Clear Sky Science · pl
Wielomodalne uczenie i symulacja podejścia do percepcji w systemach autonomicznej jazdy
Inteligentniejsze samochody autonomiczne
Samochody autonomiczne obiecują bezpieczniejsze drogi i mniej korków, ale tylko jeśli rzeczywiście potrafią zrozumieć otaczający je świat. Artykuł opisuje nowe podejście, które pomaga pojazdom autonomicznym „widzieć”, „czuć” i „przewidywać” otoczenie bardziej jak rozważny ludzki kierowca — poprzez łączenie różnych sensorów, bezpieczne testy w wirtualnej kopii rzeczywistości oraz uczynienie decyzji samochodu bardziej przejrzystymi dla ludzi.
Postrzeganie drogi wieloma „zmysłami”
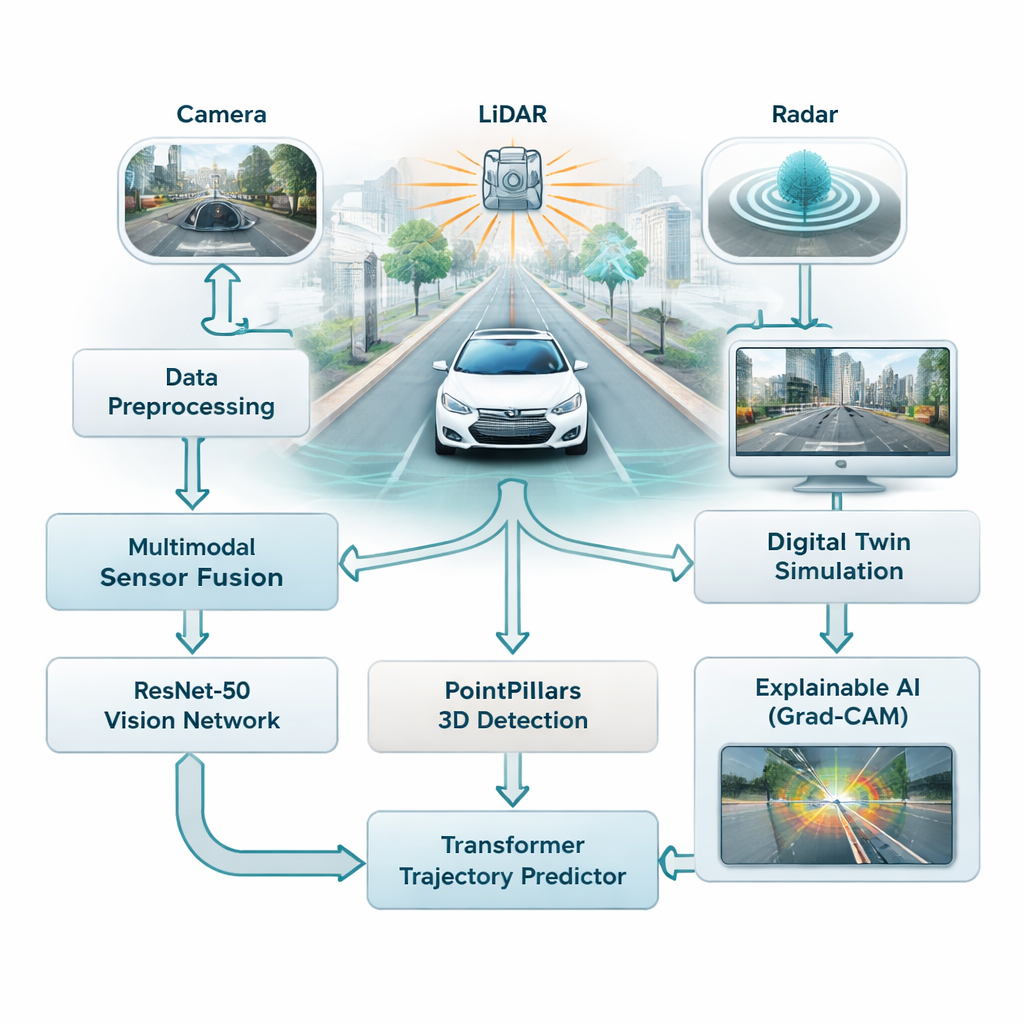
Większość współczesnych systemów wspomagania kierowcy opiera się w dużej mierze na kamerach, które dobrze działają przy dobrym oświetleniu, ale mają trudności we mgle, podczas deszczu czy w nocy. W badaniu połączono trzy różne rodzaje sensorów — kamery, skanery laserowe (LiDAR) i radar — aby pojazd nie polegał na jednym, podatnym źródle informacji. Kamery rejestrują bogate informacje o kolorze i szczegółach, LiDAR buduje precyzyjny obraz 3D sceny, a radar pozostaje niezawodny przy złej pogodzie. Autorzy łączą wszystkie trzy strumienie w jedną perspektywę ruchu drogowego, dając pojazdowi pełniejsze i bardziej wiarygodne rozumienie dróg, pieszych i innych samochodów.
Nauka rozpoznawania i przewidywania
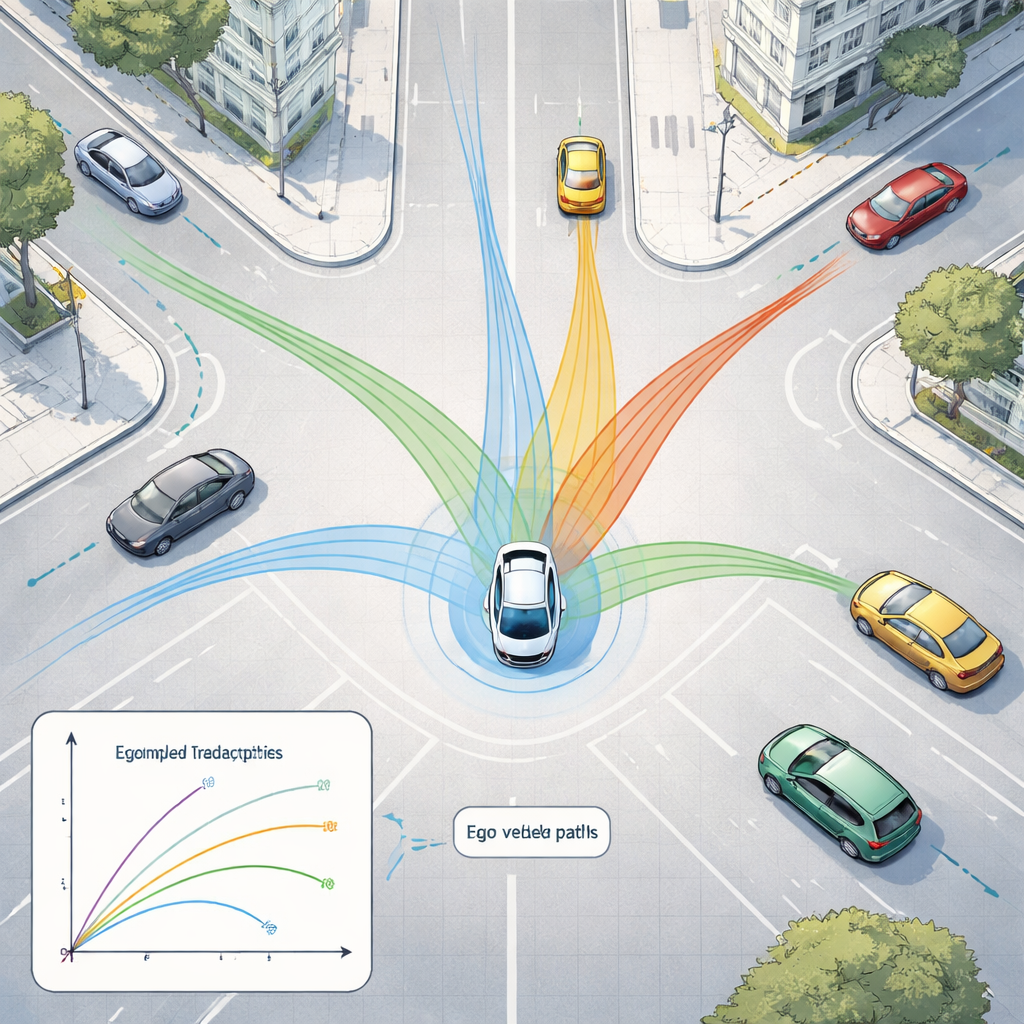
Aby sprostać temu napływowi danych, ramy wykorzystują dwie rodziny nowoczesnych modeli AI. Po pierwsze, głęboka sieć obrazu o nazwie ResNet-50 analizuje obrazy z kamer, by uchwycić ogólną sytuację — jak zatłoczona jest droga, gdzie są widoczne pasy i jak rozłożona jest scena. Równocześnie model 3D o nazwie PointPillars odczytuje chmury punktów LiDAR, by zlokalizować pojazdy i inne obiekty w trzech wymiarach. Sygnały te trafiają następnie do Transformera, typu AI pierwotnie zaprojektowanego dla języka, który świetnie radzi sobie z rozumieniem zmian w czasie. Tutaj uczy się przewidywać, jak pobliskie samochody i inne poruszające się obiekty prawdopodobnie będą się poruszać w ciągu najbliższych kilku sekund, biorąc pod uwagę zarówno ich wcześniejszy ruch, jak i strukturę drogi.
Budowanie bezpiecznego wirtualnego toru testowego
Zamiast testować ryzykowne sytuacje bezpośrednio na drogach publicznych, badacze podłączają swój system do cyfrowego bliźniaka — wirtualnej repliki rzeczywistych ulic miejskich opartej na dużym publicznym zbiorze danych z Bostonu i Singapuru. W tym zasymulowanym świecie sensory, ruch i otoczenie samochodu są odtwarzane i modyfikowane według potrzeb, podczas gdy AI próbuje śledzić obiekty i prognozować ich przyszłe trajektorie. System może uruchamiać takie scenariusze „co jeśli?” w czasie rzeczywistym, z czasami reakcji poniżej 50 milisekund, co pozwala inżynierom badać przypadki krawędziowe, takie jak nagłe hamowanie, ostre skręty czy zatłoczone skrzyżowania, bez narażania kogokolwiek na niebezpieczeństwo.
Zaglądanie do „czarnej skrzynki” AI
Częstą krytyką uczenia głębokiego jest to, że trudno zrozumieć, dlaczego model podjął określoną decyzję. Aby temu zaradzić, autorzy stosują metodę zwaną Grad-CAM, która podświetla fragmenty obrazu, które najbardziej wpłynęły na wyjście modelu. Te mapy cieplne pokazują na przykład, czy sieć skupia się na innym samochodzie, pieszym czy oznakowaniu pasa przy ocenie trajektorii. Chociaż ten etap wyjaśniania działa offline, a nie w pętli czasu rzeczywistego pojazdu, pomaga inżynierom i osobom oceniającym bezpieczeństwo zweryfikować, czy system zwraca uwagę na właściwe wskazówki, co jest kluczowe dla budowania zaufania społecznego.
O ile lepiej prowadzi?
Testowany na setkach scen miejskiej jazdy, proponowany framework wykrywa obiekty 3D dokładnie i przewiduje ruch precyzyjniej niż proste reguły fizyki zakładające stałą prędkość lub stałe przyspieszenie. Jego błędy prognoz — czyli jak bardzo przewidywane pozycje odbiegają od rzeczywistości — są znacząco mniejsze niż w przypadku takich bazowych metod i zbliżone do silnego rekurencyjnego modelu AI, przy jednoczesnym zachowaniu wystarczającej szybkości do użycia w czasie rzeczywistym. Dokładne eksperymenty porównujące różne konstrukcje sieci pokazują, że głębszy model obrazu i średniej głębokości detektor 3D zapewniają najlepszy kompromis między dokładnością a szybkością, a system można wdrożyć na mniejszych komputerach pokładowych po kompresji modelu.
Co to oznacza dla zwykłych kierowców
Dla niespecjalistów przesłanie jest takie, że bezpieczniejsze, bardziej niezawodne samochody autonomiczne najprawdopodobniej powstaną dzięki podejściu łączącemu wiele sensorów, przewidującemu, jak scena będzie się rozwijać, i gruntownie testowanemu w realistycznych wirtualnych światach. Łącząc percepcję, predykcję, symulację i zrozumiałe dla ludzi wyjaśnienia w jednym projekcie, ta praca przybliża pojazdy autonomiczne do zachowywania się jak ostrożni, przejrzyści partnerzy na drodze, a nie tajemnicze maszyny.
Cytowanie: Almadhor, A., Al Hejaili, A., Alsubai, S. et al. A multimodal learning and simulation approach for perception in autonomous driving systems. Sci Rep 16, 5505 (2026). https://doi.org/10.1038/s41598-026-35095-3
Słowa kluczowe: autonomiczna jazda, fuzja sensorów, predykcja trajektorii, detekcja obiektów 3D, symulacja cyfrowego bliźniaka