Clear Sky Science · pl
Kompaktowe modele głębokiego uczenia do histopatologii jelita grubego — koncentracja na wydajności i problemach z uogólnianiem
Dlaczego te badania mają znaczenie dla pacjentów i lekarzy
Rak jelita grubego jest jednym z najgroźniejszych nowotworów na świecie, a jego rozpoznanie wciąż opiera się na tym, że specjaliści dokładnie oglądają obrazy mikroskopowe tkanek — zadaniu czasochłonnym i podatnym na różnice w ocenie. W tym badaniu sprawdzono, czy bardzo małe, wydajne modele sztucznej inteligencji (AI) mogą wystarczająco dokładnie wskazywać tkankę nowotworową jelita, aby być użytecznymi w codziennych warunkach klinicznych, także tam, gdzie dostępna moc obliczeniowa jest ograniczona. Badanie ujawnia także ukrytą słabość: modele, które podczas prac rozwojowych wyglądają niemal perfekcyjnie, mogą jednak mocno zawodzić na nowych, rzeczywistych danych.
Nauczanie komputerów „czytania” obrazów mikroskopowych
Gdy pobiera się wycinek jelita, patolodzy oglądają cienkie, zabarwione skrawki tkanek pod mikroskopem. Tkanka nowotworowa wykazuje zniekształcone gruczoły, nieregularne kształty komórek i naciekanie struktur otaczających, podczas gdy tkanka prawidłowa ma uporządkowane, regularne wzory. Autorzy wykorzystali publiczny zbiór 24 000 cyfrowych obrazów takich skrawków, równomiernie podzielony na próbki z rakiem (gruczolakorak jelita grubego) i tkanką łagodną. Wszystkie obrazy zostały przeskalowane do standardowego, małego rozmiaru i poddane realistycznym modyfikacjom — niewielkim obrotom, odbiciom, przybliżeniom oraz delikatnym zmianom kolorów — aby naśladować naturalne różnice w cięciu, barwieniu i skanowaniu preparatów. Taka staranna przygotowa pomaga modelom AI skupić się na znaczących wzorcach tkankowych zamiast na powierzchownych szczegółach, jak dokładna orientacja czy jasność.
Tworzenie małych, lecz zdolnych „oczu” AI
Wiele udanych systemów AI w medycynie opiera się na bardzo dużych modelach głębokiego uczenia, które wymagają potężnych kart graficznych i dużo pamięci, co utrudnia ich wdrożenie w mniejszych szpitalach czy przy łóżku pacjenta. Aby zmniejszyć tę przepaść, badacze zaprojektowali cztery kompaktowe sieci konwolucyjne — Lite‑V0, Lite‑V1, Lite‑V2 i Lite‑V4. Każda analizuje te same fragmenty obrazu, lecz różni się liczbą warstw i filtrów wykrywających cechy wizualne, takie jak krawędzie, tekstury czy kształty gruczołów. Wszystkie cztery mają prostą, przejrzystą architekturę: powtarzające się bloki standardowych konwolucji, normalizacji i pooling, zakończone niewielką „głowicą decyzyjną” zwracającą prawdopodobieństwo raka lub tkanki łagodnej. Celem było sprawdzenie, ile dokładności można wyciągnąć z modeli na tyle małych, by wygodnie działały na podstawowym sprzęcie klinicznym.
Imponujące wyniki w warunkach laboratoryjnych
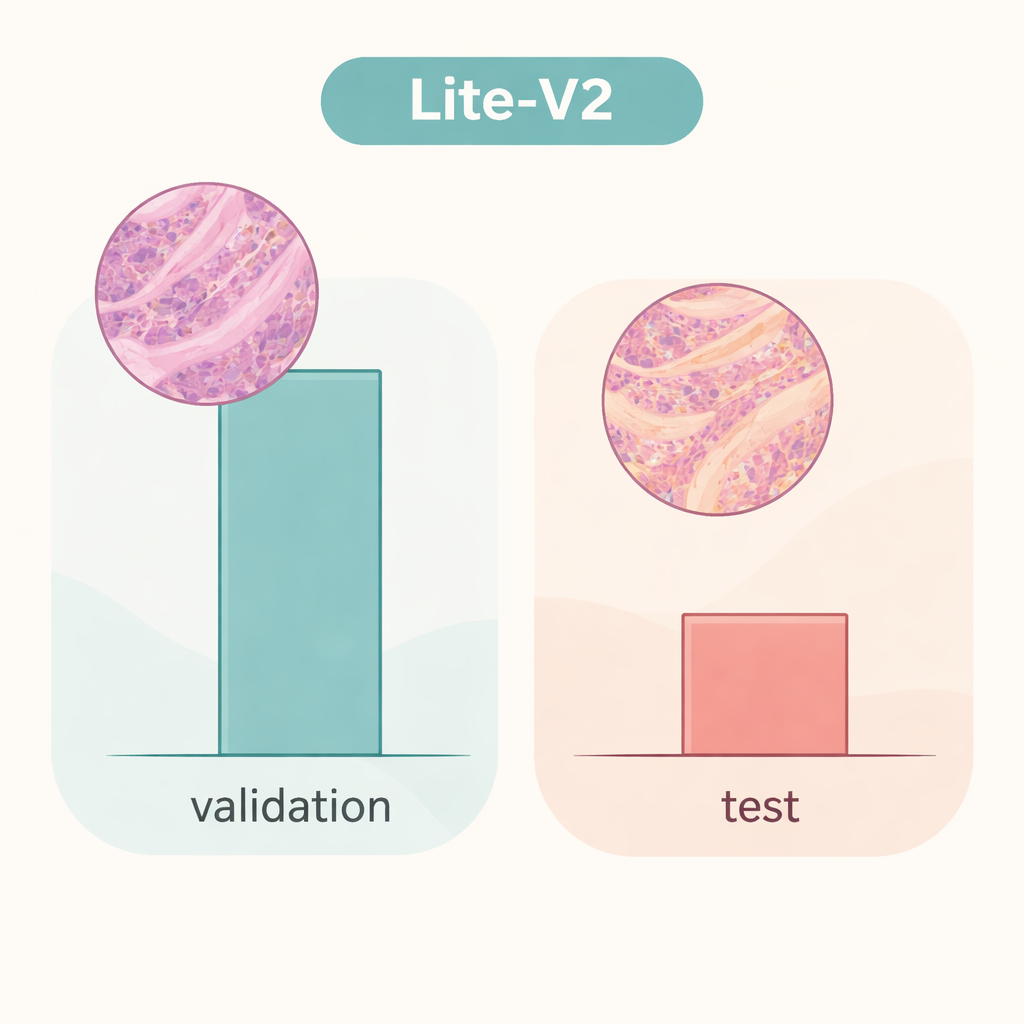
Zespół wytrenował i porównał wszystkie cztery modele na ustalonym podziale zbioru, używając powszechnie akceptowanych miar: dokładności, zrównoważonego F1 (ważącego błędy obu klas równomiernie), macierzy pomyłek oraz wykresów diagnostycznych, takich jak krzywe ROC i precyzja–czułość. Modelem wyróżniającym się okazał się średniej wielkości Lite‑V2. Mimo że miał tylko około 1,5 megabajta i w przybliżeniu 128 000 trenowalnych parametrów, osiągnął niemal bezbłędne wyniki na wewnętrznym zbiorze walidacyjnym, z makro F1 około 0,999 oraz niemal idealną czułością i specyficznością. Innymi słowy, w tym starannie przygotowanym środowisku Lite‑V2 niemal zawsze potrafił odróżnić tkankę nowotworową od łagodnej, pozostając jednocześnie szybkim i wystarczająco lekkim do użycia na skromnych komputerach.
Gdy rzeczywista zmienność łamie czar
Jednak historia zmienia się dramatycznie, gdy ten sam model Lite‑V2 testowano na niezależnym zbiorze obrazów, które różniły się subtelnie w sposób przypominający preparaty z innego laboratorium — to, co badacze nazywają „przesunięciem domeny”. Na tym nieznanym zestawie testowym ogólna dokładność spadła do około 50%, a zrównoważone F1 obniżyło się do około 0,33. Model nadal rozpoznawał wiele próbek nowotworowych, ale miał poważne problemy z tkankami łagodnymi, błędnie klasyfikując dużą ich część jako złośliwe. Pokazuje to, że sieć nauczyła się cech ściśle związanych z oryginalnym źródłem danych — takich jak styl barwienia czy cechy skanera — zamiast trwałych, przenośnych sygnatur choroby. Praca podkreśla, że świetne wyniki walidacji wewnętrznej mogą dawać fałszywe poczucie bezpieczeństwa, jeśli modele nie są testowane na naprawdę różnorodnych danych.
Co to oznacza dla przyszłych narzędzi diagnostycznych AI
Dla ogólnego czytelnika wnioski są dwojakie. Po pierwsze, kompaktowe systemy AI rzeczywiście mogą osiągać poziom ekspercki w analizie obrazów tkanek jelita, pozostając jednocześnie na tyle małymi i efektywnymi, by umożliwić szerokie wdrożenie — co otwiera drogę do szybszego przesiewu i wsparcia przeciążonych patologów. Po drugie, i równie istotne, model który wygląda „perfekcyjnie” na swoim macierzystym zbiorze danych, może poważnie zawodzić na obrazach z nowego szpitala. Autorzy argumentują, że przyszłe prace muszą koncentrować się na uczynieniu tych lekkich modeli odpornymi na zmiany w barwieniu, skanerach i populacjach pacjentów — przy użyciu strategii takich jak trening odporny na barwienie, adaptacja domeny i szersze, wieloośrodkowe zbiory danych. Do czasu osiągnięcia tej odporności AI powinno być postrzegane jako obiecujący asystent, a nie samodzielny decydent w rozpoznawaniu raka.
Cytowanie: Hanif, F., Raza, A. & Mohammed, H.A. Compact deep learning models for colon histopathology focusing performance and generalization challenges. Sci Rep 16, 5489 (2026). https://doi.org/10.1038/s41598-026-35119-y
Słowa kluczowe: rak jelita grubego, histopatologia, głębokie uczenie, lekkie CNN, przesunięcie domeny