Clear Sky Science · pl
Predykcja białek związanych z korzeniami przy użyciu dużego modelu języka białek i hiper-graficznych sieci konwolucyjnych
Dlaczego korzenie i ich ukryci pomocnicy mają znaczenie
Kiedy myślimy o utrzymaniu zdrowia upraw, zwykle wyobrażamy sobie liście i owoce. Jednak wiele z sukcesu rośliny dzieje się poza zasięgiem wzroku, w glebie. Tam specjalne białka związane z korzeniami pomagają roślinom pobierać wodę i składniki odżywcze oraz radzić sobie ze stresem, takim jak susza czy słaba gleba. Wykrywanie tych kluczowych białek wyłącznie za pomocą badań laboratoryjnych jest powolne i kosztowne. W tym badaniu przedstawiono wydajny model komputerowy, nazwany Hypergraph-Root, który może szybko przeglądać sekwencje białek i przewidywać, które z nich prawdopodobnie są związane z korzeniami, oferując szybszą drogę do bardziej odpornych upraw i lepszych plonów.
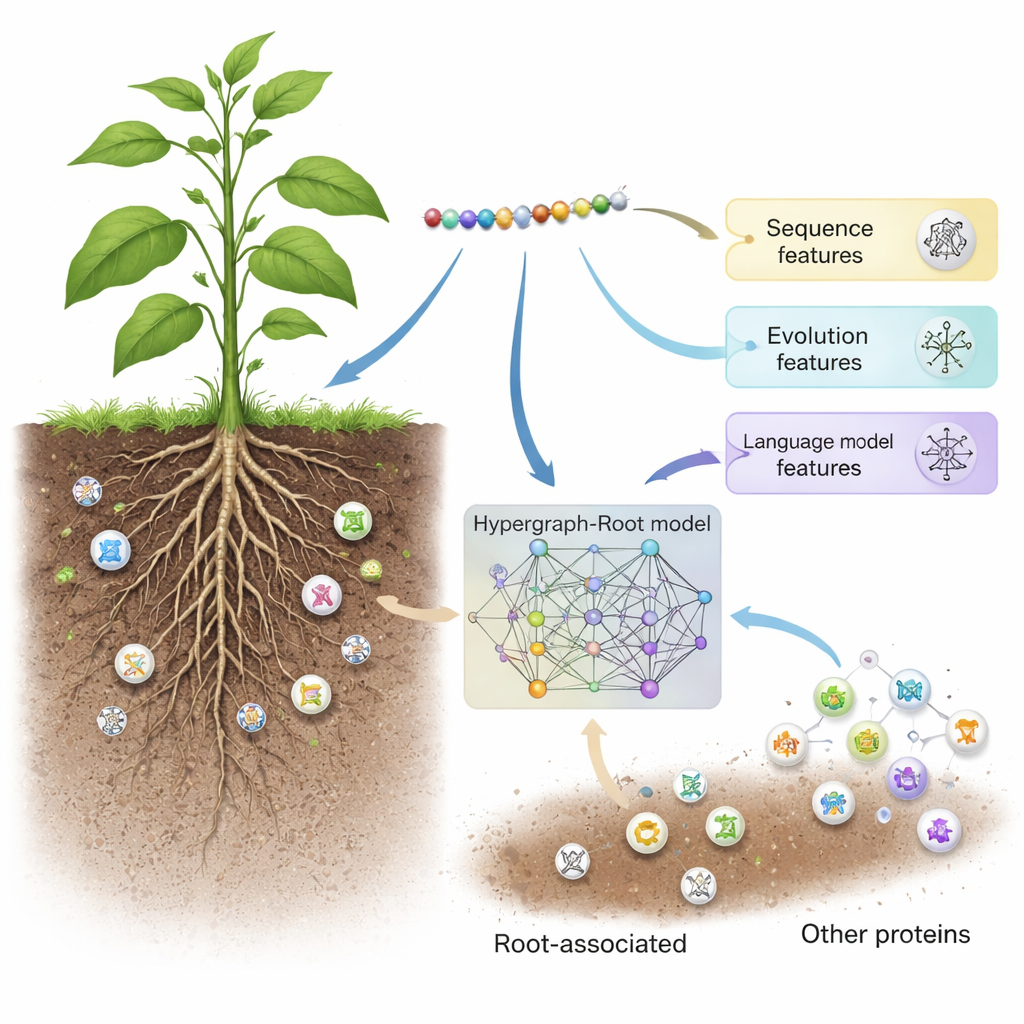
Ukryci pracownicy w glebie
Korzenie roślin robią więcej niż tylko kotwiczą roślinę w podłożu. Stale wyczuwają otoczenie, pobierają minerały i komunikują się z mikroorganizmami glebowymi. Białka związane z korzeniami są centralne dla tych procesów, kształtując wzrost korzeni, ich reakcje na wysoką temperaturę, suszę czy niedobory składników oraz interakcje z pożytecznymi mikroorganizmami. Ponieważ te białka silnie wpływają na plon i odporność, rolnicy i hodowcy zwracają na nie uwagę, nawet jeśli ich nie widzą bezpośrednio. Mimo to wiele takich białek pozostaje nieodkrytych, głównie dlatego, że tradycyjne metody — takie jak proteomika i badania ekspresji genów — wymagają kosztownych urządzeń, złożonych analiz i żmudnych eksperymentów.
Przekształcanie sekwencji białek w wskazówki
Białka zbudowane są z łańcuchów aminokwasów, a wzory w tych łańcuchach często ujawniają, gdzie białko działa w roślinie i co robi. Wcześniejsze modele komputerowe próbowały wykorzystać te wzory do wykrywania białek związanych z korzeniami, ale osiągały dokładności poniżej 80 procent. Jednym z problemów było traktowanie relacji między aminokwasami w dość prosty sposób, zwykle jako pary. Innym problemem był ograniczony zakres cech wyodrębnianych z sekwencji. Autorzy założyli, że bogatsze reprezentacje każdego białka, połączone z mądrzejszymi metodami modelowania relacji między aminokwasami, mogą ujawnić subtelniejsze wzorce związane z funkcjami korzeni.
Zapożyczając triki z języka i sieci
Hypergraph-Root zaczyna od opisania każdego białka w trzech uzupełniających się perspektywach. Wykorzystuje tradycyjne schematy punktowania sekwencji (BLOSUM62 i macierze punktów specyficznych dla pozycji), które uchwytują, jak aminokwasy zwykle się zastępują w toku ewolucji. Do tego dodaje trzeci, bardziej nowoczesny opis pochodzący z modelu języka białek o nazwie ProtT5 — oprogramowania wytrenowanego na milionach sekwencji białek, podobnie jak silnik predykcji tekstu jest trenowany na języku ludzkim. ProtT5 generuje bogate numeryczne „osadzenie” dla każdego aminokwasu, które koduje wskazówki strukturalne i funkcjonalne. Razem te trzy widoki dają szczegółowy odcisk palca każdego białka w badaniu.
Mapowanie złożonych powiązań wewnątrz białek
Aby wyjść poza proste porównania parowe, badacze przewidzieli, jak blisko są względem siebie aminokwasy w trójwymiarowej strukturze białka i wykorzystali te informacje do zbudowania hiper-grafu — sieci, w której jedno połączenie może łączyć więcej niż dwa aminokwasy jednocześnie. Specjalistyczna sieć neuronowa, hiper-graficzna sieć konwolucyjna, przetwarza tę strukturę świadomą topologii i dopracowuje odciski białek do cech wyższego poziomu. Moduł wielogłowicowej uwagi uczy się następnie, które części białka niosą najbardziej użyteczne sygnały do decyzji, czy jest ono związane z korzeniami. Na końcu standardowy klasyfikator przekształca te zdestylowane cechy w wynik prawdopodobieństwa: związane z korzeniami lub nie. W wielu przebiegach treningowych oraz na zestawach testowych zrównoważonych i niezrównoważonych, Hypergraph-Root osiągnął dokładności powyżej 83 procent i pole pod krzywą ROC (AUC) około 0,9, wyraźnie przewyższając wcześniejsze modele.
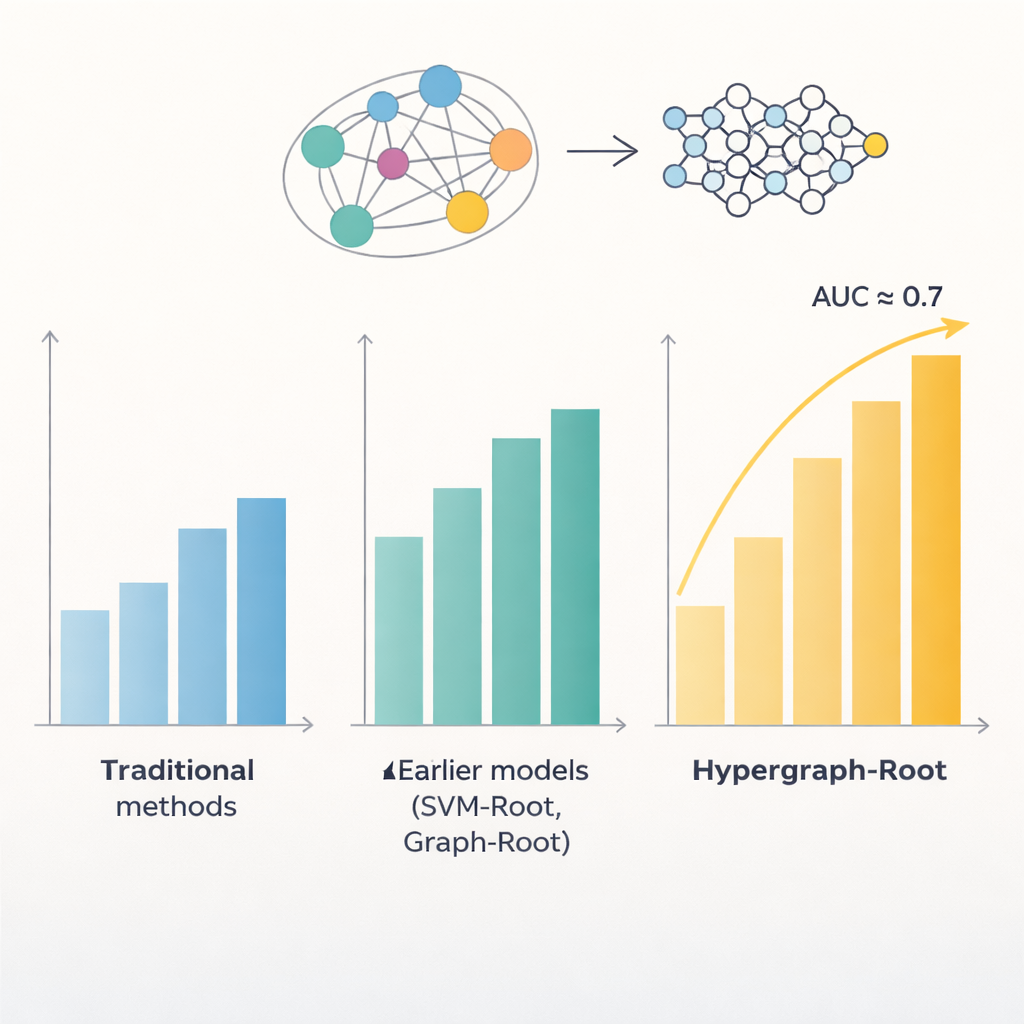
Co model ujawnia i dlaczego to ważne
Ponad surową dokładnością, model dostarczył wgląd w to, które informacje są najważniejsze. Cechy pochodzące z modelu języka ProtT5 wnosiły większy wkład niż tradycyjne cechy sekwencyjne i ewolucyjne, co sugeruje, że duże, wstępnie wytrenowane modele mogą uchwycić subtelne sygnały biologiczne, których starsze metody nie wyłapują. Komponent hiper-grafu również okazał się istotny: usunięcie go lub zastąpienie prostszym modelem grafowym obniżało wydajność. Gdy badacze zastosowali Hypergraph-Root do białek wcześniej nieoznaczonych jako związane z korzeniami, wyróżnił on garść kandydatów, których znane funkcje — takie jak transport przez błonę czy znakowanie białek w korzeniach — mocno sugerują, że pełnią role w biologii korzeni. Te kandydatury dają teraz eksperymentalnym biologom jasne listy priorytetów do przetestowania w laboratorium.
Od inteligentnych predykcji do silniejszych upraw
Mówiąc obrazowo, Hypergraph-Root jest jak ekspert-bibliotekarz biologii roślin: mając jedynie „litery” białka, ocenia, czy prawdopodobnie działa ono w korzeniach. Poprzez łączenie wglądów z modeli językowych, historii ewolucyjnej i złożonych relacji strukturalnych, znacznie poprawia to wcześniejsze narzędzia predykcyjne. Choć nie zastępuje eksperymentów, może zawęzić tysiące możliwości do kilku do sprawdzenia, oszczędzając czas i pieniądze. W dłuższej perspektywie takie modele mogą przyspieszyć odkrywanie białek związanych z korzeniami, które pomagają uprawom przetrwać upały, suszę czy złe gleby — ważny krok w kierunku bardziej odpornego rolnictwa w zmieniającym się klimacie.
Cytowanie: Chen, L., Xun, X. & Zhou, B. Root-associated protein prediction using a protein large language model and hypergraph convolutional networks. Sci Rep 16, 4876 (2026). https://doi.org/10.1038/s41598-026-35110-7
Słowa kluczowe: białka związane z korzeniami, bioinformatyka roślinna, uczenie głębokie, modele języka białek, odporność upraw