Clear Sky Science · pl
Przewaga inżynierii cech nad złożonością architektury w prognozowaniu popytu przerywanego
Dlaczego warto przewidywać rzadką sprzedaż
Za każdym warsztatem samochodowym czy magazynem części kryje się ciche pytanie: ile wolno rotujących części warto trzymać na półce? Te pozycje sprzedają się rzadko i nieprzewidywalnie, a mimo to muszą być dostępne, gdy pojazd ulegnie awarii. Zamawiając za dużo, kapitał zastyga w kurzącym się zapasie; zamawiając za mało, klienci czekają, a części są ściągane ekspresowo. Artykuł zajmuje się tym codziennym, kosztownym problemem, stawiając proste pytanie: czy lepiej tworzyć coraz bardziej skomplikowane modele prognostyczne, czy raczej karmić istniejące modele mądrzejszymi, starannie zaprojektowanymi sygnałami z danych?
Od długich okresów braku sprzedaży do nagłych skoków
W wielu łańcuchach dostaw, zwłaszcza w przypadku części samochodowych, popyt nie jest stały jak na mleko czy chleb. Zamiast tego występują długie okresy miesięcy bez sprzedaży, przerywane nagłymi zamówieniami kilku sztuk. Autorzy analizują ponad 56 000 kombinacji dilera i części, obejmujących około 1,4 miliona miesięcznych zapisów, i stwierdzają, że większość szeregow jest skrajnie rzadka: przeciętnie na każdy miesiąc ze sprzedażą przypada wiele miesięcy zerowych, a wielkość zamówień bardzo się waha. Tradycyjne metody statystyczne, takie jak podejście Crostona i jego refinements, powstały z myślą o takim „włącz–wyłącz” popycie i dostarczają stabilnych, interpretable prognoz, lecz traktują każdą część osobno i trudno jest im wykorzystać dodatkowe informacje, takie jak ceny czy cechy produktu. Nowoczesne systemy uczenia maszynowego mogą z zasady użyć tych informacji, ale mają trudności, gdy dane w większości to zera i tylko sporadycznie niosą sygnał.
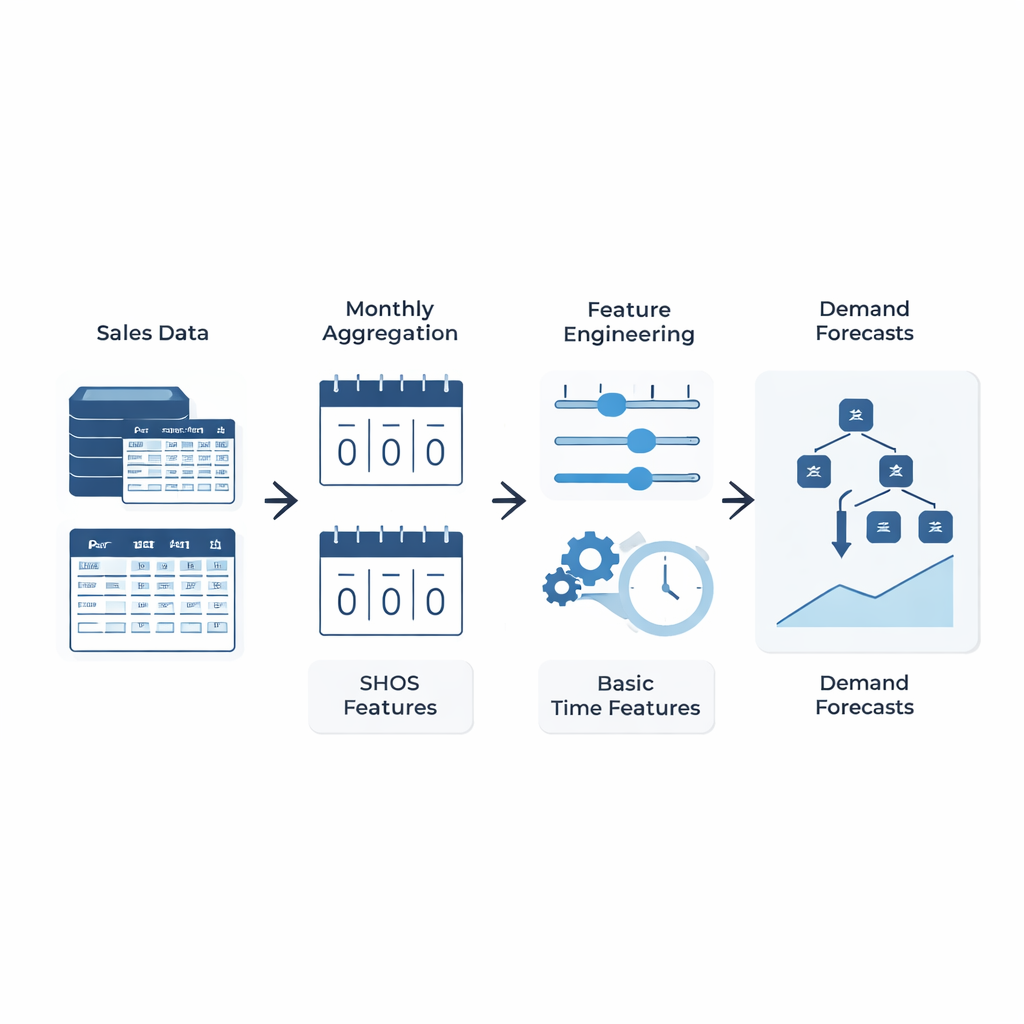
Prosty pomysł: naucz model, co naprawdę ma znaczenie
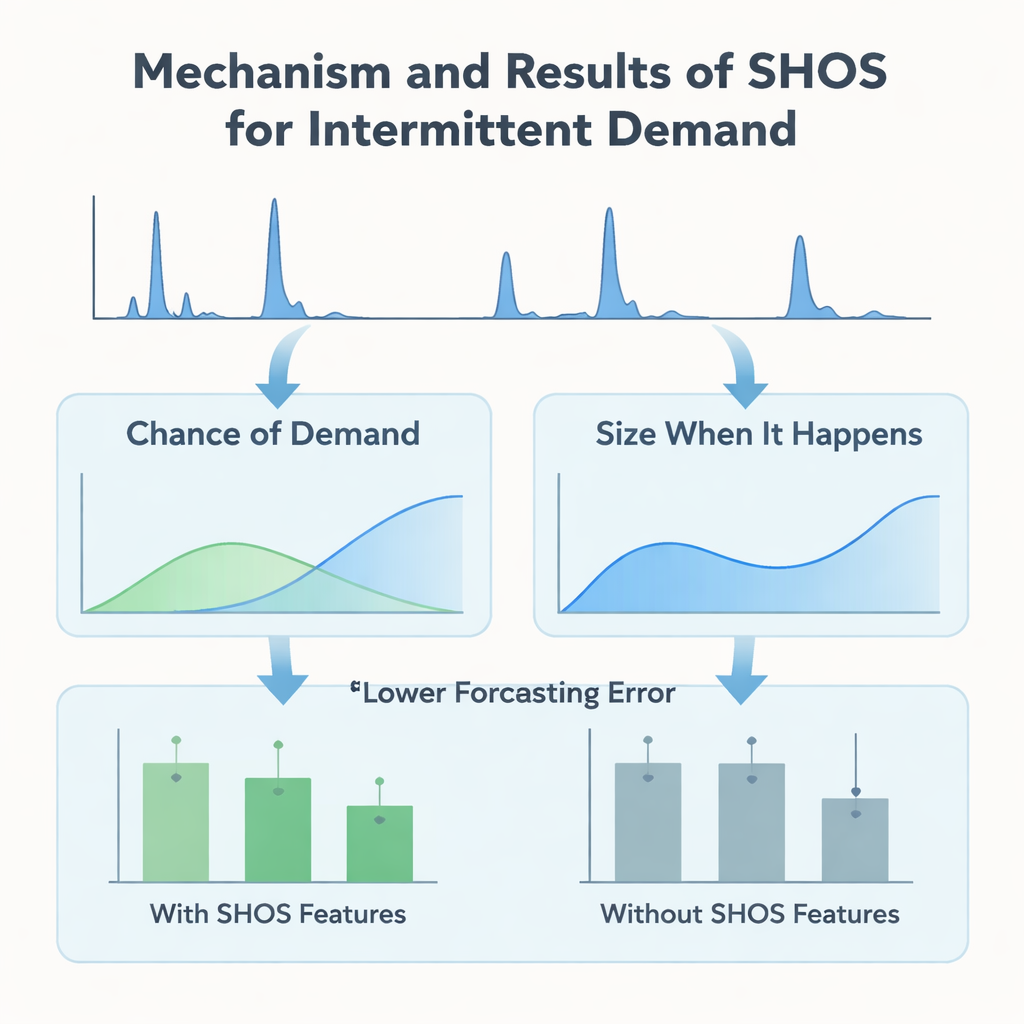
Zamiast projektować coraz bardziej zawiłe architektury uczenia maszynowego, autorzy koncentrują się na tym, co jest podawane modelowi. Wprowadzają ramy Smoothed Hybrid Occurrence–Size (SHOS), lekką procedurę statystyczną działającą na każdej historii popytu. Co miesiąc SHOS generuje dwie liczby: oszacowane prawdopodobieństwo, że w następnym miesiącu wystąpi jakikolwiek popyt, oraz typową wielkość tego popytu, jeśli się pojawi. Robi to poprzez staranne wygładzanie przeszłych zer i wartości niezerowych, dostosowując zachowanie dla bardzo rzadkich szeregów i reagując szybciej, gdy popyt nagle wraca po długiej przerwie. Istotne jest to, że SHOS nie jest finalnym modelem prognostycznym. Jego wyjścia stają się dodatkowymi cechami wejściowymi dla standardowych algorytmów uczenia maszynowego, obok prostych elementów, takich jak ostatnie sprzedaże, średnie kroczące czy statyczne dane produktowe.
Stawianie jakości cech ponad złożoność modelu
Aby sprawdzić, czy to statystyczne „wstępne przetwarzanie” rzeczywiście pomaga, badacze zbudowali kontrolowany eksperyment. Porównują szereg popularnych modeli — drzewa gradientowe, lasy losowe i metody liniowe — z i bez cech SHOS, wszystkie trenowane na tym samym miesięcznym panelu wypełnionym zerami i oceniane przy użyciu rygorystycznego schematu okien kroczących, symulującego rzeczywiste wdrożenie. Testują też bardziej rozbudowane dwustopniowe modele „hurdle”, które osobno przewidują, czy popyt wystąpi, oraz jak duży będzie. W 11 oknach walidacyjnych dodanie cech SHOS niemal zmniejsza średni błąd prognozy o połowę dla silnie przerywanych pozycji i obniża kluczową miarę biznesową — ważony średni bezwzględny błąd procentowy — o ponad 40%. Co zaskakujące, dwustopniowe architektury, mimo że są bardziej skomplikowane i dostosowane do tego typu danych, nie przewyższają prostego jednofazowego regresora, który bezpośrednio przyjmuje sygnały SHOS.
Jak model podejmuje decyzje
Zespół idzie dalej niż ogólna dokładność i bada, jak modele faktycznie wykorzystują dostarczone informacje. Z użyciem SHAP, standardowego narzędzia do interpretacji predykcji uczenia maszynowego, pokazują, że cechy oparte na SHOS — „szansa na popyt” i „wielkość, gdy się pojawi” — konsekwentnie należą do najbardziej wpływowych wejść. W długich okresach zerowego popytu niskie prawdopodobieństwo SHOS przesuwa prognozy w kierunku zera, zapobiegając fałszywemu gromadzeniu zapasu. Gdy po suszy pojawia się seria zamówień, dostosowanie recencyjne w SHOS szybko podnosi estymowane prawdopodobieństwo i wielkość, pozwalając modelowi zareagować bez nadmiernej reakcji na pojedynczy skok. Te zachowania obserwuje się zarówno w prostym modelu jednofazowym, jak i w bardziej złożonych wersjach hurdle, co podkreśla, że główny zysk wynika z jakości sygnałów, a nie z architektonicznych sztuczek.
Co to oznacza dla codziennych decyzji o zapasach
Dla praktyków starających się utrzymać właściwe części na półce przekaz jest praktyczny i uspokajający. Badanie pokazuje, że starannie zaprojektowane, statystycznie uzasadnione cechy mogą przynieść duże ulepszenia w prognozowaniu rzadkiej, nieregularnej sprzedaży bez uciekania się do kruchych, trudnych w utrzymaniu konfiguracji modeli. Umiarkowany, dobrze dostrojony model gradientowy wyposażony w cechy SHOS przewyższa lub dorównuje bardziej rozbudowanym pipeline’om, jednocześnie pozostając łatwiejszym do wdrożenia i monitorowania dla dziesiątek tysięcy pozycji. Mówiąc prosto: dostarczanie systemowi prognostycznemu lepszych podsumowań o tym, jak często i ile klienci prawdopodobnie zamówią, może mieć większe znaczenie niż przejście na najnowszy, najbardziej złożony algorytm. To nastawienie na proste, interpretowalne budulce sprawia, że podejście jest atrakcyjne dla dużych, rzeczywistych łańcuchów dostaw i sugeruje, że podobne strategie skoncentrowane na cechach mogą się sprawdzić także w innych branżach zmagających się z popytem przerywanym.
Cytowanie: Nathan, B.S., Aravinth, P.M., Reddy, B.V.S. et al. Primacy of feature engineering over architectural complexity for intermittent demand forecasting. Sci Rep 16, 4792 (2026). https://doi.org/10.1038/s41598-026-35197-y
Słowa kluczowe: popyt przerywany, prognozowanie części zamiennych, inżynieria cech, analityka łańcucha dostaw, uczenie maszynowe