Clear Sky Science · pl
Podejście uczenia maszynowego do identyfikacji odmian pszenicy za pomocą obrazowania pojedynczych ziaren
Dlaczego inteligentniejsze sortowanie nasion ma znaczenie
Dla rolników i firm nasiennych rozróżnienie jednej odmiany pszenicy od innej ma kluczowe znaczenie. Wysadzenie niewłaściwego typu może oznaczać niższe plony, gorszą odporność na choroby oraz uprawy nieprzystosowane do lokalnej gleby czy klimatu. Tymczasem gołym okiem różne odmiany pszenicy wyglądają niemal identycznie. W badaniu tym zbadano, jak sztuczna inteligencja i cyfrowe fotografie pojedynczych nasion mogą wiarygodnie rozróżniać blisko spokrewnione odmiany, otwierając drogę do szybszej, tańszej i bardziej obiektywnej kontroli jakości nasion.
Od oceny eksperckiej do kontroli opartej na aparacie
Obecnie wiele systemów kontroli nasion nadal polega na ludzkich ekspertach, którzy wizualnie oceniają odmianę i czystość nasion. Proces ten jest powolny, kosztowny i podatny na rozbieżności, zwłaszcza że wiele odmian pszenicy różni się jedynie subtelnymi zmianami kształtu lub wzoru powierzchni. Autorzy postanowili zastąpić tę subiektywną metodę systemem automatycznym, który wykorzystuje obrazy pojedynczych ziaren wykonane w małej skrzyni z kontrolowanym oświetleniem. Poprzez staranne standaryzowanie oświetlenia, odległości i koloru tła stworzyli czysty zapis wizualny sześciu powszechnych irańskich odmian pszenicy, generując dziesiątki tysięcy zdjęć nasion do trenowania i testowania modeli komputerowych.
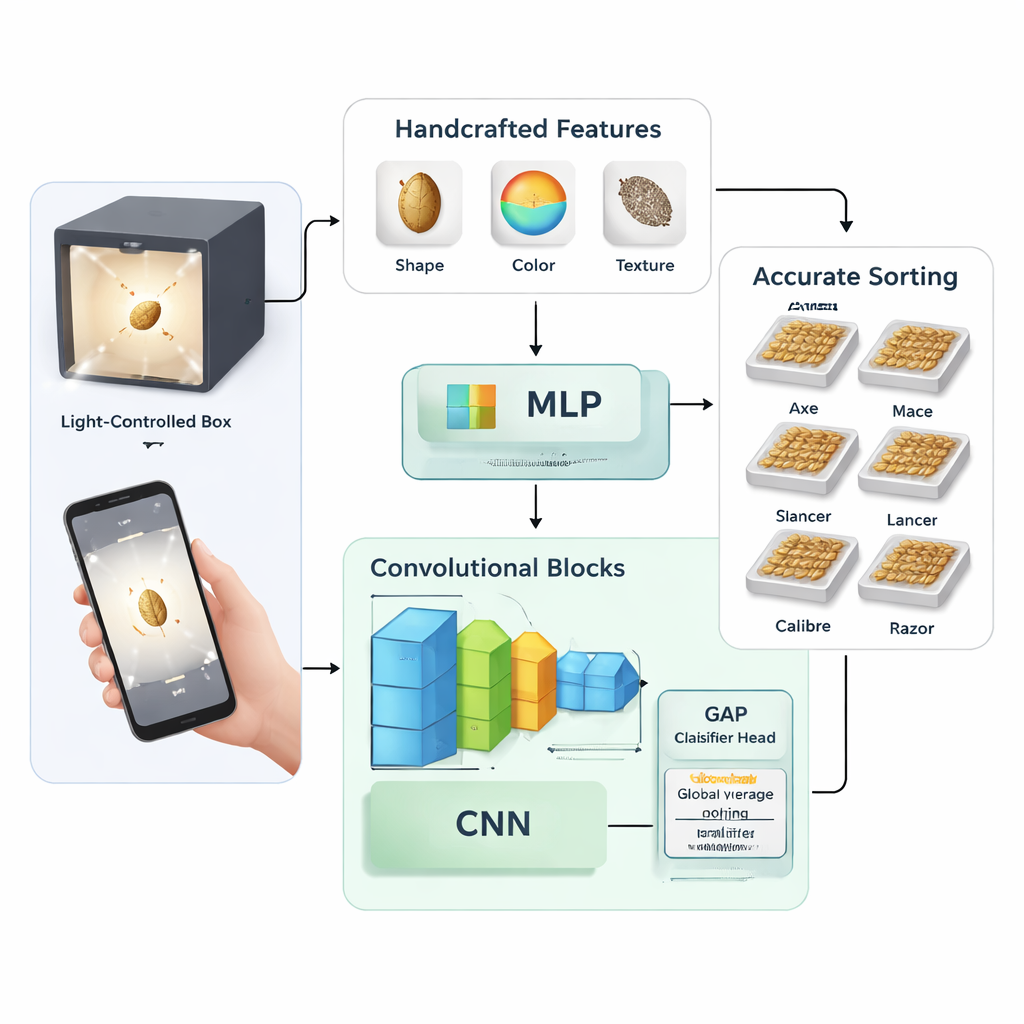
Dwa sposoby nauczenia komputera rozpoznawania nasion
Badanie porównuje dwie szerokie strategie nauczania maszyny rozpoznawania odmian pszenicy. W pierwszej badacze ręcznie opracowali 58 miar liczbowych z każdego obrazu nasiona, w tym podstawowe miary kształtu (takie jak długość i powierzchnia), statystyki kolorów w różnych przestrzeniach barw oraz wzory tekstury. Następnie zastosowali analizę głównych składowych, by skondensować te pomiary do 27 kluczowych cech, które podali do tradycyjnej sieci neuronowej zwanej perceptronem wielowarstwowym. W drugiej strategii pominęli ręczne projektowanie cech i trenowali sieci konwolucyjne — modele AI skoncentrowane na obrazach — aby uczyły się użytecznych wzorców bezpośrednio z surowych danych pikselowych.
Budowanie smukłego, lecz wydajnego modelu głębokiego uczenia
Podejście głębokiego uczenia testowano w kilku wariantach. Autorzy zaprojektowali własną stosunkowo niewielką sieć z dwiema do czterech nakładających się bloków konwolucyjnych i eksperymentowali z różnymi ustawieniami treningu, takimi jak tempo uczenia, poziomy dropout oraz rozmiary partii. Porównywali także dwa sposoby wykańczania sieci: klasyczną warstwę „w pełni połączoną” versus bardziej zwartą metodę zwaną globalnym uśrednianiem (global average pooling), która zastępuje duże warstwy gęste prostym krokiem uśredniania przed ostateczną klasyfikacją. Dla porównania dostrajali również dwie cięższe, powszechnie używane architektury — Inception-ResNet-v2 i EfficientNet-B4 — na tym samym zbiorze danych pszenicy, aby sprawdzić, jak dopasowany mały model wypada wobec głębokich, uniwersalnych sieci.
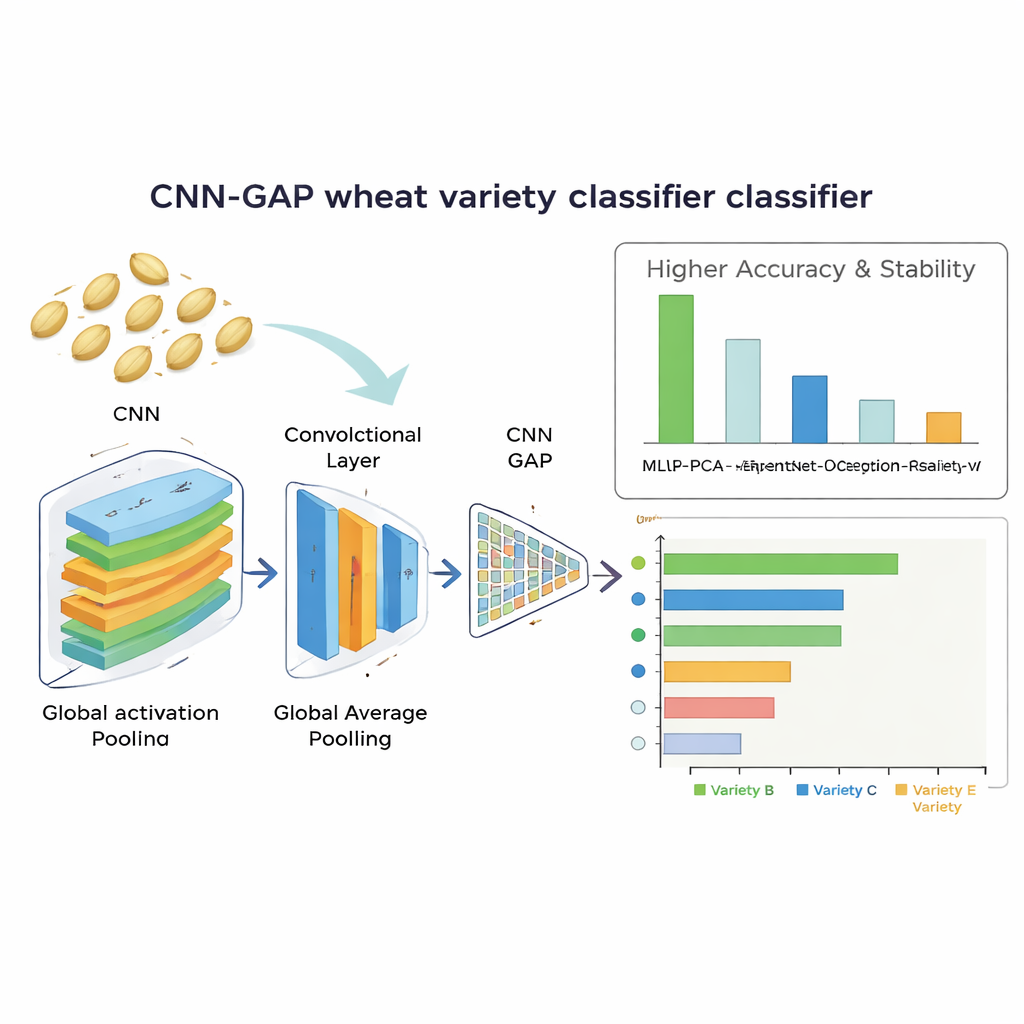
Jak dobrze system rozpoznaje ziarno
Najlepiej sprawdziła się niestandardowa sieć konwolucyjna wykorzystująca globalne uśrednianie. Poprawnie identyfikowała odmiany pszenicy w około 92% przypadków i wykazywała bardzo stabilne wyniki przy powtarzanych uruchomieniach treningu. Model ten nie tylko przewyższał duże sieci wstępnie wytrenowane, ale także pokonał podejście oparte na ręcznie opracowanych cechach, które osiągnęło około 86% dokładności po redukcji wymiarowości. Analiza wzorców pomyłek pokazała, że lżejszy model szczególnie dobrze radził sobie z rozdzielaniem odmian wyglądających bardzo podobnie, podczas gdy głębsze modele wykorzystujące transfer learning miały tendencję do przeuczania się na ograniczonym zbiorze danych. Co ważne, zwycięska sieć była wydajna: przetwarzała każdy obraz nasiona w około 13,6 milisekundy i zawierała jedynie około 2,1 miliona regulowanych parametrów, co czyni ją realistyczną do użycia w tanim, działającym w czasie rzeczywistym sprzęcie sortującym.
Ograniczenia, zastosowania w terenie i dalsze kroki
Gdy ten sam model przetestowano na zupełnie innym gatunku — nasionach ciecierzycy — jego dokładność gwałtownie spadła, ujawniając, że system dostrojony do drobnych różnic między ziarnami pszenicy nie uogólnia się automatycznie na inne gatunki. Podobnie, ponieważ wszystkie obrazy treningowe pochodziły z starannie kontrolowanej komory, wydajność może się obniżyć przy zmiennym oświetleniu polowym lub przy ziarniakach częściowo zasłoniętych. Mimo to praca pokazuje, że kompaktowy, dobrze zaprojektowany model głębokiego uczenia, zasilany standaryzowanymi obrazami pojedynczych nasion, może wiarygodnie rozróżniać odmiany pszenicy niemal nieodróżnialne gołym okiem. Przy szerszych danych treningowych i bardziej zróżnicowanych warunkach obrazowania podobne systemy mogłyby stać się praktycznymi narzędziami do automatycznej certyfikacji nasion, pomagając rolnikom zapewnić czystsze partie nasion i bardziej przewidywalne zbiory.
Cytowanie: Bagherpour, H., Shamohammadi, S. Machine learning approach for wheat variety identification using single-seed imaging. Sci Rep 16, 6472 (2026). https://doi.org/10.1038/s41598-026-35252-8
Słowa kluczowe: ziarna pszenicy, głębokie uczenie, klasyfikacja oparta na obrazach, jakość nasion, rolnictwo precyzyjne