizacji, wersję z bardziej szczegółowymi typami jednostek, wersję, która dodaje słowa cech przestrzennych, oraz ich pełny model PURE‑CHS‑Attn z nowym projektem fuzji i atencji. Według standardowych miar precyzji, recall i F1, PURE‑CHS‑Attn poprawił wyniki o około 7% w precyzji, 6,5% w recall i 6,7% w F1 w porównaniu z bazą. Model był szczególnie silny w rozpoznawaniu relacji topologicznych i kierunkowych oraz lepiej radził sobie z rzadkimi typami relacji („few‑shot”) niż prostsze modele. W porównaniu z trzema niedawnymi systemami z czołówki, w tym jednym opartym na dużych modelach językowych, PURE‑CHS‑Attn zajął bliskie drugie miejsce, pozostając jednocześnie znacznie lżejszy i łatwiejszy do wdrożenia.
Wyzwania i kierunki na przyszłość
Mimo tych postępów model nadal ma problemy z relacjami odległościowymi, zwłaszcza gdy dostępnych jest tylko kilka przykładów treningowych. Autorzy pokazują, że ich zbiór danych zawiera bardzo niewiele takich przypadków, co ogranicza to, czego może nauczyć się każda metoda potrzebująca danych. Zauważają również, że ślepe uśrednianie wielu słów cech w zdaniu może wprowadzać szum, który ich mechanizm atencji pomaga zmniejszyć, ale nie rozwiązuje całkowicie. Patrząc w przyszłość, proponują dwie obiecujące ścieżki: rozszerzanie i wyważanie danych treningowych przy użyciu augmentacji oraz łączenie ich geograficznej fuzji semantycznej z technikami z dużych modeli językowych i uczenia przez promptowanie, aby jeszcze bardziej poprawić wydajność w scenariuszach z małą ilością danych przy zachowaniu efektywności systemu.
Co to oznacza dla codziennego mapowania
Mówiąc prosto, badania te uczą komputery czytać opisy przestrzenne w języku chińskim bardziej jak ludzie, zwracając uwagę na rodzaj wspomnianych miejsc i na to, jak dokładnie sformułowano ich relacje. Model PURE‑CHS‑Attn pokazuje, że łączenie ustrukturyzowanej wiedzy geograficznej z nowoczesnym uczeniem głębokim prowadzi do dokładniejszego i bardziej odpornego wyodrębniania informacji typu „kto jest gdzie w stosunku do czego” z tekstu. Toruje to drogę do inteligentniejszych, bardziej zautomatyzowanych systemów GIS, bogatszych geograficznych grafów wiedzy i lepszych narzędzi do badania tego, jak przestrzeń jest opisywana w nauce, polityce i codziennej komunikacji.
Cytowanie: Ye, P., Wang, Y., Jiang, Y. et al. Chinese spatial relation extraction model by integrating geographic semantic features. Sci Rep 16, 5537 (2026). https://doi.org/10.1038/s41598-026-35282-2
Słowa kluczowe: wyodrębnianie relacji przestrzennych, geoprzestrzenna sztuczna inteligencja, semantyka geograficzna, analiza tekstu w języku chińskim, automatyzacja GIS